Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Fatal error: Python kernel is unresponsive
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Fatal error: Python kernel is unresponsive
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-07-2022 01:03 AM
Hey guys,
I'm using petastorm to train DNN, First i convert spark df with make_spark_convertor and then open a reader on the materialized dataset.
While i start training session only on subset of the data every thing works fine but when I'm using all dataset after about 500 batches my notebook crash with Python kernel is unresponsive, any of you know what this happening?
I saw kinda similar question already and i looked on thread dumps but didn't understood it to much.
Besides i get alot of future warning from petastorm about pyarrow, have any idea how to avoid all this warnings?
Labels:
- Labels:
-
Python
-
Python Kernel


25 REPLIES 25
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2022 05:32 AM
@Cheuk Hin Christophe Poon
Well, I don't have any decent idea besides check why this happening, Maybe like you said - the transpose require to collect all the data into driver, maybe you can find valuable information in the spark UI.
Hope you will solve this problem, but its really sound weird that you need 128GB machine to transpose 2 GB matrix.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
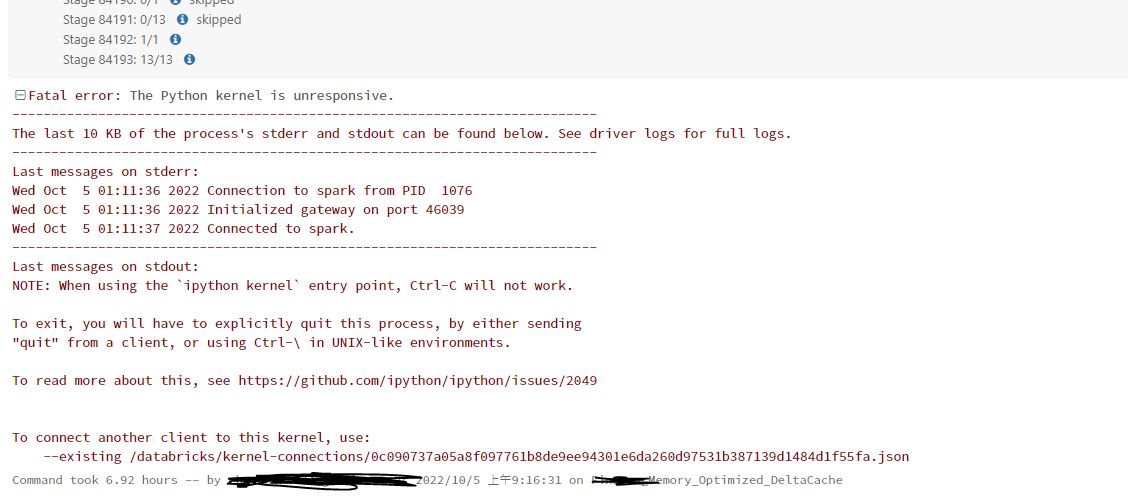
10-05-2022 01:58 AM
I also have the same problem.
Before `Fatal error: Python kernel is unresponsive`, the process `Determining location of DBIO file fragments. This operation can take some time` took me 6.92 hours.
I want to know whether this is normal.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-25-2022 10:27 AM
Hey @Cheuk Hin Christophe Poon , I don't know if you managed to solve this issue.
I saw in Databricks blog that this error is caused by out of RAM issue, link here
Besides, When i tried to run my notebook from a job, not just that the run finished without any errors but also the RAM that was being used cut down by half - maybe you should give it a try if didn't managed yet.
I think that when you run the code inside the notebook a lot of state is saved any fill up the RAM ( It's just a feeling I didn't confirm that).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-25-2022 12:33 PM
@orian hindi I also think the problem is insufficient RAM. But I already deployed 6-8 Standard_NC6s_v3 (GPU-accelerated compute) in Azure Databricks.
Is it still not enough for me to run Kmean clustering on 252000 data pints (n_cluster = 11, max iteration = 10) using SparkML and Sckit-learn?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-07-2022 09:06 AM
Hey Guys,
While I was training I noticed two things that might cause the error.
The first one is after a training session was crashed, the GPU memory was almost full ( checked with Nvidia semi command).
The second one is that I saw in ganglia metrics a Swap above the total memory of
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2022 05:59 PM
if a python process does not use spark, such as pandas (not spark pandas), only one node is used. I ran exact same error on a regular cluster with multiple nodes.
One solution is to use a single node with a lot of memory such as 128 G above. That means allocating enough resolution into a single node instead of splitting into multiple nodes.
however, I try to avoid pandas as most problems can be solved using spark except for some special utility where there is no other choice.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-11-2022 10:20 PM
@lizou
Today, I have the same problem when I spark transpose 1000 columns x 4284 rows structured data matrix. The data size is about 2GB.
Here is the code:
https://github.com/NikhilSuthar/TransposeDataFrame
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
def TransposeDF(df, columns, pivotCol):
columnsValue = list(map(lambda x: str("'") + str(x) + str("',") + str(x), columns))
stackCols = ','.join(x for x in columnsValue)
df_1 = df.selectExpr(pivotCol, "stack(" + str(len(columns)) + "," + stackCols + ")")\
.select(pivotCol, "col0", "col1")
final_df = df_1.groupBy(col("col0")).pivot(pivotCol).agg(concat_ws("", collect_list(col("col1"))))\
.withColumnRenamed("col0", pivotCol)
return final_df
df = TransposeDF(df, df.columns[1:], "AAPL_dateTime")(The above code works for transposing a small data matrix (eg. 5 columns x 252 rows) )
I deploy one 32GB memory VM and there is still a `Fatal error: Python kernel is unresponsive`
Transposing a data matrix should only have O(C x R) space complexity and runtime complexity.
In my case, that should be 2GB of space complexity.
I checked the Databricks Live metrics. Only 20% CPU is used and there is still 20 GB of free memory. However, there is a `Driver is up but not responsive, likely due to GC` in the event log.
I have no idea why there is still `Fatal error: Python kernel is unresponsive` 😂 . Perhaps, It is not only related to memory?😵
Now, I am trying one 112 GB memory GPU to transpose a 2 GB data matrix. And there is no `Driver is up but not responsive, likely due to GC` in the event log. Hope this works. But still cannot understand why transposing a 2 GB data matrix needs that amount of memory😅
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-12-2022 10:42 AM
@Cheuk Hin Christophe Poon
I am not sure how the library makes use of memory, maybe there is extra memory required to hold the data transformation process.
I also found an article about pandas won't go faster on a 20 node cluster.
https://learn.microsoft.com/en-us/azure/databricks/migration/single-node
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-12-2022 12:24 PM
@lizou
I also think so. Every time, when the memory use% reaches 50%+, Databricks will autoscale more workers.
3 days ago, I used pandas to transpose the data, but it seems super slow and failed due to GC. Yesterday, I tried to transpose the data only using PySpark.
I think Databricks needs to explain more about how they allocate memory and memory calculation methods.
btw, just now, I completed my data transposition.
Here is what I do:
- Deploy one single 128GB memory VM to transpose the data for 17 hours despite the data size being far less than 128GB (actual data size is 2 GB, but the Databricks Live Metrics says it is 20GB. Maybe, I forgot to vacuum the delta tables? that's why it says 20GB?) and the theoretical complexity being O(RxN).
Here is my guess: Transposing a data matrix requires collecting all the data into one node, so deploying many smaller VMs may fail the data transposition. Transposing data can only be done in single-node mode.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2022 09:17 PM
Tips to Fix a Fatal Error
Search for the error code to find specific instructions.
Update the software.
Update the drivers.
Uninstall any recently installed programs.
Restore Windows to an earlier state.
Disable unnecessary background programs.
Delete temporary files.
Free up space on the hard drive.
Regards,
Rachel Gomez
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-11-2022 07:26 PM
Same error. This started a few days ago on notebooks that used to run fine in the past. Now, I cannot finish a notebook.
I have already disabled almost all output being streamed to the result buffer, but the problem persists. I am left with <50 lines being logged/printed. If Databricks cannot handle such a minimal amount of output, it's not a usable solution.
- « Previous
-
- 1
- 2
- Next »
Announcements





{kind=link}
Related Content
- Fatal error: The Python kernel is unresponsive. in Data Engineering
- Import CV2 results in Fatal Error in Machine Learning
- Testing Spark Declarative Pipeline in Docker Container > PySparkRuntimeError in Data Engineering
- filedescriptor out of range in select() in Machine Learning
- Importing LanceDB Library Crashes Python Driver in Generative AI