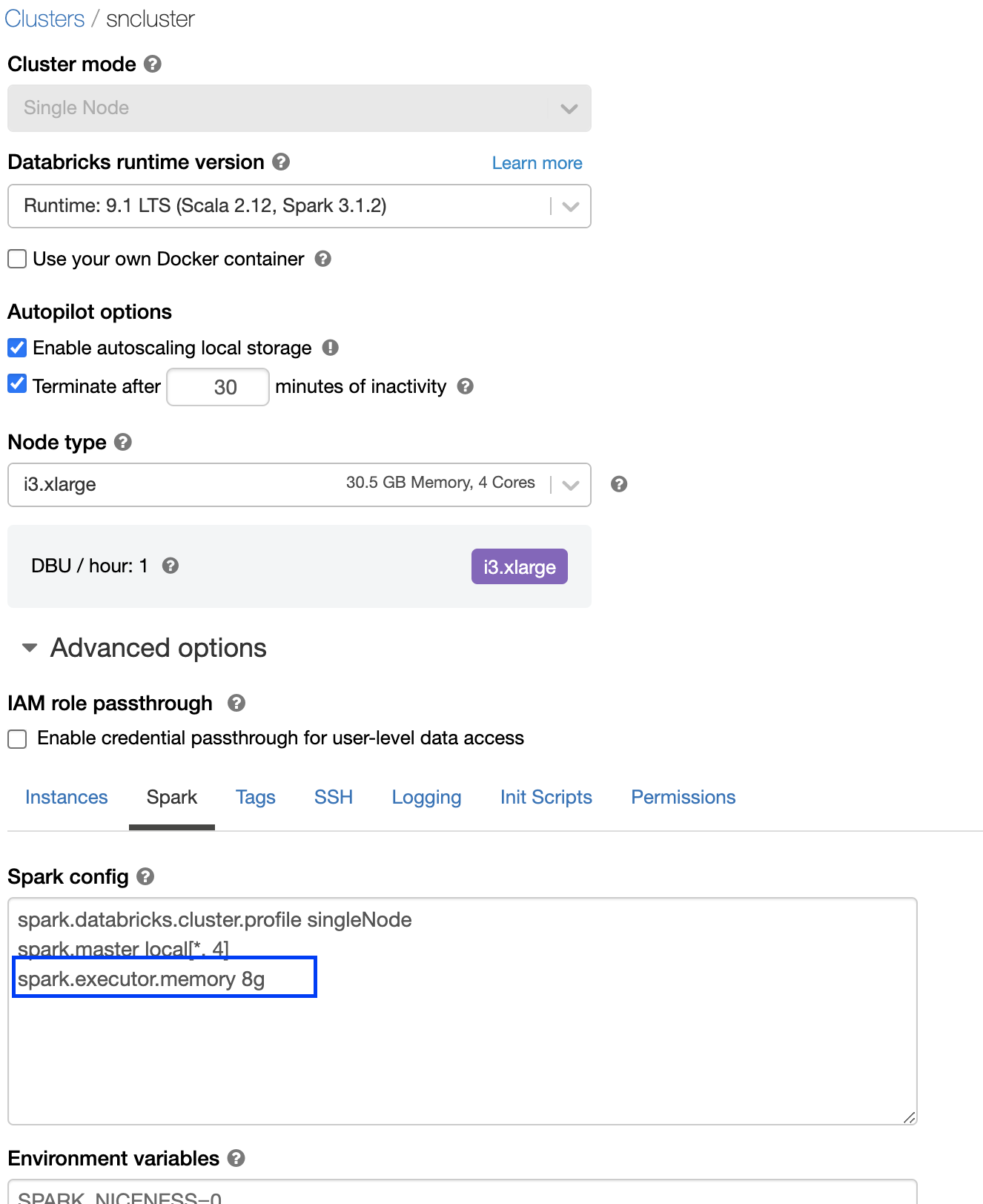
I am trying to read a 16mb excel file and I was getting a gc overhead limit exceeded error to resolve that i tried to increase my executor memory with,
spark.conf.set("spark.executor.memory", "8g")
but i got the following stack :
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Exception in thread "main" org.apache.spark.sql.AnalysisException: Cannot modify the value of a Spark config: spark.executor.memory;
at org.apache.spark.sql.RuntimeConfig.requireNonStaticConf(RuntimeConfig.scala:158)
at org.apache.spark.sql.RuntimeConfig.set(RuntimeConfig.scala:42)
at com.sundogsoftware.spark.spaceTrim.trimmer$.delayedEndpoint$com$sundogsoftware$spark$spaceTrim$trimmer$1(trimmer.scala:29)
at com.sundogsoftware.spark.spaceTrim.trimmer$delayedInit$body.apply(trimmer.scala:9)
at scala.Function0.apply$mcV$sp(Function0.scala:39)
at scala.Function0.apply$mcV$sp$(Function0.scala:39)
at scala.runtime.AbstractFunction0.apply$mcV$sp(AbstractFunction0.scala:17)
at scala.App.$anonfun$main$1$adapted(App.scala:80)
at scala.collection.immutable.List.foreach(List.scala:431)
at scala.App.main(App.scala:80)
at scala.App.main$(App.scala:78)
at com.sundogsoftware.spark.spaceTrim.trimmer$.main(trimmer.scala:9)
at com.sundogsoftware.spark.spaceTrim.trimmer.main(trimmer.scala)
my code :-
val spark = SparkSession
.builder
.appName("schemaTest")
.master("local[*]")
.getOrCreate()
spark.conf.set("spark.executor.memory", "8g")
val df = spark.read
.format("com.crealytics.spark.excel").
option("header", "true").
option("inferSchema", "false").
option("treatEmptyValuesAsNulls", "false").
option("addColorColumns", "False").
load("data/12file.xlsx")








{kind=link}