Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Getting error while loading parquet data into Post...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Getting error while loading parquet data into Postgres (using spark-postgres library) ClassNotFoundException: Failed to find data source: postgres. Please find packages at http://spark.apache.org/third-party-projects.html Caused by: ClassNotFoundException
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2023 04:10 AM
Hi Fellas - I'm trying to load parquet data (in GCS location) into Postgres DB (google cloud) . For bulk upload data into PG we are using (spark-postgres library)
Pre requisite- To use above library , I have uploaded jar in my cluster
1- https://mvnrepository.com/artifact/io.frama.parisni/spark-postgres/0.0.1
2- https://mvnrepository.com/artifact/org.postgresql/postgresql
%scala
val data = spark.read.format("postgres")
.option("url","jdbc:postgres://IP:PORT/DATABASE?user=USERNAME¤tSchema=SCHEMANAME")
.option("password","PASSWORD")
.option("query","select * from TABLENAME")
.option("partitions",4)
.option("numSplits",5)
.option("multiline",true)
.load
But it is giving error -
ClassNotFoundException: Failed to find data source: postgres. Please find packages at http://spark.apache.org/third-party-projects.html Caused by: ClassNotFoundException: postgres.DefaultSource
P.S- Since my data is huge I need to use bulk load operation since by jdbc connection and inserting via cursor batch is not optimal method .
Let me know if there are any other methods available for bulk insert .
Data size ~ 40 GB parquet
Regards,
Labels:
- Labels:
-
Datasource
-
Gcs


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2023 04:47 AM
Just a lucky guess here... Maybe the spark-postgres library was not correctly installed? Try removing the jar and uploading it once again.
If that doesn't work, try to replace spark.read.format("postgres")
with spark.read.format("io.frama.parisni.spark.postgres.DataSource")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-16-2023 08:53 AM
Hi @Kaniz Fatma and @Daniel Sahal , Thanks for reaching out , appreciate it.
Background to help you understand the context .
Problem statement-
We are facing performance issues during Postgres data loading from GCS storage (parquet format) . Data load is done in 2 parts.
First to create postgres intermediate_table by reading GCS data as spark dataframe and save it in Postgres as table .
Then from intermediate load into main table (with some logic ) .We have already implemented the code and it is working fine for smaller data sets
But when it comes to large dataset , it is posing issue .
We ensured there is no constraint in Postgres intermediate table also there is one PK in postgres main table for merging functionality. Postgres is also in GCP.
Elaborating what has been said above with code snippet.
Stage-1 ->
Creation of Postgres intermediate table (persistent table) by writing spark data frame as table in Postgres (overwrite mode) from the data stored in GCS (parquet data format ~ volume 25-30 GB, total number of part files - 71)
Code snippet –
df.write.mode("overwrite").option("numPartitions", number ).format("jdbc").option("url", url).option("dbtable", dbtable).option("user", user_nm).option("password",passwrd).save()
Stage -2 -> Inserting Postgres intermediate table (created in step-1) data into main Postgres table (persistent) via insert statement (SCD type-1).
Code
snippet –
INSERT INTO main_tab (SELECT columns FROM intermediate_table ) ON CONFLICT do something DO UPDATE SET
Postgres and Databricks resource details
Attached screen shots


Tried options ,
- We ensured to use maxfilepertrigger ,batchsize , num of partition options as well in above code to ingest bulk data.
Then we saw spark-postgres option and tried below ways
option -1 – writing dataframe and giving option as “postgres” ex- write.format("postgres")
failed with - ClassNotFoundException: Failed to find data source: postgres. Please find packages
Option 2- We were trying low level pyspark API as suggested in spark-postgres-library ( ex- sc._jvm.io.frama.parisni.PGUtil) but
PGutil is not available in code as well
We tried with postgressql.driver as well but it didn’t work out
https://docs.databricks.com/external-data/postgresql.html
Regards,
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2023 12:28 AM
@Deepak U
It's hard to find an answer here without the proper monitoring of the entire process.
First of all, I would check how the workers behave during runtime (Ganglia - what's the overall usage of the workers, where's the bottleneck. It could be even more efficient to have a smaller number of more powerful nodes than multiple less powerful ones.
Second thing - networking. Maybe there's a bottleneck somewhere in there? Worth checking.
Third thing - Postgres instance - monitoring during the runtime.
Fourth thing - worth considering - exporting the data to Parquet files into storage, then using COPY FROM on Postgres to import the data. It's usually faster than using JDBC.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-18-2023 07:44 AM
Hi @Kaniz Fatma , @Daniel Sahal -
Few updates from my side.
After so many hits and trials , psycopg2 worked out in my case.
We can process 200+GB data with 10 node cluster (n2-highmem-4,32 GB Memory, 4 Cores) and driver 32 GB Memory, 4 Cores with Runtime10.4.x-scala2.12
It took close to 100 min to load whole data into PG .
Though we need to change parquet to csv and read csv sequentially to load into PG
like the below code snippet -
import psycopg2
# Create a connection to the PostgreSQL database
con = psycopg2.connect(database="dbname",user="user-nm",password="password",host="ip",port="5432")
# Create a cursor object
cur = con.cursor()
# Open the CSV file
files_to_load = dbutils.fs.ls("dbfs:/dir/")
while files_to_load:
file_path = files_to_load.pop(0).path
if file_path.endswith('.csv'):
file_path = file_path.replace("dbfs:","/dbfs")
print(file_path)
with open(file_path, "r") as f:
# Use the copy_from function to load the data into the PostgreSQL table
cur.copy_from(f, "pg_table_name", sep=",")
# Commit the changes
con.commit()
# Close the cursor and connection
con.close()
Few questions if you can assist
1- Is there any way we can tweak the code to read parquet data instead .csv data in above code (we have data originally in parquet format (databricks delta table) and if we can use same native format , we can cut down extra processing )
2- Is there any way we can run parallelly instead sequentially .
3- Any other tips which can boost the performance and take less time .
Regards,
Announcements





{kind=link}
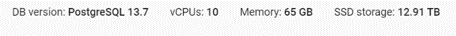{kind=link}
Related Content
- How to use/install a driver in Spark Declarative Pipelines (ETL)? in Data Engineering
- How to install SAP JDBC on job cluster via asset bundles in Data Engineering
- Cannot set spark.plugins com.nvidia.spark.SQLPlugin config in Data Governance
- NoClassDefFoundError: scala/Product Caused by: ClassNotFoundException: scala.Product in Data Engineering
- Databricks Kryo setup in Administration & Architecture