Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: how to add an identity column to an existing t...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 12:21 AM
I have created a database called retail and inside database a table is there called sales_order. I want to create an identity column in the sales_order table, but while creating it I am getting an error.
Labels:
- Labels:
-
Databricks SQL


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 11:44 PM
Thanks @Priya Ananthram , issue got solved
I used the same DBR
my job aborted issue got solved by using "try_cast" function while inserting the data from one table to the delta table. I used try_cast function for every column I was inserting.
11 REPLIES 11
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 01:57 AM
That is because you can't add an id column to an existing table.
Instead create a table from scratch and copy data:
CREATE TABLE tname_ (
<tname columns>,
id BIGINT GENERATED BY DEFAULT AS IDENTITY
);
INSERT INTO tname_ (<tname columns>) SELECT * FROM tname;
DROP TABLE tname;
ALTER TABLE tname_ RENAME TO tname;
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 04:29 AM
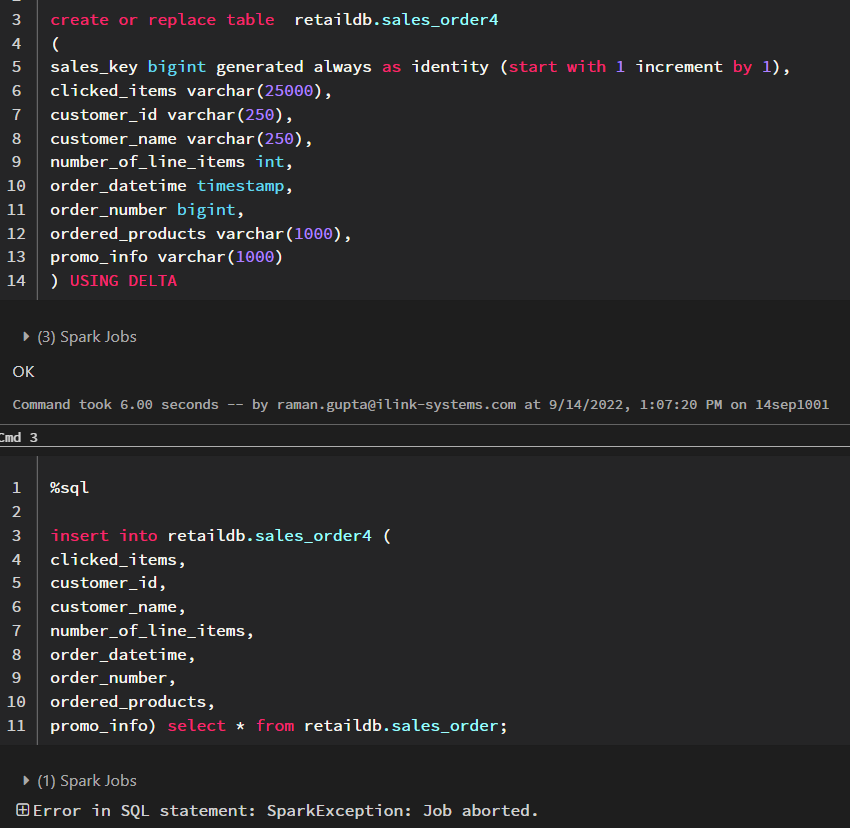
while creating a new table I'm getting an error like this:
Error in SQL statement: AnalysisException: Cannot create table ('`spark_catalog`.`retaildb`.`sales_order1`'). The associated location ('dbfs:/user/hive/warehouse/retaildb.db/sales_order1') is not empty but it's not a Delta table
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 04:41 AM
what databricks version do you use?
Only as from a certain version on, delta is the default format. So if you use an older release you should add 'using delta' (and I doubt in that case if the ID column will work)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 04:44 AM
I'm using community version
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 04:54 AM
It is possible that it is not supported with the CE.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-23-2022 02:46 PM
@Raman Gupta - For the error mentioned
Error in SQL statement: AnalysisException: Cannot create table ('`spark_catalog`.`retaildb`.`sales_order1`'). The associated location ('dbfs:/user/hive/warehouse/retaildb.db/sales_order1') is not empty but it's not a Delta tablecould you please manually clean up the data directory specified in the error message? using the below command and then try to create a table.
%scala
dbutils.fs.rm("<path-to-directory>", true)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 12:46 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 02:03 AM
above error is from community version.
and in azure version also it is showing the error.
i.e :
org.apache.spark.SparkException: Job aborted.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 03:58 PM
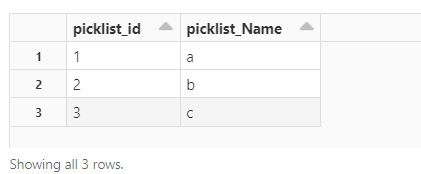
I just did this on the community cluster
%sql
create or replace table picklist
( picklist_id BIGINT not null GENERATED ALWAYS AS IDENTITY(start with 1 increment by 1),
picklist_Name string
)
insert into picklist(picklist_Name) values('a');
insert into picklist(picklist_Name) values('b');
insert into picklist(picklist_Name) values('c');
select * from picklist


Could you use the latest and see if that helps you
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 04:46 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 11:44 PM
Thanks @Priya Ananthram , issue got solved
I used the same DBR
my job aborted issue got solved by using "try_cast" function while inserting the data from one table to the delta table. I used try_cast function for every column I was inserting.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Five Unity Catalog ABAC Updates Worth Paying Attention To in Data Governance
- Stop Refreshing. Start Querying. in Data Engineering
- Issue with create_auto_cdc_flow Not Updating Business Columns for DELETE Events in Data Engineering
- Best pattern for ingesting data from hundreds of separate ADLS Gen2 containers into Databricks? in Data Engineering
- DEEP CLONE fails with [UNRESOLVED_ROUTINE] Cannot resolve routine isNotNull on DBR 16.4 in Data Engineering