Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Autoloader failed
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-19-2021 11:00 PM
I used autoloader with TriggerOnce = true and ran it for weeks with schedule. Today it broke:
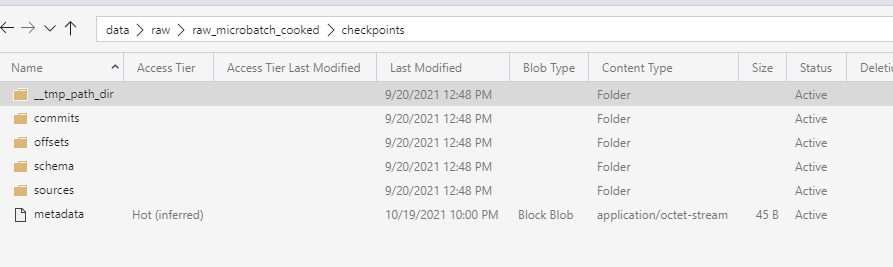
The metadata file in the streaming source checkpoint directory is missing. This metadata
file contains important default options for the stream, so the stream cannot be restarted
right now. Please contact Databricks support for assistance.
StreamingQueryException:
---------------------------------------------------------------------------
StreamingQueryException Traceback (most recent call last)
<command-1866658421247823> in <module>
1 #Waiting end of autoloader
----> 2 autoloader_query.awaitTermination()
3
4 #Show the output from the autoloader job
5 autoloader_query.recentProgress
/databricks/spark/python/pyspark/sql/streaming.py in awaitTermination(self, timeout)
99 return self._jsq.awaitTermination(int(timeout * 1000))
100 else:
--> 101 return self._jsq.awaitTermination()
102
103 @property
/databricks/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
121 # Hide where the exception came from that shows a non-Pythonic
122 # JVM exception message.
--> 123 raise converted from None
124 else:
125 raise
StreamingQueryException:
The metadata file in the streaming source checkpoint directory is missing. This metadata
file contains important default options for the stream, so the stream cannot be restarted
right now. Please contact Databricks support for assistance.
=== Streaming Query ===
Identifier: [id = 0416c163-a2de-4f6d-82f7-189a0e7bb39e, runId = 5b7a00bb-3c27-4f04-bfd7-bce8d36bf225]
Current Committed Offsets: {CloudFilesSource[wasbs://data@<MY STORAGE>.blob.core.windows.net/*/*/*/*/]: {"seqNum":18550,"sourceVersion":1,"lastBackfillStartTimeMs":1632167318876,"lastBackfillFinishTimeMs":1632167323294}}
Current Available Offsets: {CloudFilesSource[wasbs://bidata@colllectorprotostorage.blob.core.windows.net/*/*/*/*/]: {"seqNum":18560,"sourceVersion":1,"lastBackfillStartTimeMs":1632167318876,"lastBackfillFinishTimeMs":1632167323294}}
Current State: ACTIVE
Thread State: RUNNABLE
Labels:
- Labels:
-
Autoloader
-
Azure databricks
-
Jvm
-
Metadata File
-
Show


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 02:24 AM
.option("checkpointLocation", "dbfs://checkpointPath")
In future you can specify location by yourself (using above option) to have better control on it. I bet that checkpoint was on source directory and somehow it was corrupted or deleted.
My blog: https://databrickster.medium.com/
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 02:24 AM
.option("checkpointLocation", "dbfs://checkpointPath")
In future you can specify location by yourself (using above option) to have better control on it. I bet that checkpoint was on source directory and somehow it was corrupted or deleted.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 08:56 AM
I have this:
checkpoint_path = target_path + "checkpoints/"
autoloader_query = (raw_df.writeStream
.format("delta")
.trigger(once=True)
.option("checkpointLocation",checkpoint_path)
.partitionBy("p_ingest_date_utc","p_ingest_hour_utc")
.table("raw_cooked")
)So I have it. And it was working long time.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 12:41 PM
Hi dimoobraznii (Customer)
This error comes in streaming when someone makes changes to the streaming checkpoint directory manually or points some streaming type to the checkpoint of some other streaming type. Please check if any changes were made to the checkpoint just before the error run.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 12:43 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2021 08:14 AM
@dimoobraznii (Customer) I think the Azure storage team could help to identify the changes made on the metadata file. You could check this with them
Announcements





{kind=link}
Related Content
- Official databricks-openai package fails to import after resolving databricks-vectorsearch in Generative AI
- Best practice to log Autoloader UNKNOWN_FIELD_EXCEPTION in Data Engineering
- My experience replacing a Postgres → Kafka → DMS → S3 pipeline with Lakeflow Connect in Data Engineering
- From RAG Demo to Production on Databricks: 7 Things Teams Should Validate First in Data Engineering
- system.ai.python_exec suddenly failing with UNRESOLVED_ROUTINE on Azure (West US) since May 27 ~4pm in Data Governance