- 4328 Views
- 1 replies
- 2 kudos
Installing CrowdStrike Falcon Sensor on Databricks Workers
Greetings,Does anyone here have experience deploying the CrowdStrike Falcon sensor on Databricks worker instances? For context, the cluster is deployed in AWS and we use a Databricks Ubuntu 20.04 AMI. Databricks allows adding a bootstrap/startup scri...
- 4328 Views
- 1 replies
- 2 kudos
- 5354 Views
- 6 replies
- 1 kudos
Databricks App Availability
Hi there,I recently came across this post about databricks apps that says it available for public previewhttps://www.databricks.com/blog/introducing-databricks-appsHowever, when I go to previews in the workspace, I don't see an option to enable it, i...
- 5354 Views
- 6 replies
- 1 kudos
- 1 kudos
Yea same...I got the same warning "Requested region australiasoutheast in cloud azure is not supported."Has there been any further updates?
- 1 kudos
- 2821 Views
- 3 replies
- 1 kudos
Databricks Apps Crashes Unexpectedly Without Showing any Logs
Hi All,I coded up a Databricks app using fastapi which seems to be crashing on deployment. Databricks throws the error that "app crashed at startup" but the logging page is empty. So I do not know what went wrong. Any ideas on how to debug the proble...
- 2821 Views
- 3 replies
- 1 kudos
- 1 kudos
I want to update that I have been able to solve the problem and get the app running. The problem was related to trying to import from anoter folder instead of downloading the package using its wheel file. Just for the record, had already tried the l...
- 1 kudos
- 5378 Views
- 2 replies
- 3 kudos
Getting Started with Notebooks in Databricks
Databricks notebooks are a powerful tool for data scientists and engineers to collaborate, explore data, and build machine learning models. This guide will help you get started with creating and using notebooks in Databricks.Why Use Databricks Notebo...




- 5378 Views
- 2 replies
- 3 kudos
- 3 kudos
Thanks for sharing @bhanu_gautam. This will surely help beginners get started with Databricks Notebooks.
- 3 kudos
- 3237 Views
- 4 replies
- 4 kudos
Resolved! Unity Catalog Migration Strategy
Zero-Downtime Unity Catalog Migration for 500TB Data LakeJust completed migrating 500TB to Unity Catalog without a single minute of downtime. Here's how:The Challenge500 TB across 12,000 tables200+ concurrent usersZero tolerance for downtimeMixed Hiv...
- 3237 Views
- 4 replies
- 4 kudos
- 4 kudos
Thanks, @Khaja_Zaffer and @BS_THE_ANALYST!@Khaja_Zaffer:The toolkit has 5 main components:Pre-migration analyzer Compatibility scoringDrift monitor Real time consistency checksPermission migrator: Automated ACL copyingQuery rewriter: Hive→UC SQL con...
- 4 kudos
- 663 Views
- 0 replies
- 3 kudos
GetRunbook_Failed :: Bootstrap timeout - cluster failure during startup
After creating a new workspace, if you come across Failed to get instance bootstrap steps from the Databricks Control Plane. Please check that instances have connectivity to the Databricks Control Plane. Instance bootstrap inferred timeout reason: Ge...
- 663 Views
- 0 replies
- 3 kudos
- 8217 Views
- 17 replies
- 62 kudos
Level Up Your Databricks Game - Episode 1: Widgets
Hi all,TheOC here with my first of (hopefully!) many blogs on the Databricks Community. I'm hoping in this series to share quick, practical tips to help you get the most out of Databricks. Today's topic is: Widgets.If you're anything like me, you've ...




- 8217 Views
- 17 replies
- 62 kudos
- 62 kudos
hey @Rishabh_Tiwari,Thank you!Watch this space for the next instalment
- 62 kudos
- 2306 Views
- 4 replies
- 12 kudos
[Blog] Building a Scalable Telco CDR Processing Pipeline with Databricks Delta Live Tables - Part 1
Hey everyone! I wanted to share what I'm working with daily in the Databricks ecosystem and how amazing it is that we can achieve everything within one platform!Just published a deep dive on building a Telco CDR Processing Pipeline using: Delta Live ...
- 2306 Views
- 4 replies
- 12 kudos
- 12 kudos
@Pat here I was, cup of tea in hand, ready and eager to read the blog, only then did I discover I was redirected to another place that actually hosts the full blog .Personally, I think it'd be nice for it to be on here, especially if it's dedicated t...
- 12 kudos
- 1331 Views
- 0 replies
- 1 kudos
Technical Deep Dive
Bloom Filters + Zonemaps: The Ultimate Query Optimization ComboAfter my zonemap post last week got great feedback, several of you asked about Bloom filter integration. Here's the complete implementation!Why Bloom Filters Changed EverythingZonemaps ar...
- 1331 Views
- 0 replies
- 1 kudos
- 5367 Views
- 12 replies
- 7 kudos
Resolved! 🚀 DataFrame Caching on Delta Tables - What if underlying data is updated?
Just published new video on Databricks Performance Series to try to clearly explain how DataFrame caching over Delta Tables behaves when updates on underlying table are performed. I came across this use case in my recent project and struggled a littl...

- 5367 Views
- 12 replies
- 7 kudos
- 7 kudos
Source Code with samples available at https://github.com/CafeConData/Spark-Caching-on-Delta-Tables
- 7 kudos
- 2545 Views
- 0 replies
- 2 kudos
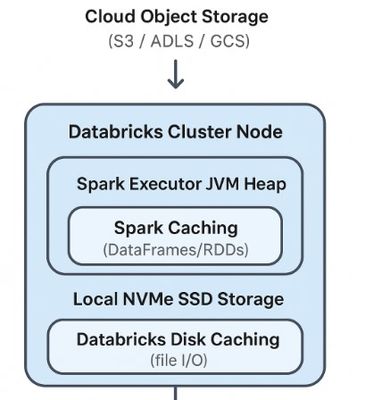
🚀 Spark Caching vs Databricks Disk Caching
As promised @BS_THE_ANALYST , in this new video and summarized in post, I try to explain what Spark Caching and Databricks Disk Caching are and how Caching strategy can be leveraged by making these cool features work together: Spark Caching vs Databr...

- 2545 Views
- 0 replies
- 2 kudos
- 1078 Views
- 0 replies
- 1 kudos
Parallel Model Training & Data Pipelines on Databricks (ForEach Tasks+ Asset Bundles + Pydantic)
As companies double down on machine learning (ML), one thing is obvious: a single model can’t solve every problem. Different datasets, different timelines, and different requirements make managing multiple models pretty tricky. And if you’ve ever wor...


- 1078 Views
- 0 replies
- 1 kudos
- 17601 Views
- 3 replies
- 7 kudos
Resolved! Data Quality with PySpark and Great Expectations on Databricks
Data governance is one of the most important pillars in any modern architecture. When building pipelines that process data at scale, ensuring data quality is not just a best practice—it is a critical necessity.Tools like Great Expectations (GX) were ...
- 17601 Views
- 3 replies
- 7 kudos
- 7 kudos
@WiliamRosaWiliamRosa: Thanks for sharing the link. I will explore.
- 7 kudos
- 4513 Views
- 0 replies
- 1 kudos
Tracking Query History and Optimizing Queries in Databricks
Optimizing queries in Databricks isn’t just about adding indexes or tweaking SQL syntax — it’s about visibility. You can’t improve what you can’t measure. Fortunately, Databricks provides rich telemetry around query history that you can use to analyz...
- 4513 Views
- 0 replies
- 1 kudos
- 4375 Views
- 1 replies
- 4 kudos
[Blog] Databricks Serverless vs Classic: Who Wins the Cost Sprint?
Hi everyone! I wanted to share with you a post I wrote on Medium a while ago — it’s still very useful if you want to understand how to properly calculate Databricks cluster costs and get a realistic view of the differences: Databricks Serverless vs C...
- 4375 Views
- 1 replies
- 4 kudos
- 4 kudos
Really interesting topic I'll take a look when possible Always interested in improving performance and saving cloud costs. Thanks for sharing.
- 4 kudos
-
Access Data
1 -
Access Delta Tables
1 -
ADF Linked Service
1 -
ADF Pipeline
1 -
Advanced Data Engineering
6 -
agent bricks
2 -
Agent Skills
1 -
Agentic AI
3 -
AI
2 -
AI Agents
5 -
AI Readiness
1 -
AIBI
1 -
Analytics
1 -
Analytics Engineering
1 -
Apache spark
3 -
Apache Spark 3.0
2 -
ApacheSpark
1 -
Aqe
1 -
Architecture
5 -
Associate Certification
2 -
Audit
1 -
Auto-loader
1 -
Automation
1 -
AWSDatabricksCluster
2 -
Azure
3 -
Azure databricks
3 -
Azure Databricks Delta Table
3 -
Azure Databricks Job
2 -
Azure Delta Lake
3 -
Azure devops integration
1 -
Azure Unity Catalog
2 -
AzureDatabricks
2 -
BI Integrations
1 -
Big data
1 -
Billing and Cost Management
2 -
Blog
1 -
BroadcastJoin
1 -
Bronze Layer
1 -
Bronze Table
1 -
Caching
2 -
CDC
3 -
CDF
1 -
Certification
1 -
Certification Badge
1 -
Certification Exam
1 -
CICD
2 -
CICDForDatabricksWorkflows
1 -
Cluster
1 -
Cluster Policies
1 -
Cluster Pools
1 -
Collect
1 -
Community Event
1 -
CommunityArticle
2 -
Cost Optimization Effort
2 -
CostOptimization
3 -
custom compute policy
1 -
CustomLibrary
1 -
DABs
2 -
DAIS 0206
3 -
DAIS 2026
2 -
Dashboards
2 -
Data
1 -
Data Analysis with Databricks
1 -
Data Architecture
2 -
Data Driven AI Roadmap
1 -
Data Engineering
17 -
Data Governance
5 -
Data Ingestion
2 -
Data Ingestion & connectivity
1 -
data layout
1 -
Data Mesh
1 -
data optimization
1 -
Data Processing
1 -
Data Quality
3 -
Data warehouse
1 -
Data Warehousing
1 -
databricks
3 -
Databricks App
1 -
Databricks Apps
2 -
Databricks Assistant
2 -
Databricks Certified
1 -
Databricks Community
1 -
Databricks Dashboard
2 -
Databricks Delta Table
3 -
Databricks Demo Center
1 -
Databricks genAI associate
1 -
Databricks Job
2 -
Databricks Lakeflow
3 -
Databricks Lakehouse
2 -
Databricks Migration
3 -
Databricks Mlflow
1 -
Databricks News
1 -
Databricks Notebooks
1 -
Databricks Partner
1 -
Databricks Pyspark
3 -
Databricks Serverless
1 -
Databricks Support
1 -
Databricks Training
1 -
Databricks Unity Catalog
3 -
Databricks Workflows
3 -
DatabricksAutomation
1 -
DatabricksML
1 -
DatabricksOptimization
1 -
DataEngineering
1 -
DBR Versions
1 -
Declartive Pipelines
2 -
DeepLearning
1 -
Delta Lake
12 -
Delta Lake Files
1 -
Delta Live Table
3 -
Delta Live Tables
1 -
Delta Time Travel
1 -
Delta-lake
1 -
DeltaLake
1 -
DevOps
2 -
DimensionTables
1 -
DLT
3 -
DLT Pipeline
1 -
DLT Pipelines
3 -
DLT-Meta
1 -
Dns
1 -
Dynamic
1 -
Dynamic Partition
1 -
ETL Pipelines
2 -
fastapi
1 -
Forecasting
1 -
Free Databricks
3 -
Free Edition
1 -
GenAI
1 -
GenAI agent
2 -
GenAI and LLMs
4 -
GenAIGeneration AI
2 -
Generation AI
1 -
Generative AI
2 -
Generative AI Engineer
1 -
Genie
2 -
Git
1 -
GoldLayer
1 -
Google Bigquery
1 -
Google cloud
1 -
Governance
2 -
Governed Tag
1 -
hackathon
1 -
Hive metastore
1 -
Hubert Dudek
42 -
Hybrid Lakehouse
1 -
Kafka streaming
2 -
LakeBase
4 -
Lakeflow
1 -
Lakeflow Pipelines
2 -
Lakehouse
3 -
Lakehouse Migration
1 -
Langchain
1 -
LangGraph
1 -
Lazy Evaluation
1 -
Learning
1 -
Library Installation
1 -
Lineage
2 -
LiquidClustering
2 -
Live Tables CDC
1 -
Llama
1 -
LLM
1 -
LLMs
1 -
Machine Learning
2 -
mcp
2 -
Medallion Architecture
4 -
MERGE Performance
2 -
Metadata
2 -
Metric Views
2 -
Migration
1 -
Migrations
1 -
mosic ai search
1 -
MSExcel
3 -
Multi-Table Transactions
1 -
Multiagent
3 -
Networking
2 -
New Features
1 -
NotMvpArticle
1 -
Optimization
1 -
Optimize Command
1 -
Partitioning
3 -
Partner
1 -
Performance
2 -
Performance Tuning
3 -
PII
1 -
Powerbi
1 -
PredictiveOptimization
1 -
Private Link
1 -
Pyspark
7 -
Pyspark Code
1 -
Pyspark Databricks
1 -
Pytest
1 -
Python
1 -
Reading-excel
2 -
Row Level Security
1 -
SAP
2 -
Sap Hana Driver
1 -
Scala Code
1 -
Scd Type 2
1 -
Scripting
1 -
SDK
1 -
Security
1 -
Semantic Layer
1 -
Serverless
2 -
Spark
6 -
Spark Caching
1 -
Spark Performance
1 -
SparkSQL
1 -
SQL
3 -
Sql Scripts
2 -
SQL Serverless
1 -
streaming
1 -
streamlit
1 -
Structured streaming
1 -
Students
2 -
Support Ticket
1 -
Sync
1 -
Training
1 -
Tutorial
3 -
UCSD
1 -
Unit Test
1 -
Unit testing
1 -
Unity Catalog
13 -
Unity Cataloge
1 -
Unity Catlog
1 -
University Alliance
1 -
VACUUM Command
1 -
Variant
1 -
Warehousing
1 -
Workflow Jobs
1 -
Workflows
9 -
Zerobus
2 -
Zorder
1 -
Zordering
2
- « Previous
- Next »
| User | Count |
|---|---|
| 85 | |
| 75 | |
| 72 | |
| 60 | |
| 42 |