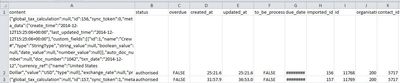
I have a csv file with the first column containing data in dictionary form (keys: value). [see below]
I tried to create a table by uploading the csv file directly to databricks but the file can't be read. Is there a way for me to flatten or conver...
This is apparently a known issue, databricks has their own csv format handler which can handle this
https://github.com/databricks/spark-csv
SQL API
CSV data source for Spark can infer data types:
CREATE TABLE cars
USING com.databricks.spark.csv
OP...
I found the answer here: https://stackoverflow.com/questions/54662605/how-to-pass-a-python-variables-to-shell-script-in-azure-databricks-notebookbles
basically:
%python
import os
l =['A','B','C','D']
os.environ['LIST']=' '.join(l)print(os.getenv('L...
I have a Databricks 5.3 cluster on Azure which runs Apache Spark 2.4.0 and Scala 2.11.I'm trying to parse a CSV file with a custom timestamp format but I don't know which datetime pattern format Spark uses.My CSV looks like this:
Timestamp, Name, Va...
# in python: explicitly define the schema, read in CSV data using the schema and a defined timestamp format....
<a href="http://thestoreguide.co.nz/auckland/orewa/mcdonalds-orewa-akl-0931/">McDonald’s in Orewa</a>
When I try to run the command
spark.sql("DROP TABLE IF EXISTS table_to_drop")
and the table does not exist, I get the following error:
AnalysisException: "Table or view 'table_to_drop' not found in database 'null';;\nDropTableCommand `table_to_drop...
I agree about this being a usability bug. Documentation clearly states that if the optional flag "IF EXISTS" is provided that the statement will do nothing.https://docs.databricks.com/spark/latest/spark-sql/language-manual/drop-table.htmlDrop Table ...
I am new to Spark and just started an online pyspark tutorial. I uploaded the json data in DataBrick and wrote the commands as follows:
df = sqlContext.sql("SELECT * FROM people_json")
df.printSchema()
from pyspark.sql.types import *
data_schema =...
Hi,
We got the following error when we tried to UPDATE a delta table running concurrent notebooks that all end with an update to the same table.
"
com.databricks.sql.transaction.tahoe.ConcurrentAppendException: Files were added matching 'true' by a ...
Hi @matt@direction.consulting
I just found the following doc https://docs.azuredatabricks.net/delta/isolation-level.html#set-the-isolation-level.
In my case, I could fixed partitioning the table and I think is the only way for concurrent update in t...
https://databricks.com/blog/2017/07/12/benchmarking-big-data-sql-platforms-in-the-cloud.html
Hi All,
just wondering why Databricks Spark is lot faster on S3 compared with AWS EMR spark both the systems are on spark version 2.4 , is Databricks have ...
I think you can get some pretty good insight into the optimizations on Databricks here:https://docs.databricks.com/delta/delta-on-databricks.html
Specifically, check out the sections on caching, z-ordering, and join optimization. There's also a grea...
I have read access to an S3 bucket in an AWS account that is not mine. For more than a year I've had a job successfully reading from that bucket using dbutils.fs.mount(...) and sqlContext.read.json(...). Recently the job started failing with the exc...
@andersource
Looks like the bucket is in us-east-1 but you've configured your AmazonS3 Cloud platform with us-west-2. Can you try switching configuring the client to use us-east-1 ?
I hope it will work for you. Thank you
exit(value: String): voidCalling dbutils.notebook.exit in a job causes the notebook to complete successfully. If you want to cause the job to fail, throw an exception.
I'm writing my output (entity) data frame into csv file. Below statement works well when the data frame is non-empty.
entity.repartition(1).write.mode(SaveMode.Overwrite).format("csv").option("header", "true").save(tempLocation)
It's not working wh...
the same problem here (similar code and the same behavior with Spark 2.4.0, running with spark submit on Win and on Lin)
dataset.coalesce(1)
.write()
.option("charset", "UTF-8")
.option("header", "true")
.mode(SaveMod...
Hi,
I am trying to split a record in a table to 2 records based on a column value. Please refer to the sample below. The input table displays the 3 types of Product and their price. Notice that for a specific Product (row) only its corresponding col...
Hi @rishigc
You can use something like below.
SELECT explode(arrays_zip(split(Product, '+'), split(Price, '+') ) as product_and_price from df
or
df.withColumn("product_and_price", explode(arrays_zip(split(Product, '+'), split(Price, '+'))).select(
...
i have a dataframe of 18000000rows and 1322 column with '0' and '1' value.
want to find how many '1's are in every column ???
below is DataSet
se_00001 se_00007 se_00036 se_00100 se_0010p se_00250
Hi Siddhu,
You can use
df.select(sum("col1"), sum("col2"), sum("col3"))
where col1, col2, col3 are the column names for which you would like to find the sum
please let us know if it answers your question
Thanks
Hi Community
I would like to know if there is an option to create an integer sequence which persists even if the cluster is shut down. My target is to use this integer value as a surrogate key to join different tables or do Slowly changing dimensio...
Hi @pascalvanbellen ,There is no concept of FK, PK, SK in Spark. But Databricks Delta automatically takes care of SCD type scenarios. https://docs.databricks.com/spark/latest/spark-sql/language-manual/merge-into.html#slowly-changing-data-scd-type-2
...
Well, just a little bit research, and i found this post below:
Hopefully this will help.
"
registerTempTable()
registerTempTable() creates an in-memory table that is scoped to the cluster in which it was created. The data is stored using Hive's high...