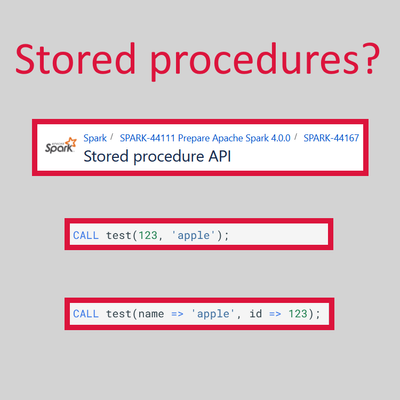
Dive into a collaborative space where members like YOU can exchange knowledge, tips, and best practices. Join the conversation today and unlock a wealth of collective wisdom to enhance your experience and drive success.
Hi Everyone,We built Gradient, a tool to automatically optimize and monitor Databricks jobs to hit your business objectives of cost or runtime.Gradient works by applying a reinforcement ML model to automatically learn and custom tune your jobs cluste...
Hi Folks -We released a new metrics view for databricks jobs in Gradient, which helps track and plot the metrics below over time to help engineers understand what's going on with their jobs over time.Job cost (DBU + Cloud fees)Job RuntimeNumber of co...
Hi @Sujitha Just to follow up on your suggestion to share my takeaways from Jonathan Frankel's talk at Sigma in NYC. The key ideas I came away with is:Building in-house custom models is more than just possible, there's advantages to itThere's danger...
Today Databricks announced the release of the Databricks AI Security Framework (LinkedIn Post)You can download the paper (PDF) from blog post. Anyone else download this and have thoughts? My first thought is its a great start and has an excellent G...
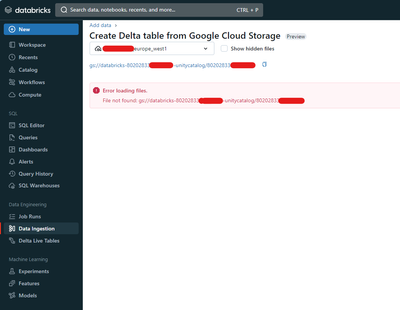
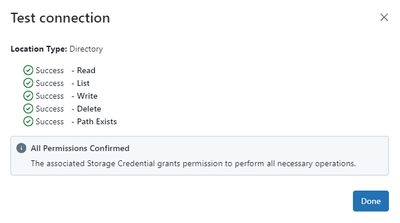
When creating a new Workspace in GCP the default GCP External Location is wrong.Its easily fixed by Catalog (on the left) > External Data (on the bottom) > External Locations > choose the connection and edit the URL by deleting the second BucketId af...
I created this article in Linkedlin to allow both this community and Apache Spark user community to have access to it.It is particularly useful for data engineers who want to have a basic understanding of what Generative AI with Spark can do.Leverag...
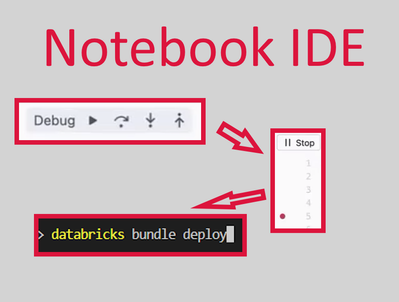
This is an excellent step for #databricks notebooks. Integrated debugger and CLI in notebook terminal is a big step towards a fully functional cloud IDE.
IntroductionFinancial fraud is a significant concern for businesses and consumers alike. I have written about this concern a few times in Linkedlin articles. Machine learning offers powerful tools to combat this issue by automatically identifying sus...
Looking to build a machine learning model for detecting fraudulent transactions using PySpark’s MLlib. Generate synthetic transaction data. Provides a dataset for model training without using sensitive real-world data. Enables the creation of diverse...
if you have thought about making your code inside databricks and notebooks more reusable and organized and you have thought about implementing a design pattern or class level separation in databricks the answer is yes, I am going to tell you the deta...
tnx! I have spent quite some time on figuring out what the best way is. Your approach is certainly a valid one.Myself I prefer to package reused classes in a jar (we mainly code in scala). Works fine too.
I recently saw an article from Databricks titled "Scalable Spark Structured Streaming for REST API Destinations". A great article focusing on continuous Spark Structured Streaming (SSS). About a year old. I then decided, given customer demands to wo...
Hi everyone!
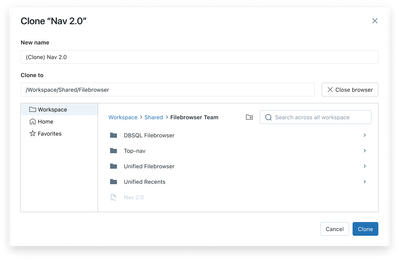
We are redesigning the Move File and Clone File experiences. We want to make it as seamless as possible to organize your files, and would love your feedback on the designs!
Move File:
Move Option 1
Move Option 2:
Clone File:
Cl...
Based on my experience with data partitioning, it often diminishes performance rather than enhancing it. There are exceptions, like when handling tables over 1TB, or when EVERY single query utilizes partition in the WHERE clause - for instance, a Pow...