Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How to setup an all-purpose cluster pool for all m...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to setup an all-purpose cluster pool for all my jobs?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-12-2022 05:52 AM
Today, we start working on setting up an all-purpose cluster pool for all the jobs that we are running on databricks. We used the documentation for this but we got some issues when running our jobs.
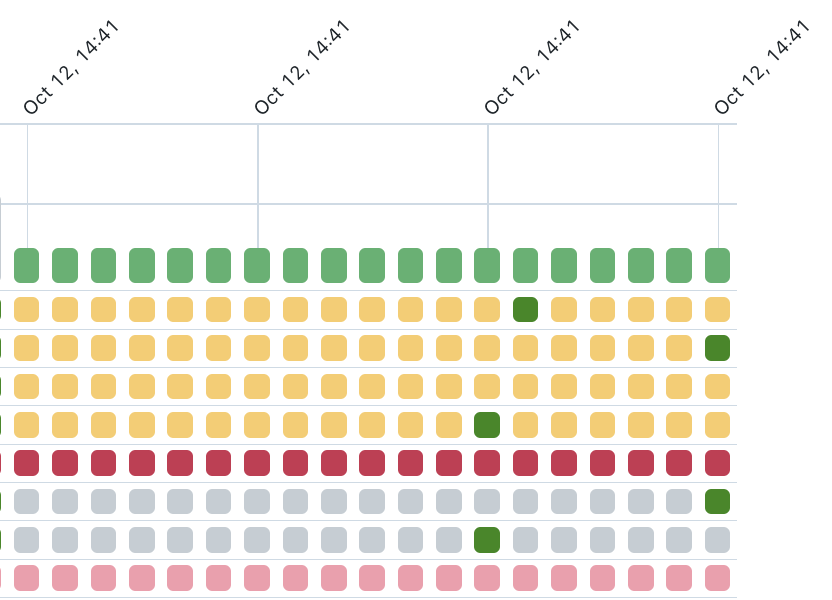
The errors in the jobs are the following:

The jobs are running in parallel. To give an explanation:

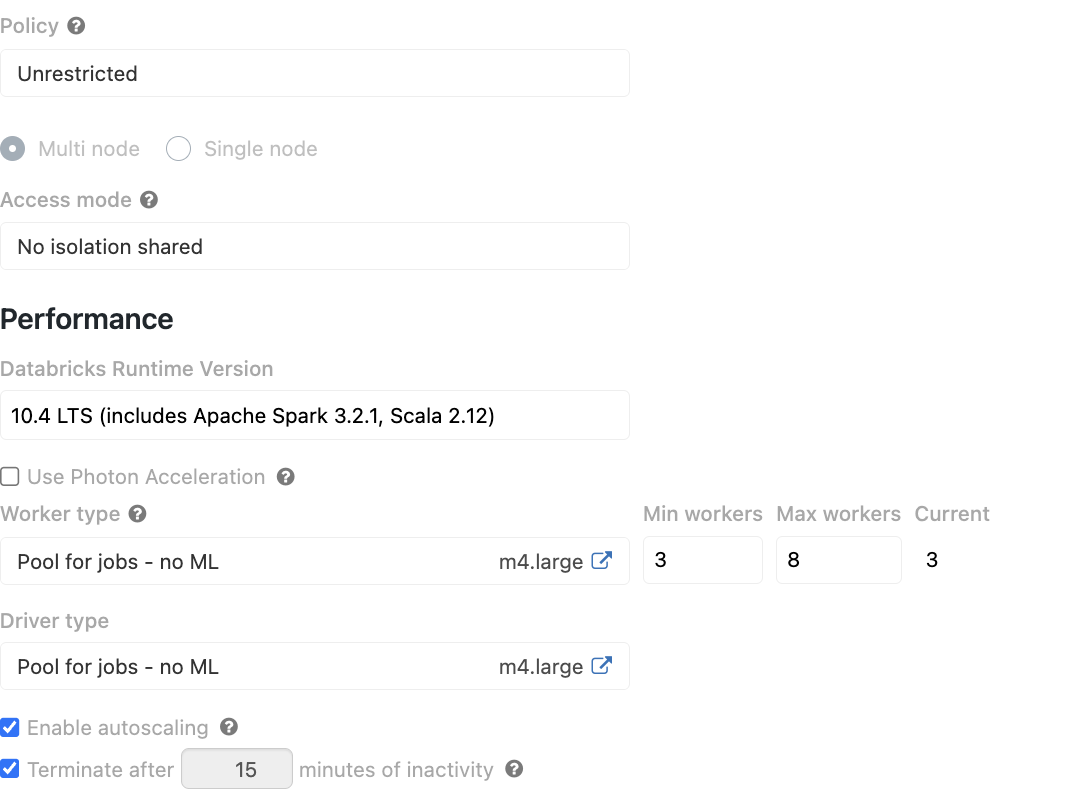
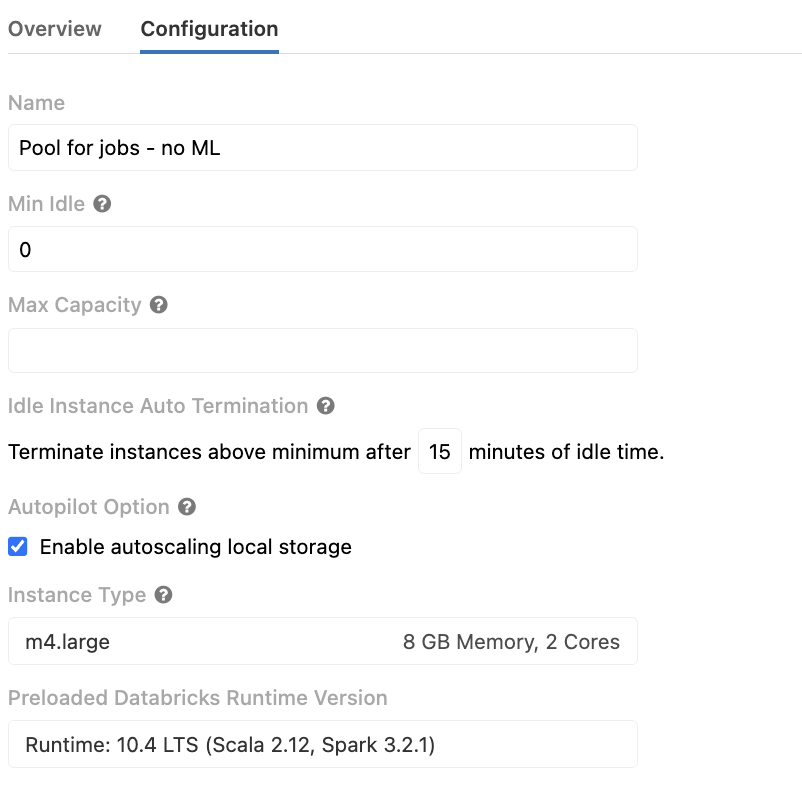
The pool has the following configuration:


Furthermore, I saw that the autoscaling didn't scale up, when doing multiple jobs at the same time. If running multiple jobs on the same pool, it should autoscale right?
Thanks for your time!


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-12-2022 10:12 AM
- Autoscaling goes up only when required by the size of the dataset etc. Another job will create a new cluster using idle machines from the pool and, if not idle, deploying new ones.
- So the pool is designed so that another job can reuse VMs. I see two strategies:
1) have min idle to set for some numbers, so machines are waiting to handle your job, and you reserve them to get a discount,
2) or just the opposite, have 0 idle and use spot instances,
- regarding errors, please check that you don't hit quotas in your service provider (for example, in portal azure, type quotas in the search box)
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-12-2022 10:49 AM
Thanks for the explanation!
What do I define for the cluster then? Because we have quite some jobs which are in parallel, should I define multiple clusters and set them in the pool or is there a better way to add multiple clusters to the pool? As per job there is a new cluster used.
Because the current situation is that we start a job cluster per job now and we are not reusing the job cluster and we would like to find a way to reuse the job cluster (I was thinking this was with the pool feature)
What does the 'Failure starting repl. ' error mean? So I can look a bit more in the direction on which quotas could be hit?
Thanks for taking the time to answer the question!
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-27-2022 04:49 AM
Hi @Siebert Looije
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-27-2022 10:54 PM
Hi @Vidula Khanna , thanks for reaching out. No I didn't really get a solution on this yet. I got some follow up questions, which were not really answered until now.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Cross-region S3 reads suddenly fail with 400 Bad Request — eu-west-1 metastore to af-south-1 bucket in Data Engineering
- Serverless Compute connectivity issues with .com.br domains vs. Classic Clusters Spark hangs in Data Engineering
- VNet Data Gateway unable to connect to Azure Databricks Serverless SQL via Private Endpoint in Administration & Architecture
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering
- Is it unusual that I need to start a compute cluster to sync with Git? in Data Engineering