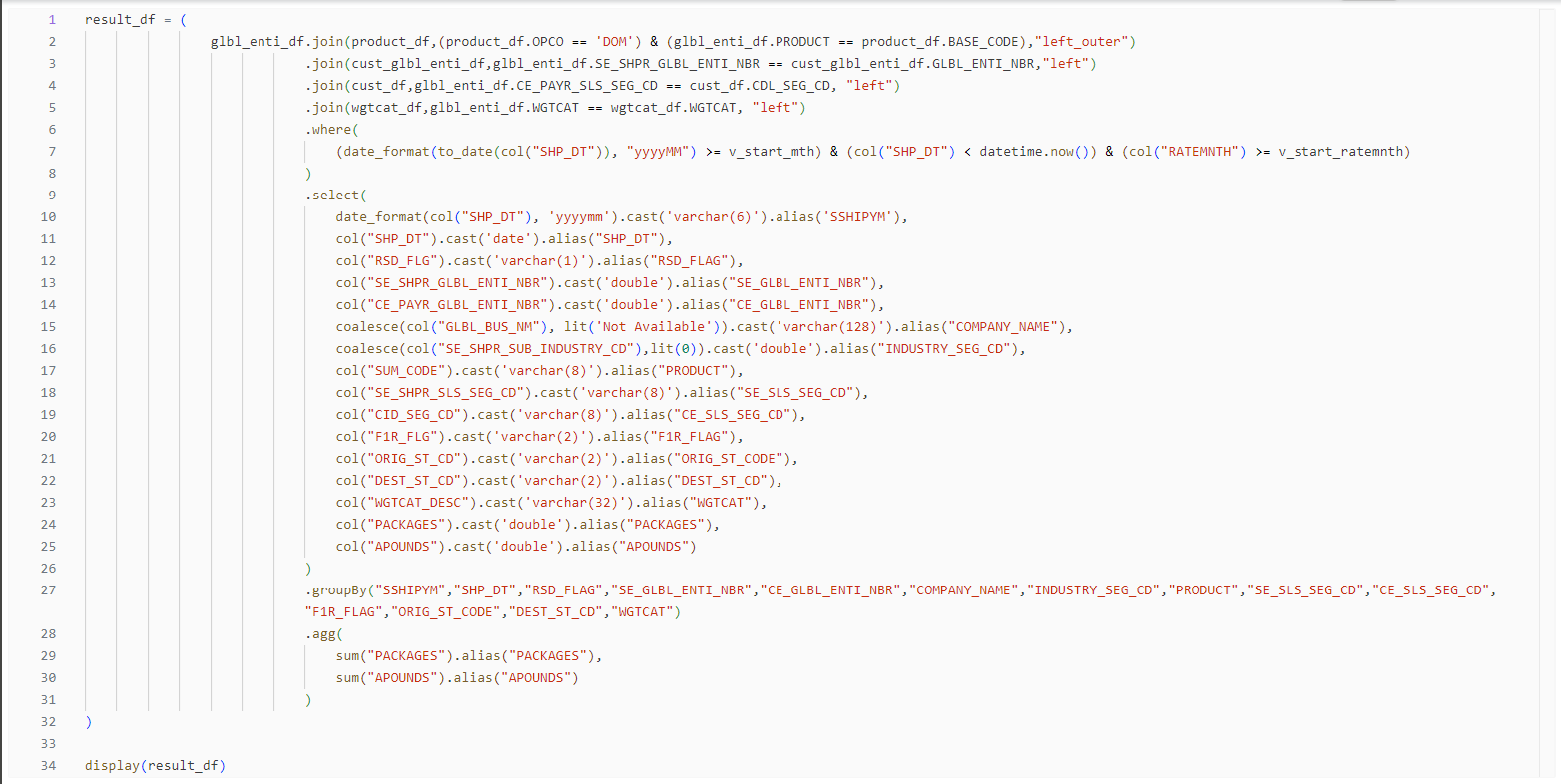
I have a notebook where I read multiple tables from delta lake (let say schema is db) and after that I did some sort of transformation (image enclosed) using all these tables lwith transformations like join,filter etc. After transformation and writing it to delta table, I am getting insight from databricks to use disk cache(image enclosed). In this scenario how can I use disk cache. I used
spark.conf.get("spark.databricks.io.cache.enabled","true") for disk cache but still getting the same insight.
Also, whenever I am trying to write the final DF to any table in delta lake getting the same insight that use disk cache.
How can I fix this. Is there any other optimization technique I can adapt rather than this.
Please check the image enclosed with it.







{kind=link}
{kind=link}