Hi,
I followed the tutorial here: https://docs.databricks.com/en/delta-live-tables/cdc.html#how-is-cdc-implemented-with-delta-live-tab...
The only change I did is that data is not appended to a table but is read from a parquet file. In practice this means:
Original:
@dlt.view
def users():
return spark.readStream.format("delta").table("cdc_data.users")My code
@dlt.view
def vcp_analyte_source():
return (
spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "parquet") \
.option("cloudFiles.schemaEvolutionMode", "none") \
.schema(vcp_analytes_schema) \
.load(vcp_analytes_data_path)
)
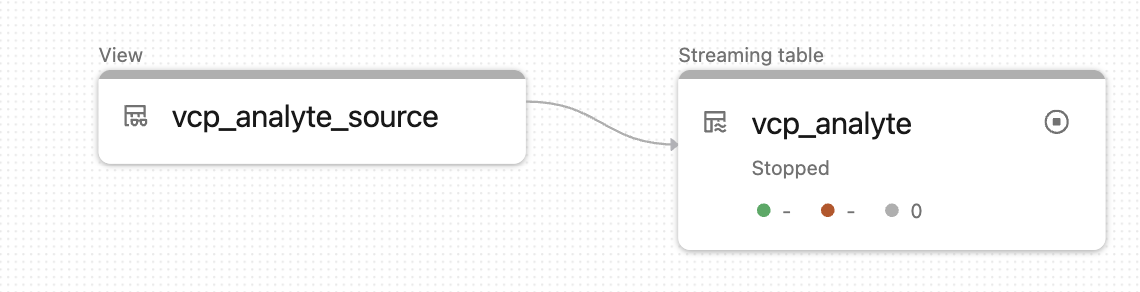
This works, the hidden "_apply_changes_storage_" table is filled with data from the parquet files and the resulting "gold" view gives expected number of records.
However, when I go to the delta live tables dashboard where the streaming tables are rendered (see attached file), the number of "upserted" and "deleted" records is not available even though 2000 records have been ingested.
Is that a "feature" of working with parquet files, known bug or something I have to enable elsewhere? If this is how it is, is there anywhere else to look for good record ingestion performance statistics?
Thank you!







{kind=link}