Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Any on please suggest how we can effectively loop ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Any on please suggest how we can effectively loop through PySpark Dataframe .
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 04:59 AM
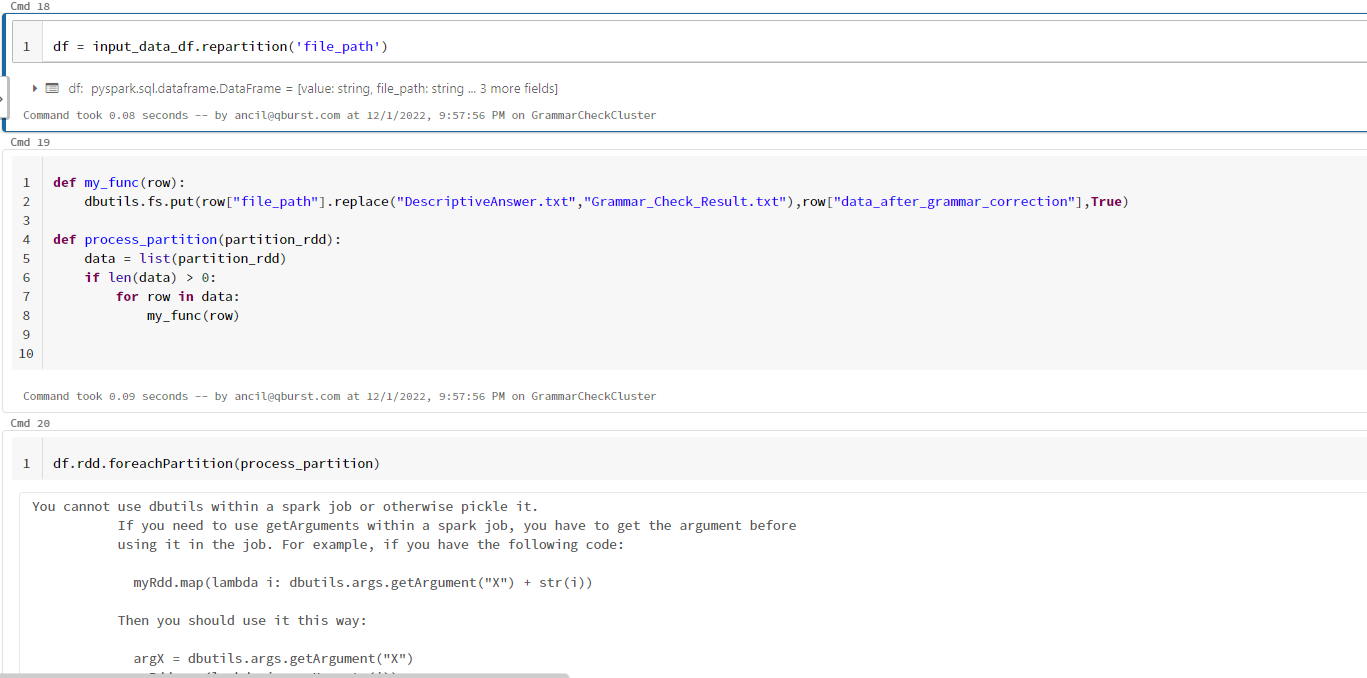
Scenario: I Have a dataframe with more than 1000 rows, each row having a file path and result data column. I need to loop through each row and write files to the file path, with data from the result column.
what is the easiest and time effective way to do this?
I tried with collect and it's taking long time.
And I tried UDF methods but getting below error

Labels:
- Labels:
-
Loop


11 REPLIES 11
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:06 AM
Hi @Ancil P A
Is your data in the result column a json value or how is it ?
From your question, I understood that you have two columns in your df, 1 column is the file path and the other column is data.
Also please post what udf you are trying to build so that if your approach is useful, fix can be done on that.
Cheers..
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:25 AM
Hi @Uma Maheswara Rao Desula
In the result column have result json data , but column type is string.
Please find below screen shot for UDF

input_data_df = input_data_df.withColumn("is_file_created",write_files_udf(col("file_path"),col("data_after_grammar_correction")))

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:06 AM
Is it an option to write is as a single parquet file, but partitioned?
Like that physically the paths of the partitions are different, but they all belong to the same parquet file.
The key is to avoid loops.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:28 AM
Hi @Werner Stinckens
My use case is to write text files with how many rows in dataframe.
For example, if I have 100 rows, then I need to write 100 files in the specified location.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:37 AM
yes exactly, that is what partitioning does.
all you need is a common path where you will write all those files, and partition on the part that is not common.
f.e.
/path/to/file1|<data>
/path/to/file2|<data>
the common part(/path/to), you use as target location.
The changing part (file1, file2) you use as partition column
so it will become:
df.write.partitionBy(<fileCol>).parquet(<commonPath>)
Spark will write a file (or even more than 1) per partition.
If you want only one single file you also have to repartition by filecol.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:44 AM
Hi @Werner Stinckens
In my case there is no common path, the file path column has different paths in a storage container.
Do we have any other way
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:51 AM
afaik partitioning is the only way to write to multiple locations in parallel.
This SO thread perhaps has a way.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 06:02 AM
Thanks a lot, let me check
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 08:36 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 07:28 PM
Hi,
I agree with Werners, try to avoid loop with Pyspark Dataframe.
If your dataframe is small, as you said, only about 1000 rows, you may consider to use Pandas.
Thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 08:34 PM
Hi @Nhat Hoang
The size may vary it may be up to 1 lakh, I will check with pandas
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- foreachPartition in Data Engineering
- OversizedAllocationException with transformWithStateInPandas in Data Engineering
- Observable API and Delta Table merge in Data Engineering
- optimizing my databricks code in Data Engineering
- Reading data from Serverless Warehouse from Azure Functions in Python - using managed identities in Data Engineering