I am using below code to create the Spark session and also loading the csv file. Spark session and loading csv is running well. However SQL query is generating the Parse Exception.
%python
from pyspark.sql import SparkSession
# Create a SparkSession
spark = (SparkSession
.builder
.appName("SparkSQLExampleApp")
.getOrCreate())
# Path to data set
csv_file = "dbfs:/mnt/Testing.csv"
# Read and create a temporary view
# Infer schema (note that for larger files you
# may want to specify the schema)
df = (spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.load(csv_file))
df.createOrReplaceTempView("US_CPSC_AEP_TBL")
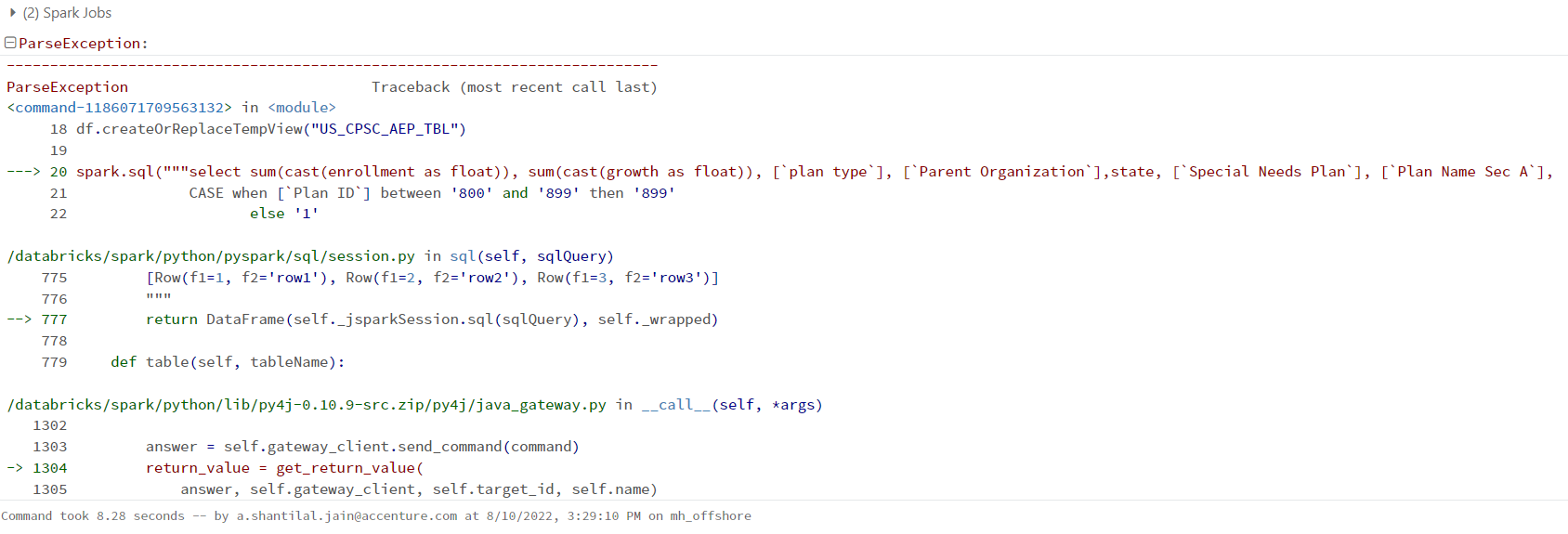
spark.sql("""select sum(cast(enrollment as float)), sum(cast(growth as float)), [plan type], [Parent Organization], state, [Special Needs Plan], [Plan Name Sec A],
CASE when [Plan ID] between '800' and '899' then '899'
else '1'
END as plan_id
FROM US_CPSC_AEP_TBL
WHERE [Plan Name Sec A] is not null
group by [Parent Organization],[plan type], state, [Special Needs Plan], [Plan Name Sec A],
CASE when [Plan ID] between '800' and '899' then '899'
else '1'
END
having sum(cast(enrollment as float)) = 0 and sum(cast(growth as float)) = 0""")








{kind=link}