Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Extracting data from a multi-layered JSON obje...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2022 12:00 PM
I have a table in databricks called owner_final_delta with a column called contacts that holds data with this structure:
array<struct<address:struct<apartment:string,city:string,house:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>,addresses:array<struct<apartment:string,city:string,house:string,lastSeen:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>>,contactKey:string,emails:array<struct<emailId:string,lastSeen:string,sources:array<string>>>,lastModifiedDate:string,name:struct<firstNames:array<string>,lastNames:array<string>,middleNames:array<string>,salutations:array<string>,suffixes:array<string>>,phones:array<struct<extension:string,lastSeen:string,lineType:string,number:string,sources:array<string>,validSince:string>>,relationship:string,sources:array<string>>>
From this, I want to extract the emailId. I can extract contacts.emails which is an array that contains the emailId which itself can also be an array (if there are multiple emails tied to one record). The following is an example of one record returned from contacts.emails. A contact is akin to a business/company. So each element in the contacts.emails array is a person under that business/company. Furthermore, each person can have multiple emails (emailId).
array
- 0: [{"emailId": "emailA1@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}, {"emailId": "emailA2@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}, {"emailId": "emailA3@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}]
- 1: [{"emailId": "emailB1@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["SNL", "REONOMY"]}, {"emailId": "emailB2@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}, {"emailId": "emailB3@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}]
- 2: [{"emailId": "emailC1@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}, {"emailId": "emailC2@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}, {"emailId": "emailC3@gmail.com", "lastSeen": "Oct 12, 2021 6:51:33 PM", "sources": ["REONOMY"]}]
What I would like to achieve is a column of just the emailId where there is one emailId per row. For the above example, I would like this one record split into 9 rows, one for each emailId. I tried using get_json_object but must be doing something wrong.
select get_json_object(cast(contacts.emails as string), '$.emailId') as emailId from owner_final_delta
I tried the above query as well as other variations like using STR() or trying contacts.emails[0] or $contacts.emails and they all run into a compiler error or return null values. I would prefer a solution using SQL (so it can be easily utilized in Tableau), but any solution would work.
Labels:
- Labels:
-
Array
-
Data
-
JSON Object
-
Table


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 10:22 AM
So when I read it in, this is how I read it in. I'm changing the temporary view table name so it wont conflict with your other table.
Python:
df1 = spark.read.format("csv").option("header", "true").option("escape", "\"").option("multiLine",True).load("file_path_where_csv_file_is_located")
df1.createOrReplaceTempView("owner_final_delta1")
display(df1) select
from_json(contacts, """array<struct<address:struct<apartment:string,city:string,house:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>,addresses:array<struct<apartment:string,city:string,house:string,lastSeen:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>>,contactKey:string,emails:array<struct<emailId:string,lastSeen:string,sources:array<string>>>,lastModifiedDate:string,name:struct<firstNames:array<string>,lastNames:array<string>,middleNames:array<string>,salutations:array<string>,suffixes:array<string>>,phones:array<struct<extension:string,lastSeen:string,lineType:string,number:string,sources:array<string>,validSince:string>>,relationship:string,sources:array<string>>>""") contacts_parsed,
*
from owner_final_delta1Then the last one is SQL.
24 REPLIES 24
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2022 01:27 PM
Have you tried to use the explode function for that column with the array?
df.select(explode(df.emailId).alias("email")).show()----------
Also, if you are a SQL lover, you can instead use the Databricks syntax for querying a JSON seen here.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2022 02:22 PM
Thanks for your response! I tried the explode function (which is a pretty dangerous name for a function) and made sure to import pyspark.sql.functions and even made a new cluster with the most updated databricks runtime version, but I still get a "explode not defined" error. I even tried importing directly pyspark.sql.functions.explode but that model couldn't be found.
I then looked into the "Querying semi-structured data in SQL" documentation. I tried some of the methods there like raw:contacts.emails[*].emailId but got errors revolving around "raw column not existing" and when removing the "raw:" part I got an "invalid usage of '*'" error.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2022 01:57 PM
Explode - Does this code below give you the same error?
from pyspark.sql import functions as F
from pyspark.sql import Row
eDF = spark.createDataFrame([Row(a=1, intlist=[1,2,3], mapfield={"a": "b"})])
eDF.select(F.explode(eDF.intlist).alias("anInt")).show()For the SQL method, what is the column name in the table that holds this JSON structure in each row? Let's say that it is "contacts" and yet your JSON starts the nesting with "contacts" then it would be:
SELECT contacts:contacts.emails[*].emailId FROM table_nameSame error with this?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2022 03:10 PM
I tried your exact explode example and it worked. I then plugged in my data like so:
df = sqlContext.table("owner_final_delta")
import pyspark.sql.functions as F
df.select(F.explode(df.contacts.emails[0].emailId).alias("email")).show()
This worked but notice I am using [0] (index 0 of the emails array). I tried using [*] there but I get an invalid syntax error. Is there a way to loop through all df.contacts.emails and return all the .emailIds in one column?
For the SQL method the column name holding the JSON structure is contacts. So I tried the query exactly as you have written it:
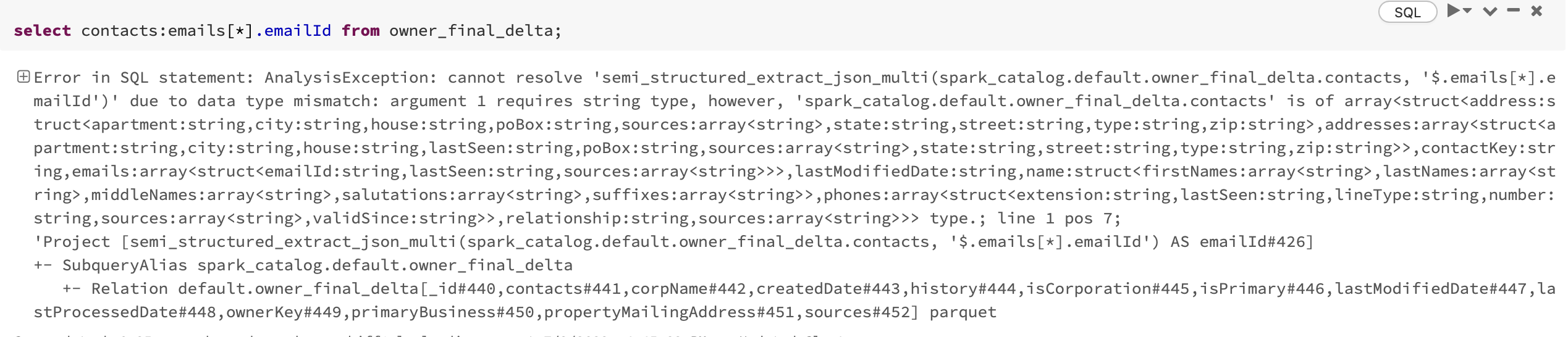
select contacts:contacts.emails[*].emailId from owner_final_delta
This returns this error essentially saying there is an argument type mismatch in that contacts is not a string:
Error in SQL statement: AnalysisException: cannot resolve 'semi_structured_extract_json_multi(spark_catalog.default.owner_final_delta.contacts, '$.contacts.emails[*].emailId')' due to data type mismatch: argument 1 requires string type, however, 'spark_catalog.default.owner_final_delta.contacts' is of array<struct<address:struct<apartment:string,city:string,house:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>,addresses:array<struct<apartment:string,city:string,house:string,lastSeen:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>>,contactKey:string,emails:array<struct<emailId:string,lastSeen:string,sources:array<string>>>,lastModifiedDate:string,name:struct<firstNames:array<string>,lastNames:array<string>,middleNames:array<string>,salutations:array<string>,suffixes:array<string>>,phones:array<struct<extension:string,lastSeen:string,lineType:string,number:string,sources:array<string>,validSince:string>>,relationship:string,sources:array<string>>> type.; line 1 pos 7;
'Project [semi_structured_extract_json_multi(spark_catalog.default.owner_final_delta.contacts, '$.contacts.emails[*].emailId') AS emailId#956]
How should this be resolved?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2022 03:53 PM
df = sqlContext.table("owner_final_delta")
import pyspark.sql.functions as F
df.select(F.explode(df.contacts.emails).alias("email")).show()If you explode only the emails, I'm thinking each row will be a new emailId in that category. What do you get with that?
-------
SQL side of life
If the column is "contacts" and emails is the first level in the nested json for emailId, I'm thinking you might have to leave off the second "contacts" I put in.
SELECT contacts:emails[*].emailId FROM owner_final_deltaDoes this also give you an error?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-09-2022 01:49 PM
With your modified explode function, I am now getting the whole array of arrays of contacts.emails. It looks like [[emailId, date, source]]. There could be multiple in one row as well like [[emailId, date, source], [emailId, date, source], [emailId, date, source]]. So we still need to drill further.
As for the SQL command, I am still getting a type mismatch error seen below.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2022 11:20 AM
I think you are right. We are close.
For Python, let's try exploding twice. If we have, [[emailId, date, source], [emailId, date, source], [emailId, date, source]] then let us explode that column out as well so each email ID has its own row.
df = sqlContext.table("owner_final_delta")
import pyspark.sql.functions as F
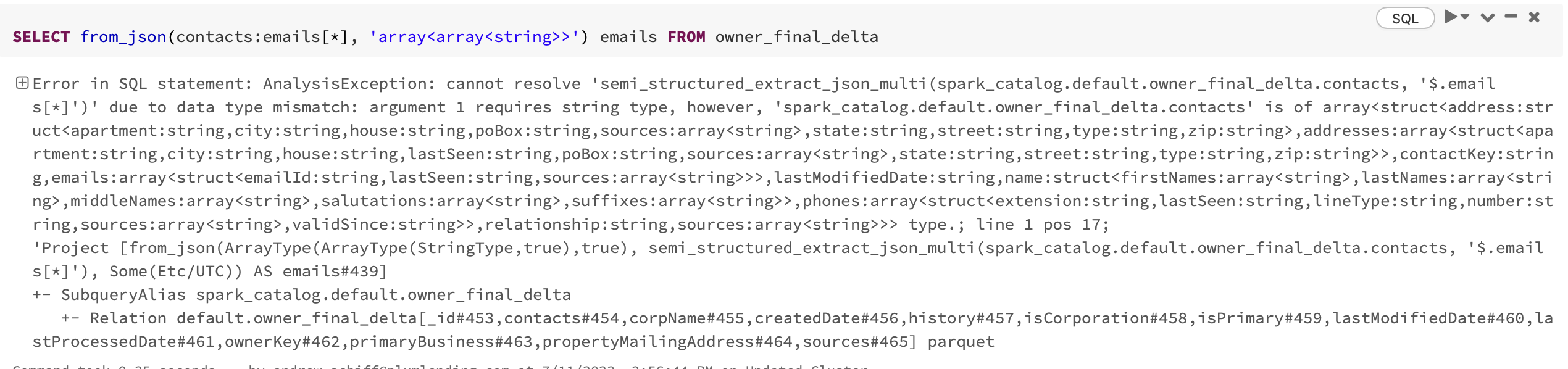
df.select(F.explode(F.explode(df.contacts.emails).alias("email")).alias("email_ids")).show()And then for SQL, does this command give you errors as well? I
SELECT from_json(contacts:emails[*], 'array<array<string>>') emails FROM owner_final_deltaI believe emails is an array of an array of strings. I want to see if we can get here first without any errors before digging deeper into the nest.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2022 01:02 PM
So I tried exploding twice and got the error: Generators are not supported when it's nested in expressions, but got: explode(explode(contacts.emails) AS email).
After doing some research, explode is a generator function that makes new columns so you can't use functions on explode. https://stackoverflow.com/questions/50125971/generators-are-not-supported-when-its-nested-in-express...
I was also looking into the explode function in Pandas but don't know if this one would work or how to get the data formatted correctly to be a Pandas DataFrame.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.explode.html
The SQL query gives me the same error of mismatched argument type.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2022 02:15 PM
Is there any way you can post a small sample of the owner_final_delta table so I can try out some code on my side?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-11-2022 04:01 PM
Here you go. Good luck!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 09:15 AM
This worked for me (see the column "emailIds" in the output):
%sql
select
explode(
aggregate(
contacts_parsed.emails,
array(''),
(acc,x)->array_union(acc,transform(x,(y,i)->y.emailId)),
acc->array_remove(acc,'')
)
) emailIds,
* from (
select
from_json(contacts, """array<struct<address:struct<apartment:string,city:string,house:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>,addresses:array<struct<apartment:string,city:string,house:string,lastSeen:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>>,contactKey:string,emails:array<struct<emailId:string,lastSeen:string,sources:array<string>>>,lastModifiedDate:string,name:struct<firstNames:array<string>,lastNames:array<string>,middleNames:array<string>,salutations:array<string>,suffixes:array<string>>,phones:array<struct<extension:string,lastSeen:string,lineType:string,number:string,sources:array<string>,validSince:string>>,relationship:string,sources:array<string>>>""") contacts_parsed,
*
from owner_final_delta
)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 09:32 AM


Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 10:01 AM
This looks like it is not parsing which is interesting. Are you using the latest databricks runtime in your cluster?
Also, does this part give you errors?
select
from_json(contacts, """array<struct<address:struct<apartment:string,city:string,house:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>,addresses:array<struct<apartment:string,city:string,house:string,lastSeen:string,poBox:string,sources:array<string>,state:string,street:string,type:string,zip:string>>,contactKey:string,emails:array<struct<emailId:string,lastSeen:string,sources:array<string>>>,lastModifiedDate:string,name:struct<firstNames:array<string>,lastNames:array<string>,middleNames:array<string>,salutations:array<string>,suffixes:array<string>>,phones:array<struct<extension:string,lastSeen:string,lineType:string,number:string,sources:array<string>,validSince:string>>,relationship:string,sources:array<string>>>""") contacts_parsed,
*
from owner_final_deltaIf it parses correctly the output in that "contacts_parsed" column should show you an arrow on the top left part of each cell in that column that points to the right. You click it and it breaks down the pieces in the json file.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 10:11 AM

Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Pipeline still needs USE SCHEMA on an old schema it no longer writes to in Data Governance
- Materialized View backing pipeline retains old Unity Catalog after catalog rename in Data Engineering
- AnalysisException: [UNRESOLVED_ROUTINE] Cannot resolve routine `=` in Data Engineering
- X-Forwarded-Access-Token occasionally return stale values from a previous session in Administration & Architecture
- Genie One – Unable to Extract Usage Details in Warehousing & Analytics