Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- DLT and Modularity (best practices?)
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
DLT and Modularity (best practices?)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-17-2022 12:57 PM
I have [very] recently started using DLT for the first time. One of the challenges I have run into is how to include other "modules" within my pipelines. I missed the documentation where magic commands (with the exception of %pip) are ignored and was unpleasantly surprised when running the workflow for the first time.
What is the best practice for including common modules within workflows?
In my particular case, what I would like to do is create a separate module that can dynamically generate a dict of expectations given a specific table... and I definitely do not want to include this is all of my notebooks (DRY). Any ideas/suggestions/best-pratices for a newbie on how to accomplish this?
Thanks for the help and guidance!
Labels:
- Labels:
-
Delta Live Tables
-
DLT
-
Expectations
-
Note
-
Workflows


9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-11-2022 12:46 AM
Hello @Jeremy Colson Thank you for reaching out to Databricks Community Forum.
Could you please give this a try if you already have a Repos linked in the workspace?
I think Engineering is working on some improvements on this front.
https://docs.databricks.com/repos/index.html

Below code snippet shows a simple example. You can implement your own logic and try to import it in the DLT pipeline.
import sys
import pprint
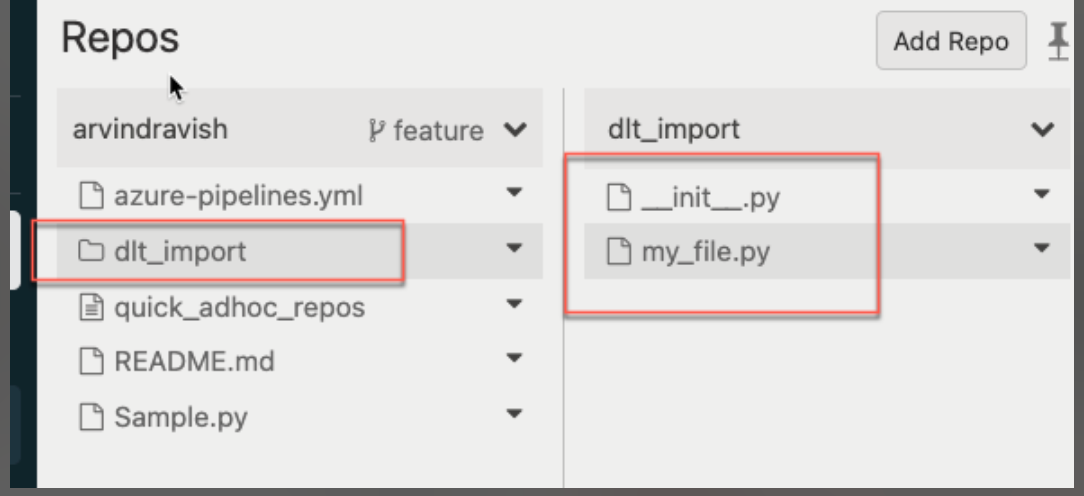
sys.path.append("/Workspace/Repos/arvind.ravish@databricks.com/arvindravish/dlt_import")
from my_file import myClass
newClass = myClass(5)
val = newClass.getVal()
print(val * 5)
Please provide your feedback so we can add any improvements to our product backlog.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 08:35 AM



Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 08:42 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2023 08:17 AM
Hi @Greg Galloway ,
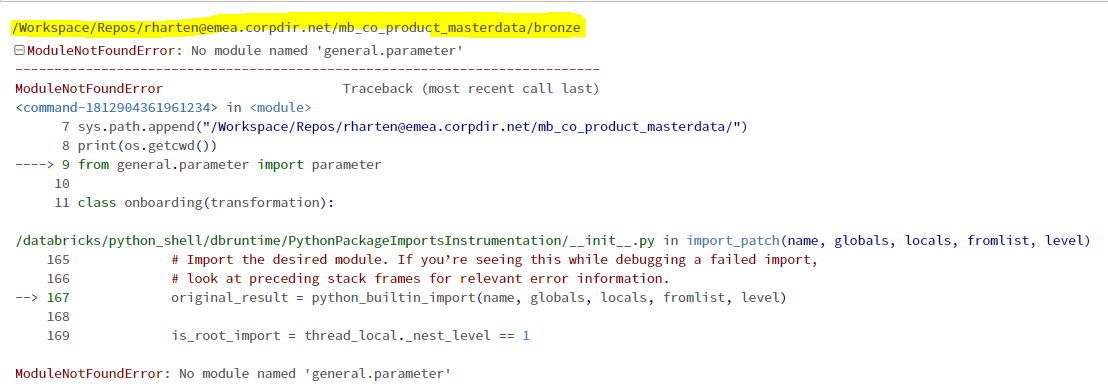
thank you very much for your reply. I did according to your suggestion but now I face another error when executing the pipeline.
Can you please advice?
Best regards
Ruben
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2023 10:15 AM
@Ruben Hartenstein I don't see any @dlt.table mentions in your code. I'm assuming that error means the pipeline evaluated your code and didn't find any DLT tables in it. Maybe study a few of the samples as a template?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2023 12:01 AM
@Greg Galloway
Is there no way to run the pipeline without @dlt?
I just want to use hive tables in my coding.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2023 06:49 AM
If you don't want any Delta Live Tables, then just use the Jobs tab under the Workflows tab. Or there are plenty of other ways of just running a notebook in whatever orchestration tool you use (e.g. Azure Data Factory, etc.) @Ruben Hartenstein
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2022 11:14 AM
I like the approach @Arvind Ravish shared since you can't currently use %run in DLT pipelines. However, it took a little testing to be clear on how exactly to make it work.
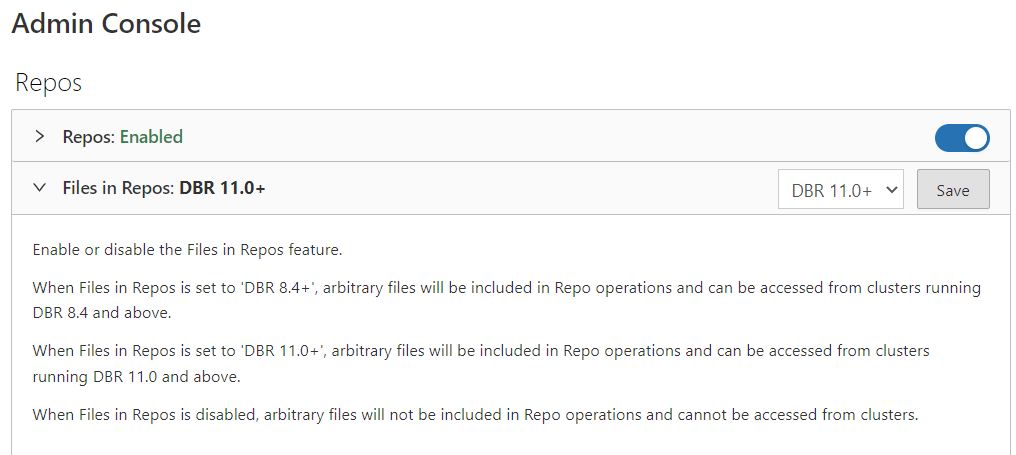
First, ensure in the Admin Console that the repos feature is configured as follows:


MYVAR1 = "hi"
MYVAR2 = 99
MYVAR3 = "hello"
def factorial(num):
fact=1
for i in range(1,num+1):
fact = fact*i
return factIn the DLT notebook, the following code loads Import.py and executes the Python code in it. Then MYVAR1, MYVAR2, MYVAR3, and the factorial function will be available for reference downstream in the pipeline.
import pyspark.sql.functions as f
txt = spark.read.text("file:/Workspace/Repos/FolderName/RepoName/Import.py")
#concatenate all lines of the file into a single string
singlerow = txt.agg(f.concat_ws("\r\n", f.collect_list(txt.value)))
data = "\r\n".join(singlerow.collect()[0])
#execute that string of python
exec(data)This appears to work in both Current and Preview channel DLT pipelines at the moment.
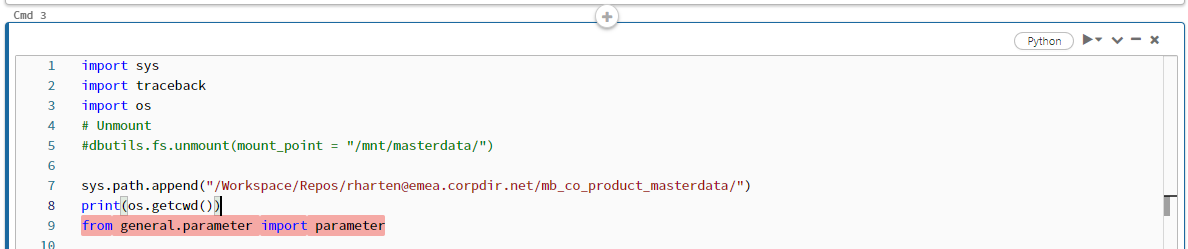
Unfortunately, the os.getcwd() command doesn't appear to be working in DLT pipelines (as it returns /databricks/driver even when the DLT pipeline notebook is in a Repo) so I haven't figured out a way to use a relative path even if your calling notebook is also in Repos. The following currently fails and Azure support case 2211240040000106 has been opened:
import os
import pyspark.sql.functions as f
txt = spark.read.text(f"file:{os.getcwd()}/Import.py")
#concatenate all lines of the file into a single string
singlerow = txt.agg(f.concat_ws("\r\n", f.collect_list(txt.value)))
data = "\r\n".join(singlerow.collect()[0])
#execute that string of python
exec(data)I'm also having trouble using the import example from aravish without using a hardcoded path like sys.path.append("/Workspace/Repos/TopFolder/RepoName") when running in a DLT pipeline. The aravish approach is useful if you want to import function definitions but not execute any Python code and not define any variables which will be visible in the calling notebook's Spark session.
Note: Edited from a previous post where I made a few mistakes.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:14 PM
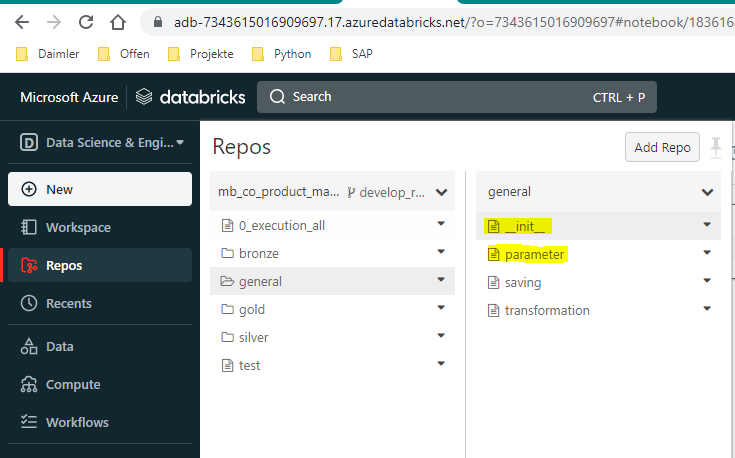
What my setup looks like is two workspaces, one dev, one prod. The repos folder where dlt pipelines run from is called dev in dev and prod in prod. I use secret scopes to retrieve the appropriate text to be able to path to the correct environments sys.path.append(some/path/to/my.py) so I can from my.py import method/class.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Generative AI Development: What Does It Take to Move from PoC to Production? in Generative AI
- Guidance Needed on Publishing a Databricks App to the Databricks Marketplace in Administration & Architecture
- DAB best practices suggestion in Data Engineering
- Bundle deployment overwrites artifacts while jobs are running - best practices? in Data Engineering
- Data Dictionary and Unity Catalog: Best Practices in a Medallion Architecture in Data Governance