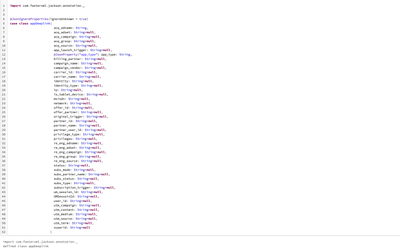
I have created a UDF using:%sqlCREATE OR REPLACE FUNCTION f_timestamp_max()....And I've confirmed it works with:%sqlselect f_timestamp_max()But when I try to use it in a Window function (lead over partition), I get:AnalysisException: Using SQL functi...
I'm trying to transfer my csv file from databricks to sftp but i'm getting file not found error.here is my code:file_size = sftp.stat("/dbfs/fileone.csv").st_sizewith open("/dbfs/fileone.csv", "rb") as fl:return self.putfo(fl, Destinationpath, file_s...
There is a hard limit of 145 active execution contexts on a Cluster. This is to ensure the cluster is not overloaded with too many parallel threads starving for resources. The limit is not configurable. If there are more than 145 parallel jobs to be ...
Hi all,We're trying to attach java libraries which are compiled/packaged using Java 11.After doing some research it looks like even the most recent runtimes use Java 8 which can't run the Java 11 code ("wrong version 55.0, should be 52.0" errors)Is t...
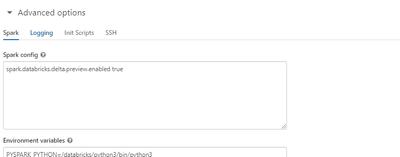
I have tried setting JNAME=zulu11-ca-amd64 under Cluster > Advanced options > Spark > Environment variables but it doesn't seem to work. I still get errors indicating Java 8 is the JRE and in the Spark UI under "Environment" I still see:Java Home: /u...
As shown in the figure, the case class and the json string are converted through fasterxml.jackson, but an unexpected error occurred during the running of the code. I think this problem may be related to the loading principle of the notebook. Because...
WBM is the best online Supermarket in Pakistan provides you with Fast home delivery of your complete grocery, Home Cleaning, Skincare, Baby Products, and Mosquito Repellent Collection.https://wbm.com.pk/
Hi All,I am trying to add new workflow which require to use credential passthrough, but when I am trying to create new Job Cluster from Workflow -> Jobs -> My Job, the option of Enable credential passthrough is not available. Is there any other way t...
assuming your Excel file is located on ADLS you can add a service principal to the cluster configuration. see: https://docs.microsoft.com/en-us/azure/databricks/data/data-sources/azure/azure-storage#--access-azure-data-lake-storage-gen2-or-blob-stora...
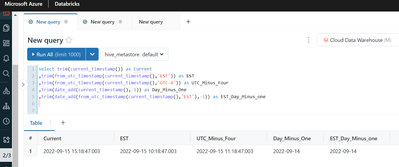
Hi,I found the bug while using in "from_utc_timestamp" function while using from UTC time stamp to EST time stampBelow is the Query Query:select trim(current_timestamp()) as Current,trim(from_utc_timestamp(current_timestamp(),'EST')) as EST,trim(from...
We provide online tutoring for students from Grade 5 and all the way up to professionals. You can find the best tutors for Maths, Biology, Physics, Chemistry, English, Social Sciences, Urdu in the comfort of your home. You can also find professional ...
The academized review is not that clear. The company seems legitimate enough, but the anonymous profiles make customers and users doubt its legitimacy. While Academized does list the number of custom feedbacks it offers and the fields of specializati...
Hi Team , I have attended the virtual instructor-led training on 23-08-2022 (https://www.databricks.com/p/webinar/databricks-lakehouse-fundamentals-learning-plan). As per the steps mentioned i have completed all of the steps for getting voucher, but ...
Hello All, We have deployed a new databricks instance in Azure cloud 1) Databricks service attached public subnet/private subnet (delegated to Microsoft.Databricks/workspaces)2) i created a job with cluster runtime ( 1 worker: Standard_DS3_v27.3 LTS...
In case others run into this in the future. Here is something additional to check:Is your account/workspace enabled for the "compliance security profile"? If yes, you should see a little shield icon in the lower left-hand corner of the workspace Once...
I am making use of repos in databricks and am trying to reference the current git branch from within the notebook session.For example:from pygit2 import Repositoryrepo = Repository('/Workspace/Repos/user@domain/repository')The code above throws an er...
You cannot use this as far as i know, but you can put a workaround in a notebook if you are calling code from your repo via a notebook:repo_path = "/Repos/xyz_repo_path/xyz_repo_name"repo_path_fs = "/Workspace" + repo_pathrepo_branch = "main"def chec...
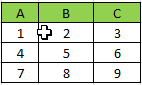
How to convert the rows of a spark dataframe to list without using Pandas.Input Spark Dataframe :Expected Output:[['A','B','C'],['1','2','3'],['4','5','6'],['7','8','9']]
Issue:After adding the listener jar file in the cluster init script, the listener is working (From what I see in the stdout/log4j logs)But when I try to hit the 'Content-Type: application/json' http://host:port/api/v1/applications/app-id/streaming/st...
Hi @swetha kadiyala Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Th...
Hi @sadiq vali Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks!