Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Filtering files for query
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Filtering files for query
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2023 06:13 AM
Hi Team,
While writing my data to datalake table I am getting 'filtering files for query', it would be stuck at writing
How can I resolve this issue


13 REPLIES 13
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2023 06:51 AM
Can you give some more details? Are doing merge statements? How big are the tables?
For merge statements i.e. the process needs to read the target table to analyze which parquet files need to be rewritten. If you don't have proper partitioning or z-index, it could end up scanning all files even you only try to update a few rows.
Did you try to optimize the tables already?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2023 07:47 AM
Thanks for quick reply,
I am using SSMS as my redacted table and it is using upsert as write mode, that table huge in size when I checked the SQL part in
Databricks ,it is reading every records to memory
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2023 08:01 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2023 10:13 AM
@pgruetter
could you please check above?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2023 06:23 PM
@Muhammed describe <table_name> will give you idea about how your table is partitioned. Consider adding partition column condition in where clause for better performance.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2023 10:33 AM
Still hard to say, but it sounds like my assumption is correct. Because your upsert doesn't which records to update, it needs to scan everything. Make sure that it's properly partitioned, you have a z-index and execute an optimize table.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2023 11:37 PM
Hi Kaniz
I have one more issue , i am writing less than 1.2k records to the datalake table (append mode). While writing it is showing "determining dbio file fragments this would take some time', when i checked the log i see GC allocation failure .
and my overall execution time is 20 mins which is hard for me , how can i resolve this , ? is it mandatory to use Vaccum, Analyze queries along with Optimize
shall i run optimize datalake.table ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2023 11:39 PM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-09-2023 08:09 AM
We are using framework for data ingestion, hope this will not make any issues to the metadata of the datalake table ?, as per the framework metadata of the table is crucial , any changes happened to it will effect the system .
Some times the particular pipeline would take 2 hrs for just writing 1k records.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-11-2023 09:38 AM
Hi @Retired_mod
Any info on this ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2023 06:33 PM
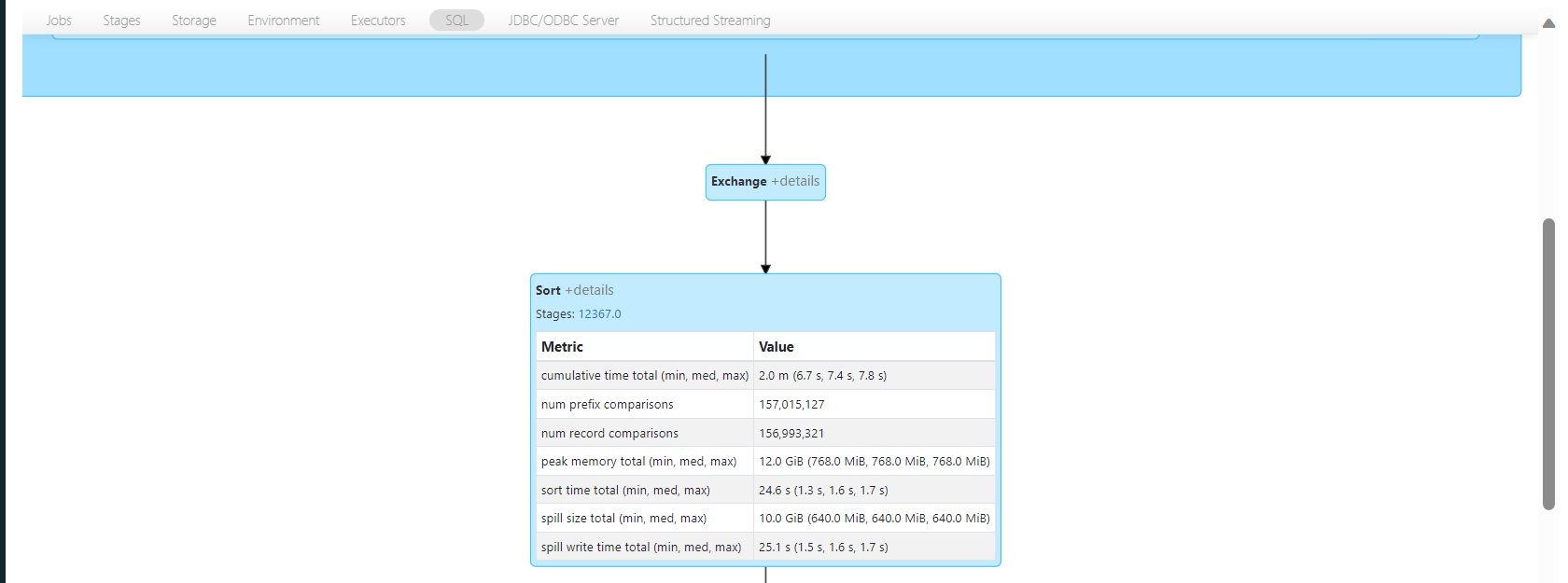
I understand you are getting 'filtering files for query' while writing.
From screenshot it looks like you have 157 million files in source location. can you please try dividing the files per by prefix so that small microbatches can be processed in parallel.
Try to use maxFilesPertrigger option so restrict files per batch.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-14-2023 04:26 AM
Where did you get the info related to 157 million files ? If possible could you pls explain it
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-14-2023 10:31 AM
My bad, somewhere in the screenshot I saw that but not able to find it now.
Which source you are using to load the data, delta table, aws-s3, or azure-storage?
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Enforcing Minimum Cohort Size in a Databricks App with AI/BI Genie in Generative AI
- Does enabling variantType-preview disable file-level data skipping for columns after a VARIANT colum in Data Engineering
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering
- DeltaFileStatistics on a nested column (`created date.shipment`) cause filtering issues in Data Engineering
- Table history time travel in Data Engineering