Hi Everyone,
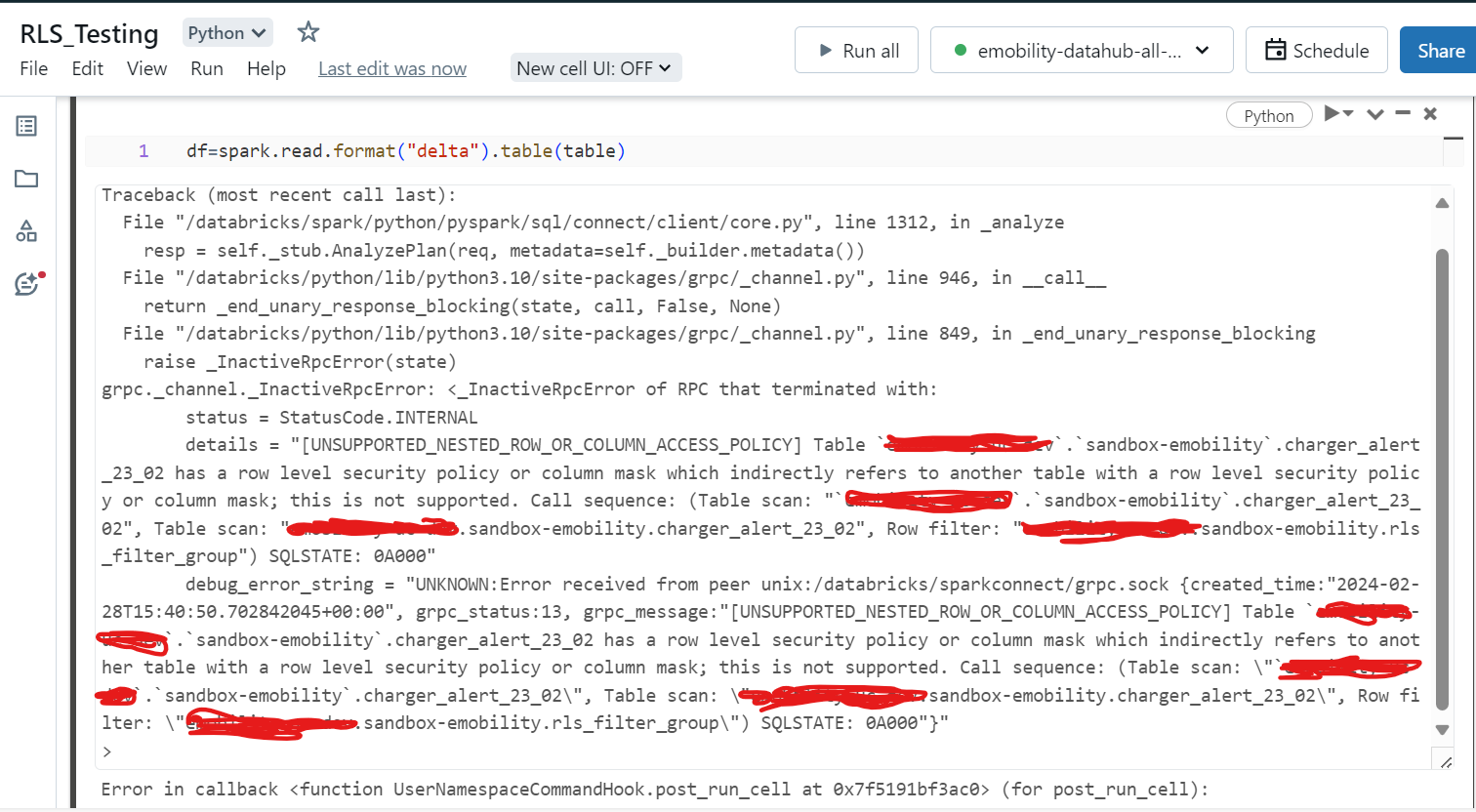
We are trying to implement Row Level Security In Delta Table and done testing (i.e. sql execution api,sql editor,sql notebook) using Sql Serverless in Unity Catalog.
But when tried to access the table having RLS in Notebook using Pyspark with all purpose shared cluster, it is throwing error. Tried with Single User as well, as restriction is there, failing as expected. Our multiple workflows running using pyspark notebooks accessing the table.
Does anyone know how to access the table with RLS using All Purpose Cluster. Databricks runtime is 14.3 LTS.
Any help is much appreciated.







{kind=link}
{kind=link}