Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: i am trying to read csv file using databricks,...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 01:40 AM



1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-24-2022 11:52 PM
Hi
you can try:
my_df = spark.read.format("csv")
.option("inferSchema","true") # to get the types from your data
.option("sep",",") # if your file is using "," as separator
.option("header","true") # if your file have the header in the first row
.load("/FileStore/tables/CREDIT_1.CSV")
display(my_df)
from above you can see that my_df is a spark dataframe and from there you can start with you code.
18 REPLIES 18
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 01:55 AM
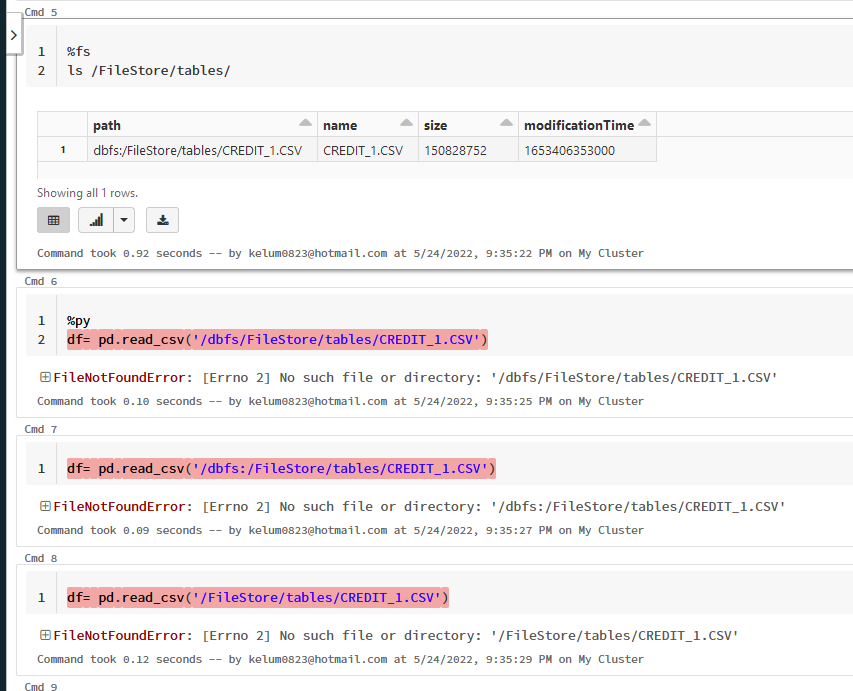
This means the path to the file you typed is not valid, the file is not there.
Can you check in the Data/DBFS page if the file is there (or via dbutils.fs.ls)?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 02:20 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-18-2022 09:54 AM
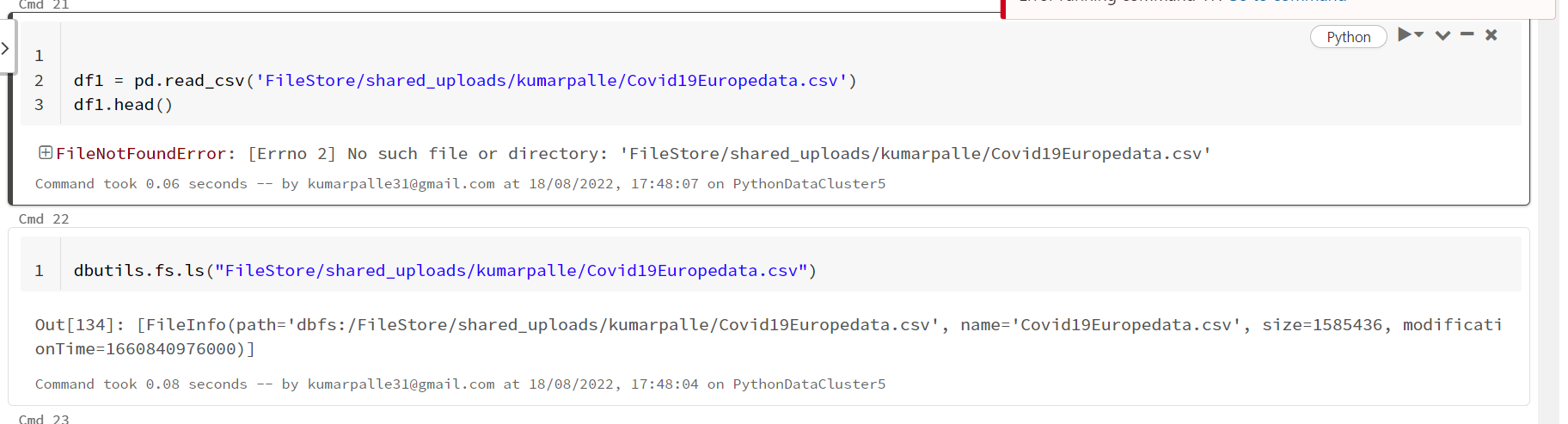
I am wondering how it worked for you. I have tried the same steps and no
luck. using dbutils i am finding file but when i read using pandas its saying no such file or directory exists.
dbutils.fs.ls("FileStore/shared_uploads/kumarpalle/Covid19Europedata.csv")

Please help here. uploaded the same file that am working on.
Also, please check if you have applied any settings that we are missing.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-18-2022 10:40 AM
Hi Kumar,
you're almost there, try this:
df1 = pd.read_csv("/dbfs/FileStore/shared_uploads/kumarpalle/Covid19Europedata.csv")
df1.describe()
Cheers!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-19-2022 03:00 AM
Hi @Alexis ,
Thanks for quick response. It above method didn't worked but reading using spark and appending to Pandas it worked.
Here are the steps that i followed.
df1 = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/shared_uploads/kumarpalle/Covid19Europedata-1.csv").toPandas()
df1.head()

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-19-2022 03:01 AM
@Venky D Please follow the above steps to read using Spark as pandas doesn't work through dbfs.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-03-2023 08:01 AM
same issue here... .toPandas() was also my only solution... otherwise error!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2023 08:46 AM
I did the same as you, but the reading does not work.

Can you help me? thanks
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 02:21 AM
Please help me on this error
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 02:36 AM
can you try without the dbfs part?
so /Filestore/tables/world_bank.csv
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 03:46 AM
it's not working
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-26-2021 03:57 AM
I see that you are using databricks-course-cluster which have probably some limited functionality. Not sure where dbfs is mounted there. When you are using dbutils it display path for dbfs mount (dbfs file system).
Please use spark code instead of pandas so it will be executed properly:
df = spark.read.csv('dbfs:/FileStore/tables/world_bank.csv')
display(df)My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-27-2021 07:17 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-24-2022 09:13 AM

Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Oracle Connectivity - CDC in Administration & Architecture
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Data Engineering
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Administration & Architecture
- Genie Code Usage Dashboard in Administration & Architecture
- Foreign Catalog Table - Missing Most Rows in Data Governance