Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Model Training Data Adapter Error.
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Model Training Data Adapter Error.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2022 10:52 AM
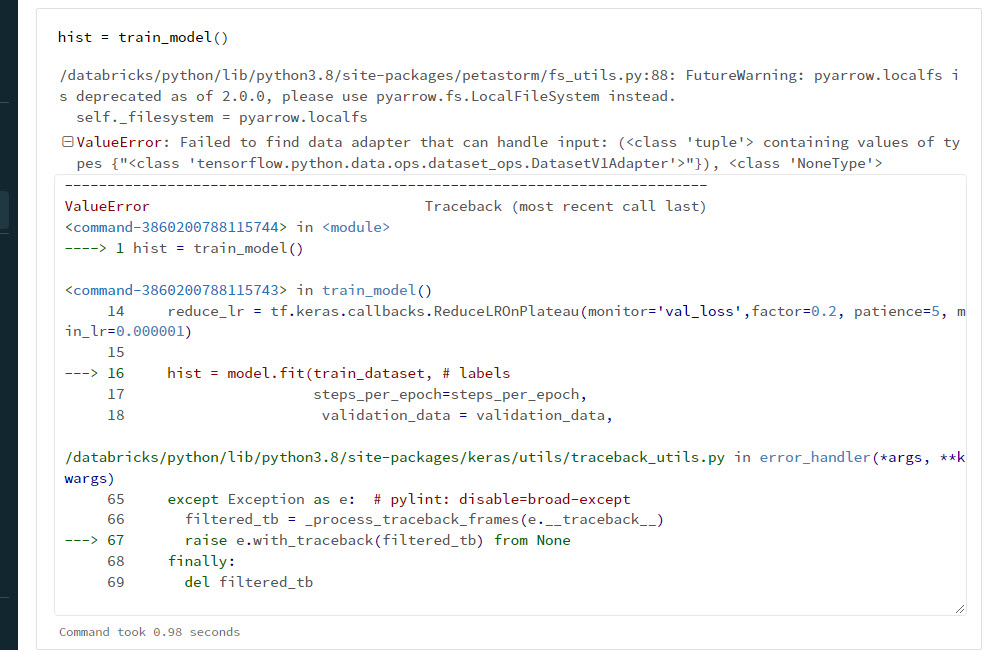
We are converting Pyspark dataframe to Tensorflow using PetaStorm and have encountered a “data adapter” error. What do you recommend for diagnosing and fixing this error?
https://docs.microsoft.com/en-us/azure/databricks/applications/machine-learning/load-data/petastorm


Thanks for help
Labels:
- Labels:
-
Petastorm
-
Tensor flow


5 REPLIES 5
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2022 06:00 AM
Hi @Nathan Law following up did you get a chance to check @Kaniz Fatma 's previous comments ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2022 06:30 AM
Hi,
From the Petastorm example:
# Make sure the number of partitions is at least the number of workers which is required for distributed training.
I am testing an recommendation to not use Autoscaling. I'll report back with findings.
- Nathan
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2022 08:05 AM
Hey there @Nathan Law
Hope all is well!
Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? It would be really helpful for the other members too.
We'd love to hear from you.
Cheers!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2022 08:24 AM
Making progress but still working through issues. I'll post findings when completed.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2022 08:35 AM
Hey @Nathan Law
Thank you so much for getting back to us. We will await your response.
We really appreciate your time.
Announcements





{kind=link}
{kind=link}
Related Content
- SPOG discovery probe failed in Administration & Architecture
- Databricks Training - DNS Issue? in Administration & Architecture
- How to Prepare Enterprise Data for AI Agents: A Practical Guide in Data Engineering
- AutoML on Azure Databricks as of June 2026 in Machine Learning
- Data bricks + Network security perimeter (storage account) Error in Data Engineering