I have a total of 5000 files (Nested JSON ~ 3.5 GB). I have written a code which converts the json to Table in minutes (for JSON size till 1 GB) but when I am trying to process 3.5GB GZ json it is mostly getting failed because of Garbage collection. I have tried multiple clusters as well, still it is taking 18 minutes to read the file only and since it is a nested json it reads it only as a single record.
Please find the sample JSON Structure.
 Code snippet:
Code snippet:
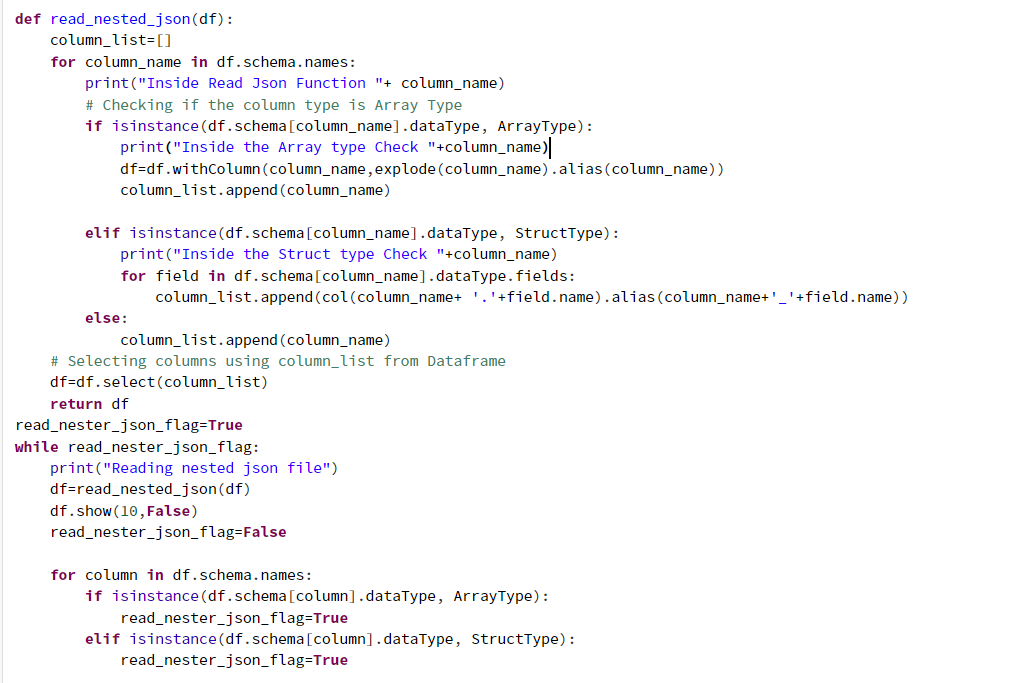
 Reading Code:
Reading Code:
 I am looking a way first to process one 3.5 GZ file and after that my focus will be working on 5000 similar files. I am searching for a way which will be more optimized and cost effective. Currently I am using Azure Databricks but I am open you use any other alternate technology as well.
I am looking a way first to process one 3.5 GZ file and after that my focus will be working on 5000 similar files. I am searching for a way which will be more optimized and cost effective. Currently I am using Azure Databricks but I am open you use any other alternate technology as well.







{kind=link}
{kind=link}
{kind=link}