Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Get file information while using "Trigger jobs...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-27-2023 06:37 AM
I am currently trying to use this feature of "Trigger jobs when new file arrive" in one of my project. I have an s3 bucket in which files are arriving on random days. So I created a job to and set the trigger to "file arrival" type. And within the notebook I am trying to read from that s3 location like this:
df = (spark.read.format("csv")
.option("inferSchema", True)
.option("header", True)
.option("sep", ",")
.load("s3:/<bucket_name>/<subfolder>/"))The job gets triggered when a new file arrives. But when new file arrives it reads the previous file as well. I just want to read the new file and will append it to any existing table.
Is there any way to get file name so that I can use the code to read only new files like below:
file_name = dbutils.widgets.get("file_name")
df = (spark.read.format("csv")
.option("inferSchema", True)
.option("header", True)
.option("sep", ",")
.load("s3://<bucket_name>/<folder_name>/<file_1.csv>"))Or is there any other way to resolve it. ?
Labels:
- Labels:
-
File Trigger
-
New File


1 ACCEPTED SOLUTION
Accepted Solutions
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-28-2023 10:31 AM
@Nikhil Kumawat :
Yes, you can get the name of the newly arrived file by using the filePaths() method on the DataFrame that is passed to the notebook. This method returns a list of paths that correspond to the files that have been added since the last trigger.
Here is an example code snippet that shows how to get the name of the new file:
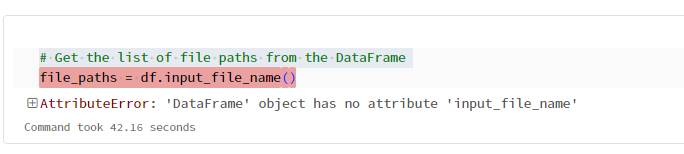
# Get the list of file paths from the DataFrame
file_paths = df.input_file_name()
# Get the name of the new file
new_file_path = file_paths[-1]
new_file_name = new_file_path.split("/")[-1]
# Load the new file into a DataFrame
df_new = (spark.read.format("csv")
.option("inferSchema", True)
.option("header", True)
.option("sep", ",")
.load(new_file_path))In this code snippet, df is the DataFrame that is passed to the notebook by the trigger. The input_file_name() method returns a DataFrame column that contains the file path of each row. By calling file_paths[-1], you can get the path of the last (newly arrived) file. The split("/")[-1] call extracts the file name from the path. Finally, you can use this file name to load the new file into a DataFrame.
Note that if you want to append the new file to an existing table, you can simply use the
mode("append") option when loading the file:
df_new.write.format("delta").mode("append").saveAsTable("my_table")This will append the new data to the existing my_table table.
11 REPLIES 11
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-28-2023 10:31 AM
@Nikhil Kumawat :
Yes, you can get the name of the newly arrived file by using the filePaths() method on the DataFrame that is passed to the notebook. This method returns a list of paths that correspond to the files that have been added since the last trigger.
Here is an example code snippet that shows how to get the name of the new file:
# Get the list of file paths from the DataFrame
file_paths = df.input_file_name()
# Get the name of the new file
new_file_path = file_paths[-1]
new_file_name = new_file_path.split("/")[-1]
# Load the new file into a DataFrame
df_new = (spark.read.format("csv")
.option("inferSchema", True)
.option("header", True)
.option("sep", ",")
.load(new_file_path))In this code snippet, df is the DataFrame that is passed to the notebook by the trigger. The input_file_name() method returns a DataFrame column that contains the file path of each row. By calling file_paths[-1], you can get the path of the last (newly arrived) file. The split("/")[-1] call extracts the file name from the path. Finally, you can use this file name to load the new file into a DataFrame.
Note that if you want to append the new file to an existing table, you can simply use the
mode("append") option when loading the file:
df_new.write.format("delta").mode("append").saveAsTable("my_table")This will append the new data to the existing my_table table.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-01-2023 10:35 PM
Thanks @Suteja Kanuri for the reply.
One question , how can I pass this dataframe from the job trigger ? Or am I missing something.
I tried the below approach:
df = (spark.read.format("csv")
.option("inferSchema", True)
.option("header", True)
.option("sep", ",")
.load("s3:/<bucket_name>/<subfolder>/"))Then I tried to use input_file_name() method on this dataframe like below but it gave me error saying "no such method":

For reference I am passing the notebook which gets triggered by the job:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-04-2023 10:54 AM
@Nikhil Kumawat :
It seems like you are trying to use the input_file_name() function on a DataFrame, which is not possible. The input_file_name() function is an input file metadata function that can be used only with a structured streaming DataFrame to get the name of the file being processed.
If you want to pass the DataFrame to a job trigger, you can consider writing the DataFrame to a file and passing the file path as an argument to the job trigger. Here's an example of how you can write the DataFrame to a CSV file and pass the file path as an argument:
df = (spark.read.format("csv")
.option("inferSchema", True)
.option("header", True)
.option("sep", ",")
.load("s3:/<bucket_name>/<subfolder>/"))
# Write DataFrame to CSV file
output_path = "s3:/<bucket_name>/<subfolder>/output.csv"
df.write.format("csv").option("header", True).save(output_path)
# Pass file path as an argument to the job trigger
trigger_args = {
"output_path": output_path
}
# Trigger the job with the arguments
response = client.start_trigger(Name='<trigger_name>', Arguments=trigger_args)In the above example, we are writing the DataFrame to a CSV file using the write() method of DataFrame and passing the output file path as output_path. Then we are creating a dictionary trigger_args with the argument name and value to pass to the job trigger. Finally, we are triggering the job with the start_trigger() method of the AWS Glue client and passing the trigger name and arguments.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-29-2023 12:53 AM
Hi @Nikhil Kumawat
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?
This will also help other community members who may have similar questions in the future. Thank you for your participation and let us know if you need any further assistance!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-07-2023 07:50 AM
This solution doesn't answer the question...
It seems that no additional parameters are passed to the job for file arrivals as described here (https://learn.microsoft.com/en-us/azure/databricks/workflows/jobs/file-arrival-triggers).
Any plans on adding that in the future @Anonymous ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2024 05:44 AM
Looks like a major oversight not to be able to get the information on what file(s) have triggered the job. Anyway, the above explanations given by Anon read like the replies of ChatGPT, especially the scenario where a dataframe is passed to a trigger gives away it has no understanding of the Databricks Jobs and Tasks, and it further provides a solution with input_file_name() and in the next replies explains why it couldn't possibly be working. "Sorry for the confusion"...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-29-2024 07:24 AM
Hey all, appreciate everyone’s effort here, but we really need to address the issue with this answer thread. Incorrect info, especially from an unvetted LLM-generated response, does more harm than good – it’s wasted my time, and I’m sure others have felt the same frustration. When the answer itself gets contradicted in the follow-ups, it just adds to the confusion and makes it look like no one’s actually validated the initial advice.
@adriennn, @Rik, @nikhilkumawat, maybe consider unapproving the accepted answer? It could help other engineers avoid this same rabbit hole.
Databricks, can we work on getting better quality control here? It’s crucial for these threads to provide solid, reliable info we can actually use without having to double-check every response. Let’s keep it useful for everyone.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-29-2024 10:13 AM
@edejong understand your frustration with this forum.
The solution to the above is to use autoloader/structured streaming (op is using spark.read, but he needs spark.readStream), which will load only the files which haven't been processed yet. Briefly, this goes like this:
- if your code runs as a job with a notebook, you can pass the name of the file arrival trigger path (the directory) as parameter and use it below in the load() call
- by using .select("*", "_metadata"), each row will contain a column with some metadata and the fulle path to the source file in the bucket from which it was created
spark.readStream.format("cloudFiles").options(...).load('s3://mybuck/list').select("*", "_metadata").writeStream.option(...).trigger(availableNow=True).ToTable('mytable')
With the trigger "available now", the engine will process only what's already in storage, and if you run it again at later time after new files have arrived, the same code will only process these new files. If you are not happy with just dumping the data for all the source files into the sink table, you can also plug a custom function with foreachbatch to run on every incoming file. Note that if you need to process the incoming files in strict order and in serie, foreachbatch might not be suitable.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-29-2024 05:15 PM
@edejong, agreed. I don't know how to unapprove the solution (I assume only OP can do that), but I did report it to the moderator.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-29-2024 11:55 PM
I spent some time configuring a setup similar to this. Unfortunately, there's no simple way to do this. There's only {{job.trigger.file_arrival.location}} parameter, but that is pretty much useless, since it points to the directory that we are watching instead of the file that arrived.
For your situation, I'd use dbutils.fs.ls(dir) and filter based on your needs. Then feed the path of a single file to spark or something.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2025 10:56 AM
Issue with Databricks File Arrival Trigger – Missing File Name Information
The File Arrival Trigger in Databricks is practically useless if it does not provide the file name and path of the triggering file. In Azure Blob Storage triggers (Function Apps, ADF, Event Grid, etc.), we receive the exact file path, allowing efficient processing of only the new file.
However, in Databricks, if we have to list all files in the storage account on every run just to determine which one is new, this defeats the purpose of the trigger. This needs to be patched, or the feature adds unnecessary overhead to workflows. Please address this issue so that Databricks can be used effectively for event-driven file processing.
Announcements





{kind=link}
Related Content
- Genie One – Unable to Extract Usage Details in Warehousing & Analytics
- How to Prepare Enterprise Data for AI Agents: A Practical Guide in Data Engineering
- Zerobus ingestion fails in Databricks Free Edition using Service Principal OAuth in Administration & Architecture
- Unable to Subscribe to the 14 day free trial in Administration & Architecture
- Five Unity Catalog ABAC Updates Worth Paying Attention To in Data Governance