Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Hi All, I am trying to read a csv file from da...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
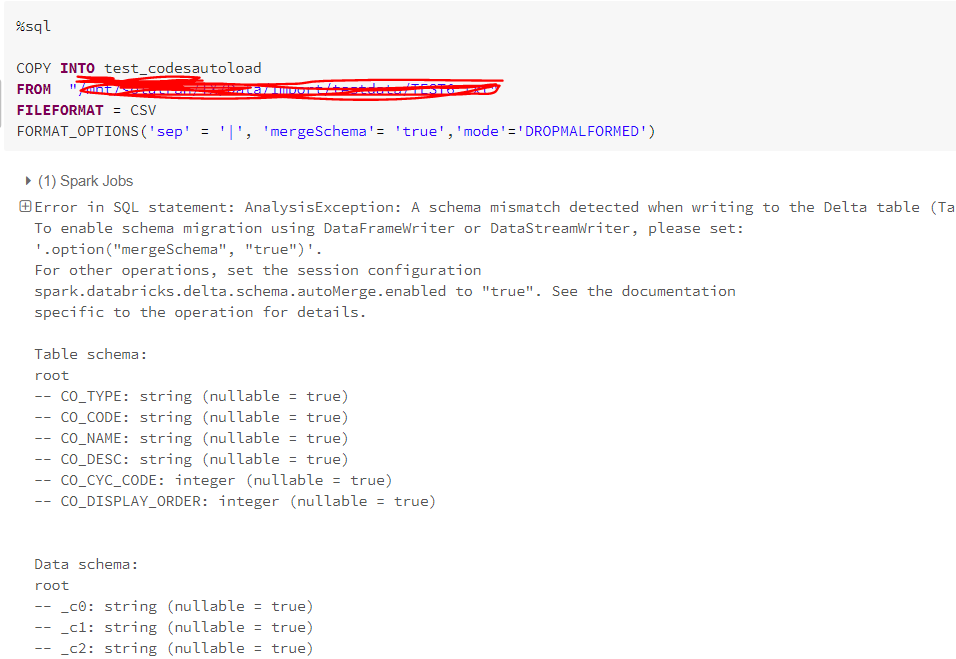
Hi All, I am trying to read a csv file from datalake and loading data into sql table using Copyinto. am facing an issue Here i created one table wit...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2021 04:55 AM
Hi All,
I am trying to read a csv file from datalake and loading data into sql table using Copyinto.
am facing an issue

Here i created one table with 6 columns same as data in csv file.
but unable to load the data.
can anyone helpme on this
Labels:
- Labels:
-
Sql table


8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2021 05:57 AM
one option is you can delete the underlying delta file or add mergeschema true while you are writing the delta table.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2021 06:01 AM
Thanks for quick response i added option mergeschema true still unable to load the data
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2021 01:37 AM
It looks like mergeschema is not active.
You can try to set the parameter active for the session with spark.databricks.delta.schema.automerge.enabled. That is for the whole sparksession.
A better solution is to pass a schema to your csv file (column names and types).
mergeSchema is pretty interesting , but it does not always work or give the results you want.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-11-2021 04:10 AM
Next thing you can do is if its a full load goto the underlying storage and delete the physical delta table and do a full reload. if you dont have too much time to research on options
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2021 09:58 PM
Thanks Werners for your Reply,
How to pass schema(ColumnName && Types) to CSV file ??
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2021 11:47 PM
That can be done directly in the SQL (with the COPY INTO function) or by using dataframes (classic way).
As you started out with SQL:
-- The example below loads CSV files without headers on ADLS Gen2 using COPY INTO.
-- By casting the data and renaming the columns, you can put the data in the schema you want
COPY INTO delta.`abfss://container@storageAccount.dfs.core.windows.net/deltaTables/target`
FROM (
SELECT _c0::bigint key, _c1::int index, _c2 textData
FROM 'abfss://container@storageAccount.dfs.core.windows.net/base/path'
)
FILEFORMAT = CSV
PATTERN = 'folder1/file_[a-g].csv'(Snippet from the Azure Docs)
There is also an 'inferSchema' option which will try to determine the schema itself (by reading the data twice). But the quality of the result varies, it might not give you the result you expected (doubleType instead of decimalType etc) and it is slower (because you read 2 times).
Using dataframes is similar, but you read the csv using pyspark/scala with a manually defined schema or inferSchema
(https://sparkbyexamples.com/spark/spark-read-csv-file-into-dataframe/)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-11-2021 04:55 AM
Thanks wernes for your quick response.
- Here i am having table with 6 columns but how to pass these 6 column names in select command SELECT _c0::bigint key, _c1::int index, _c2 textData
- you mean _c0,_C1 are the columns names ??
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2021 10:54 PM
_c0 etc are indeed column names. If you read a csv and do not define column names (or you read the file without header) those are the names.
Announcements





{kind=link}
Related Content
- How to properly restrict public network access on Azure Databricks Managed Root Storage? in Administration & Architecture
- [Lakeflow Spark Declarative Pipelines] - Compatibility Mode not working in Data Engineering
- API - Service Principle Secret Generation in Administration & Architecture
- MCPs not working properly in Generative AI
- Sync Tables: Unity Catalog to Lakebase - Materialized Views triggered mode in Data Engineering