Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Foreign catalog - Connections using insecure trans...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
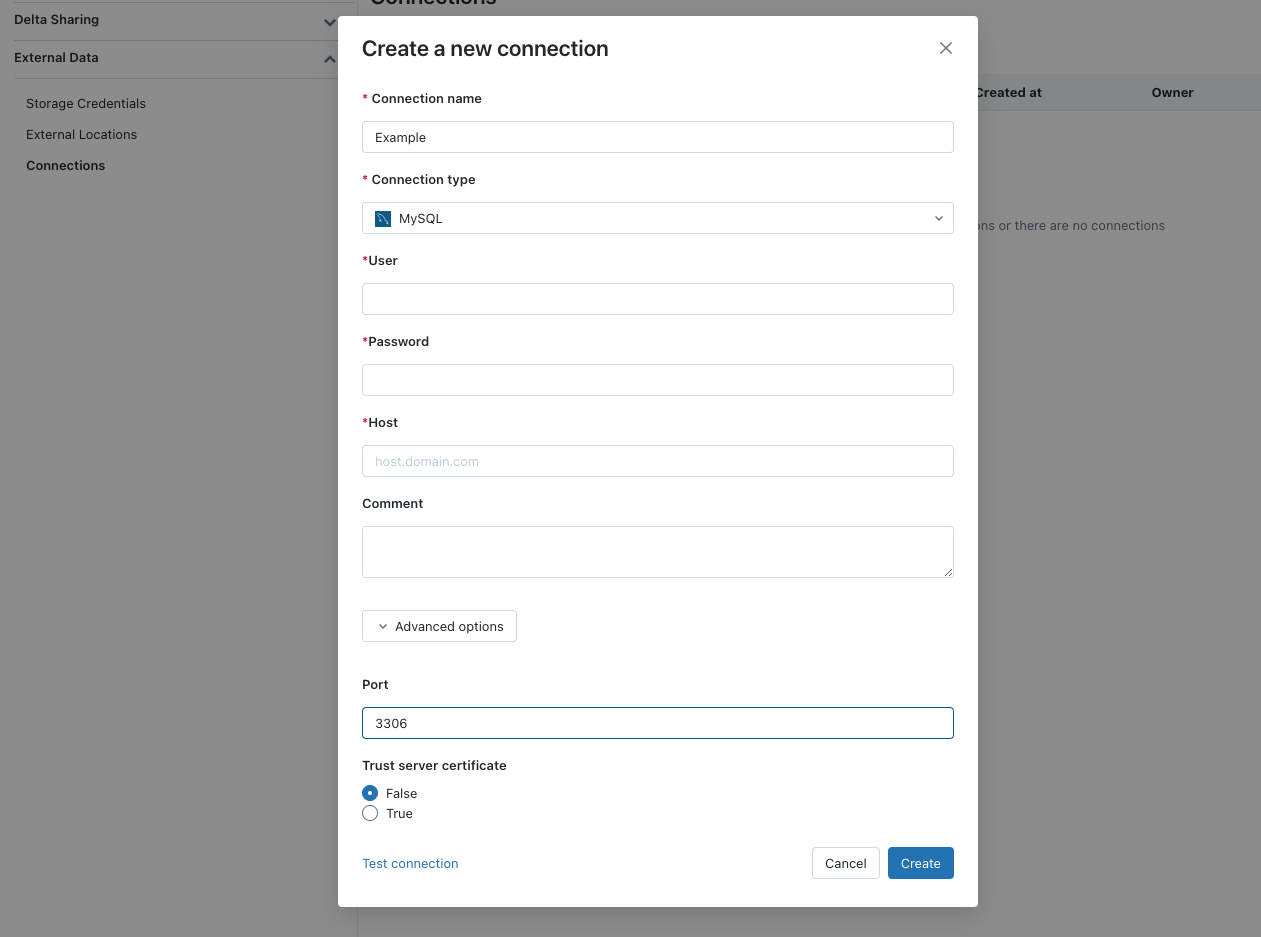
Foreign catalog - Connections using insecure transport are prohibited --require_secure_transport=ON
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-19-2023 12:52 PM
I have added a connection to a MySql database in Azure, and I have created a foreign catalog in Databricks. But when I go to query the database I get the following error;
Connections using insecure transport are prohibited while --require_secure_transport=ONI appreciate that I can turn off this setting on my database, but I would rather do it properly and configure it from the Databricks side. Is it possible to configure Databricks so it uses secure transport on external connections?


6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-20-2023 01:10 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-20-2023 01:39 AM
Hi Kaniz,
That is the way I work when I normally query data from the azure SQLdatabase in DBX. But I am trying to use the new Lakehouse Federation from within DBX itself which should abstract away those connections properties.
https://learn.microsoft.com/en-us/azure/databricks/query-federation/mysql
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-08-2024 05:33 PM
Hi,
Is there an update on this? I have the same issue where I try using Lakehouse federation but I cannot input the additional connection information or manually edit the url created when defining a "connection" on the databrick UI required for Lakehouse federation.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2024 12:22 AM
I was trying to connect to our database (Azure MySQL) from DBX, but we wanted require_secure_transport to be set to ON, and we didn't want to turn it off. We ended up moving DBX within a VNET and setting up a private link to get around this.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2024 07:20 PM
Thanks Tim. That seems like the way to go. You prompted me to find this section of the docs: Networking recommendations for Lakehouse Federation - Azure Databricks | Microsoft Learn which mentions exactly what you just said.
On a side note: If you have set up databricks serverless compute to access your Azure mySQL? Did you do the same thing with the serverless compute?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-10-2024 01:02 AM
I was unable to use serverless compute with Azure MySQL. I did have a meeting with tech support at databricks and the conclusion at the time was - if your Azure MySql is not publically accessible, you cannot connect to it from serverless compute.
I'm mainly using serverless compute to access Dashboards, so I'm using jobs in the background to populate delta tables so the serverless compute can access those instead as a work around.
Announcements





{kind=link}
Related Content
- CREATE CONNECTION - Support for Community Connections? in Data Engineering
- Can I connect Fabric Data Agent With Databricks Genie One as external connection in Administration & Architecture
- Can I connect Fabric Data Agent With Databricks Genie One as external connection in Data Governance
- CONNECTION Permission Issue - Can't use existing connection for Community Custom Connector in Data Governance
- Issue: Lakeflow Connect Microsoft Teams Community Connector - No module named 'databricks.labs' in Data Engineering