Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Insert or merge into a table with GENERATED ID...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-17-2023 09:06 AM
Hi,
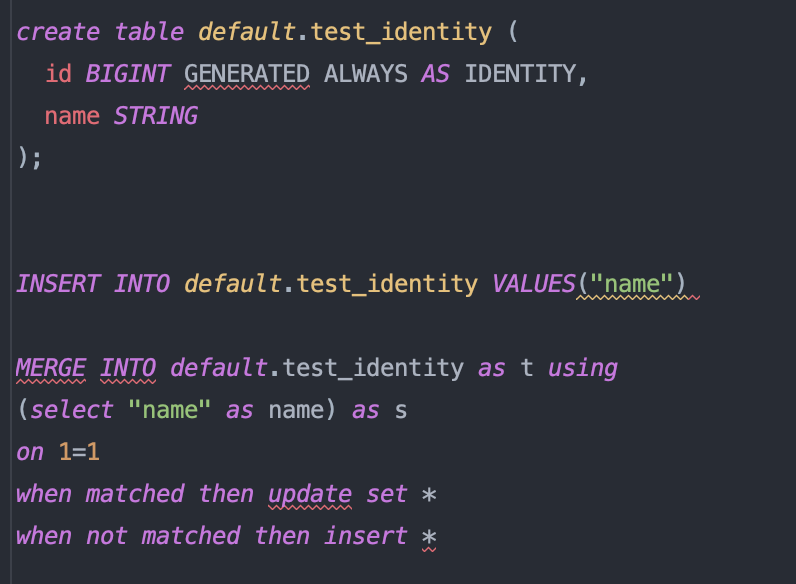
When I create an identity column using the GENERATED ALWAYS AS IDENTITY statement and I try to INSERT or MERGE data into that table I keep getting the following error message:
Cannot write to 'table', not enough data columns; target table has x column(s) but the inserted data has x-1 column(s)Shouldn't this work?


2 ACCEPTED SOLUTIONS
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 02:42 AM
To update all the columns of the target Delta table with the corresponding columns of the source dataset, use UPDATE SET *. This is equivalent to UPDATE SET col1 = source.col1 [, col2 = source.col2 ...] for all the columns of the target Delta table. Therefore, this action assumes that the source table has the same columns as those in the target table, otherwise the query will throw an analysis error."
So it will throw an error if they don't match exactly. Unless you have schema evolution enabled then this applies:
"A column in the target table is not present in the source table. The target schema is left unchanged; the values in the additional target column are either left unchanged (for UPDATE) or set to NULL (for INSERT)."
Its expected behaviour, UPDATE SET * seem to only want to ignore extra columns in the source.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2024 02:55 PM
You can run the INSERT by passing the subset of columns you want to provide values for... for example your insert statement would be something like:
INSERT INTO target_table_with_identity_col(<list-of-cols-names-without-the-identity-column>
SELECT(<list-of-col-value-without-the-identity-column>);
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 01:26 AM
Hi @Mrk Good day!
Please use below syntax while using GENERATED ALWAYS AS IDENTITY :
Step1: While creating table and defining column id as generated by always as identity mention the condition how id should be generated.
%sql
create table default.testidentityfinal (
id bigint generated always as identity(START WITH 1 INCREMENT BY 1),
name string
);
Step2: While inserting values into the table mention the column name under () for which you want to insert the values.
%sql
insert into default.testidentityfinal(name) values("Vinay")
I have also attached the snapshots of the notebook of internal repro along with the output for your reference.
Please let me know if this works.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 01:57 AM
Hi,
yes, this works, but I'm curious, why are "MERGE INTO ... UPDATE SET *" and "INSERT INTO table SELECT * from source" failing? Is there some kind of internal field name resolution issue?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-18-2023 02:42 AM
To update all the columns of the target Delta table with the corresponding columns of the source dataset, use UPDATE SET *. This is equivalent to UPDATE SET col1 = source.col1 [, col2 = source.col2 ...] for all the columns of the target Delta table. Therefore, this action assumes that the source table has the same columns as those in the target table, otherwise the query will throw an analysis error."
So it will throw an error if they don't match exactly. Unless you have schema evolution enabled then this applies:
"A column in the target table is not present in the source table. The target schema is left unchanged; the values in the additional target column are either left unchanged (for UPDATE) or set to NULL (for INSERT)."
Its expected behaviour, UPDATE SET * seem to only want to ignore extra columns in the source.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2024 02:55 PM
You can run the INSERT by passing the subset of columns you want to provide values for... for example your insert statement would be something like:
INSERT INTO target_table_with_identity_col(<list-of-cols-names-without-the-identity-column>
SELECT(<list-of-col-value-without-the-identity-column>);
Announcements





{kind=link}
{kind=link}
Related Content
- Genie PDF export corrupts non-ASCII characters (Polish diacritics ł, ż, ś, ź, ę, ą) in Generative AI
- Automatic Identity Management in Administration & Architecture
- Spark JDBC Write Fails for Record Not Present - PK error in Data Engineering
- Lakebridge conversion tool: Incorrect Databricks SQL script generated in Data Engineering
- Best practices : Silver Layer to Salesforce in Data Engineering