Hi All,
I am getting data from Event Hub capture in Avro format and using Auto Loader to process it.
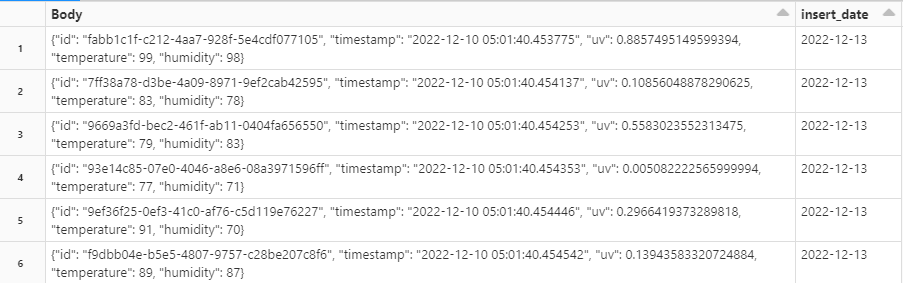
I get into the point where I can read the Avro by casting the Body into a string.
 Now I wanted to deserialized the Body column so it will in table format. Managed to do this by constructing a json_schema using StructType() and used the json_schema within the from_json() function which then I do a writeStream into a delta table.
Now I wanted to deserialized the Body column so it will in table format. Managed to do this by constructing a json_schema using StructType() and used the json_schema within the from_json() function which then I do a writeStream into a delta table.

Question. Is there a way that I can deserialize the Avro data without constructing a schema? Event Hub schema registry is one option that I am looking at but not sure how to do that within Autoloader using PySpark.
Cheers,
Gil








{kind=link}
{kind=link}
{kind=link}