Dive into a collaborative space where members like YOU can exchange knowledge, tips, and best practices. Join the conversation today and unlock a wealth of collective wisdom to enhance your experience and drive success.
IntroductionCloud-native data platforms like Azure Databricks are powerful because they abstract away infrastructure so you can focus on data engineering, analytics, and ML workloads. However, there are situations where you may run into issues that r...
Databricks has added 2 new feature on its UI. These are small but quite effective for the developer productivity. 1. Paste images into notebooksCopy images from your local file system and paste them into markdown cells in Databricks notebookshttps:/...
IntroductionScaling data pipelines across an organization can be challenging, particularly when data sources, requirements, and transformation rules are always changing. A metadata table-driven framework using LakeFlow Declarative (Formerly DLT) enab...
can you please share the details how this can be implemented using a sample use case in step by step process. Also python code that needs to written in each layer (bronze/silver/gold)
Databricks + Claude Code This guide walks through a practical, end‑to‑end setup: installing Claude Code, wiring it to Anthropic models served from Databricks, and configuring authentication so everything “just works” from your terminal and editor. Yo...
Retirement is planned for Azure in Oct 2026. Completed in other clouds in Oct 2025Data residing in the Hive Metastore is opaque, suffers from low governance and is siloed in legacy technical constructs. The Hive Metastore (HMS) was a technology revol...
Databricks provides built-in AI functions that can be used directly in SQL or notebooks, without managing models or infrastructure.Example:SELECT ticket_id, ai_generate( 'Summarize this support ticket:\n{{text}}', 'databricks-dbrx-instruct', descript...
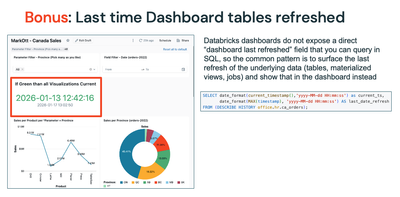
With AI/BI Dashboards, a best practice is for the creator/owner to 'Schedule' the Dashboard to rerun the underlying datasets when changes have occurred. This ensures the Visualizations are rendered with the freshest data. But users still will questi...
@mark_ott That is a nice idea and quite useful. Quick question: how did you define 'stale' data in your case? So what is the threshold at which your 'conditional equation' color codes the date red? did you somehow link that to the refresh schedule?
One thing becomes very clear when you spend time in the Databricks community: AI is no longer an experiment. It is already part of how real teams build, ship, and operate data systems at scale.For a long time, many organizations treated data engineer...
When Databricks One was launched, the default behaviour of the system-managed users group was a major issue. Since every new user is automatically added to users group, and that group traditionally came with "Workspace Access" entitlements, admins ha...
Here is a very short video on how to use collect() method with caution as it could overwhelm the cluster in some big data scenarios!!!! Now only in Spanish but I guess youtube will do the trick to translate into very correct English xDD
The Industrial Data ChallengeManufacturing enterprises today operate with a fundamental paradox: they're drowning in data yet starving for insights. A typical plant generates terabytes of information daily across dozens of systems—from shop floor PLC...
In this article, I’ll walk you through transforming a basic PySpark notebook into a production-ready data pipeline with comprehensive quality checks using Great Expectations patterns in Microsoft Fabric and Databricks. We’ll start simple and progress...
It is finally possible to deploy dashboards using DABS and change the catalog and schema. It is solving the biggest problem with bringing the dashboard to production. New parameters for the dashboard resource were added: dataset_catalog and dataset...
@Hubert-Dudek - This was really a much-awaited feature. Eventually DAB must cover all developed assets which requires promotion to higher environment to cover the CICD seamlessly.
We've all been there. You need to loop through a list of tables, apply some transformation, handle a few edge cases, and maybe catch an error or two. In most data platforms, that means switching to Python or Scala—even if 90% of your logic is just SQ...
As data platforms mature, the focus is no longer just scalability—it is about speed, simplicity, and cost efficiency. Engineering teams want to deliver insights faster without managing infrastructure, while organizations want predictable costs and st...