Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Delta merge file size control
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Delta merge file size control
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-04-2021 03:23 PM
Hello community!
I have a rather weird issue where a delta merge is writing very big files (~1GB) that slow down my pipeline. Here is some context:
I have a dataframe containg updates for several dates in the past. Current and last day contain the vast amount of rows (>95%) and the rest are distributed in older days (around 100 other unique dates). My target dataframe is partitioned by date.
The issue I have is that when the merge operation is writing files I end up writing 2-3 files on the largest date partition, resulting to 2-3 files of around 1GB. Thus my whole pipeline is blocked by the write of these files that takes much longer than the other ones.
I have played with all the evident configurations such as:
delta.tuneFileSizesForRewrites
delta.targetFileSize
delta.merge.enableLowShuffle
everything seems to be ignored and the files remain at this scale.
note: running on DBR 10.0 / delta.optimizedWrites.enabled set to true
Is there anything that I am missing?
Thank you in advance!
Labels:
- Labels:
-
Big Files


6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-05-2021 01:56 AM
Maybe the table size is +10TB?
If you use the autotune, delta lake uses a file size based on the table size:
However, the targetfilesize should disable the autotune... weird.
I use the following settings (which create files around 256MB):
spark.sql("set spark.databricks.delta.autoCompact.enabled = true")
spark.sql("set spark.databricks.delta.optimizeWrite.enabled = true")
spark.sql("set spark.databricks.delta.merge.enableLowShuffle = true")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-05-2021 07:24 AM
Delta is transactional file (keeping incremental changes in jsons and snapshots in parquet) usually when I want performance I prefer just use parquet.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2021 11:37 AM
@Pantelis Maroudis , can you try setting spark.databricks.delta.optimize.maxFileSize?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-12-2021 05:21 AM
Hello,
Took some more time investigating and trying @Sandeep Chandran idea.
I ran 4 different configurations. I have cached the update table and each time I was running a restore on the target table so the data we merge are identical.
Here are the files produced by each run on my BIGGEST partition which is the one blocking the stage:

spark.databricks.delta.tuneFileSizesForRewrites: false
I suppose it uses file tuning on table size
run2:
spark.databricks.delta.tuneFileSizesForRewrites: false
spark.databricks.delta.optimize.maxFileSize: 268435456
run3:
spark.databricks.delta.tuneFileSizesForRewrites: false
delta.targetFileSize = 268435456 property on target table
run4:
spark.databricks.delta.tuneFileSizesForRewrites: true
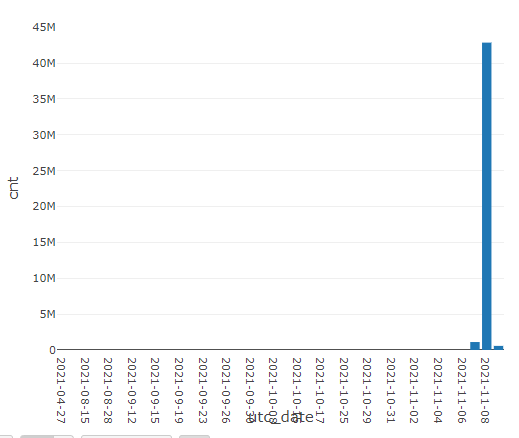
As an extra info here is the records per partition,. As you see my dataframe is highly unbalanced.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2021 05:20 PM
Hi @Pantelis Maroudis ,
Are you still looking for help to solve this issue?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-09-2021 10:52 AM
Hello Jose,
I just went with splitting the merge in 2 so I have a merge that touches many partitions but few rows per file and a second that touches 2-3 partitions but contain the build of the data.
Announcements




![Community [Industry BrickTalk #4] Transforming Commercial Real Estate Portfolio Management with AI](/t5/image/serverpage/image-id/25529iFB6AFAFAE433451D/image-size/large?v=v2&px=999)
{kind=link}
{kind=link}
Related Content
- Inquiring whether table triggers are the recommended tool for the job in Data Engineering
- DLT with CDC and schema changes in streaming pipelines in Data Engineering
- NULL rows getting inserted in delta table- Schema mismatch in Data Engineering
- matching sas proc survey means for quantiles in databricks in Data Engineering
- Observable API and Delta Table merge in Data Engineering