Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: need to remove doubledagger delimiter from a c...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2022 11:41 AM
My csv data looks like this
‡‡companyId‡‡,‡‡empId‡‡,‡‡regionId‡‡,‡‡companyVersion‡‡,‡‡Question‡‡
I tried this code
dff = spark.read.option("header", "true").option("inferSchema", "true").option("delimiter", "‡,").csv(f"/mnt/data/path/datafile.csv")
But I am getting space after each characters in between my results
�� ! ! c o m p a n y I d ! ! , ! ! e m p I d ! ! , ! ! r e g i o n I d ! ! , ! !
please help


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 10:04 AM
Hi @shamly pt
It's a indentation error. Check if you are following proper indentation.
I guess your error is at if columnLabel != newColumnLabel:
dff = dff.drop(columnLabel).
Just hit a Tab or give indentation spaces before dff = dff.drop(columnLabel)
cheers..
Uma Mahesh D
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2022 12:04 PM
You can include a sample of your CSV as an attachment in CSV format would be easier.
Maybe it is enough to add space in delimiter .option("delimiter", "‡, ").
Another option is to use external applications to purge chars from CSV.
We can also load the whole line into a dataframe and split it using spark SQL string functions https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/functions.html#string-function...
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2022 12:30 PM
Hi @shamly pt
I took a bit another approach since I guess no one would be sure of the the encoding of the data you showed.
Sample data I took :
‡‡companyId‡‡,‡‡empId‡‡,‡‡regionId‡‡,‡‡companyVersion‡‡,‡‡Question‡‡
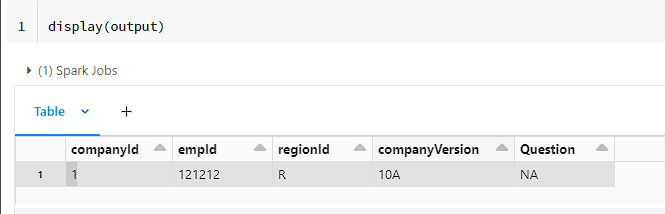
‡‡1‡‡,‡‡121212‡‡,‡‡R‡‡,‡‡1.0A‡‡,‡‡NA‡‡
My approach:
First reading that data as is turning off header and sep as ','. Just renamed _c0 to col1 for visual purpose. Then created a split column, separated the values and regex replaced the data. Finally filtered out the row which contained header as I already aliased the dataframe.
dff = spark.read.option("header", "false").option("inferSchema", "true").option("sep",",").csv("/FileStore/tables/Book1.csv").withColumnRenamed("_c0", "col1")
split_col = pyspark.sql.functions.split(dff['col1'], ',')
df2 = dff.select(regexp_replace(split_col.getItem(0), "[^0-9a-zA-Z_\-]+", "").alias('companyId'),\
regexp_replace(split_col.getItem(1), "[^0-9a-zA-Z_\-]+", "").alias('empId'), \
regexp_replace(split_col.getItem(2), "[^0-9a-zA-Z_\-]+", "").alias('regionId'), \
regexp_replace(split_col.getItem(3), "[^0-9a-zA-Z_\-]+", "").alias('companyVersion'), \
regexp_replace(split_col.getItem(4), "[^0-9a-zA-Z_\-]+", "").alias('Question')) \
output = df2.where(df2.companyId != 'companyId')My output:

Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2022 10:48 PM
Dear @Uma Maheswara Rao Desula Thanks for your help. I am able to split into columns.I have almost 90 columns. So, is there any way that I can automate?
I tried below code, but it is not giving clean seperated columns as ur code.
dff = spark.read.option("header", "true").option("inferSchema", "true").option("delimiter", "‡‡,‡‡").csv(filepath)
dffs_headers = dff.dtypes
for i in dffs_headers:
columnLabel = i[0]
newColumnLabel = columnLabel.replace('‡‡','').replace('‡‡','')
dff = dff.withColumn(newColumnLabel, regexp_replace(columnLabel, '^\\‡‡|\\‡‡$', ''))
if columnLabel != newColumnLabel:
dff = dff.drop(columnLabel)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2022 01:19 AM
Hi @shamly pt
May I know what was the data mismatch issue you were facing using the previous code ?
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2022 02:23 AM
Hi @Uma Maheswara Rao Desula There was no data match issues. It was my mistake in validating data. Data is coming perfectly. The problem is I have 90 columns. So is there any way to reduce manual effort something like below ?
for i in dffs_headers:
columnLabel = i[0]
newColumnLabel = columnLabel.replace('‡‡','').replace('‡‡','')
dff = dff.withColumn(newColumnLabel, regexp_replace(columnLabel, '^\\‡‡|\\‡‡$', ''))
if columnLabel != newColumnLabel:
dff = dff.drop(columnLabel)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2022 03:04 AM
Hi @shamly pt ,
As an automated way if you don't know the schema beforehand would look something like this...
dff_1 = spark.read.option("header", "false").option("inferSchema", "true").option("sep",",").csv("/FileStore/tables/Book1.csv").withColumnRenamed("_c0", "col1")
split_col = pyspark.sql.functions.split(dff_1['col1'], ',')
# Building the header field names
header_uncleaned = (spark.read.option("header", "true").option("inferSchema", "true").option("sep",",").csv("/FileStore/tables/Book1.csv").columns[0]).split(",")
header = []
for i in header_uncleaned:
header.append(''.join(e for e in i if e.isalnum()))
# Looping over the column names and populating data
dff_1 = df1
for i in range(len(header)):
print(i)
df1 = df1.withColumn(header[i], regexp_replace(split_col.getItem(i), "[^0-9a-zA-Z_\-]+", ""))
df1 = df1.drop("col1").filter(col("companyId") != "companyId")
display(df1)
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 09:57 AM
Hi @Uma Maheswara Rao Desula
I have written this code, as I have many files in many folders in same location and everything is UTF-16. This is giving me proper result as below
dff = spark.read.option("header", "true") \
.option("inferSchema", "true") \
.option('encoding', 'UTF-16') \
.option('multiline', 'true') \
.option("delimiter", "‡‡,‡‡") \
.csv("/mnt/data/file.csv")
display(dff)
‡‡CompanyId Companyname CountryId‡‡
‡‡1234 abc cn‡‡
‡‡2345 def us‡‡
‡‡3457 ghi sy‡‡
‡‡7564 lmn uk‡‡
Now, I want to remove the start and end double daggers and I wrote below code and it is giving me error "IndentationError: expected an indented block"
from pyspark.sql.functions import regexp_replace
dffs_headers = dff.dtypes
for i in dffs_headers:
columnLabel = i[0]
newColumnLabel = columnLabel.replace('‡‡','').replace('‡‡','')
dff = dff.withColumn(newColumnLabel, regexp_replace(columnLabel, '^\\‡‡|\\‡‡$', ''))
if columnLabel != newColumnLabel:
dff = dff.drop(columnLabel)
display(dff)
error "IndentationError: expected an indented block"
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 10:04 AM
Hi @shamly pt
It's a indentation error. Check if you are following proper indentation.
I guess your error is at if columnLabel != newColumnLabel:
dff = dff.drop(columnLabel).
Just hit a Tab or give indentation spaces before dff = dff.drop(columnLabel)
cheers..
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 10:56 AM
Thankyou it worked 🙂
Announcements





{kind=link}
Related Content
- Bug Report: SDP (DLT) with autoloader not passing through pipe delimiter/separator in Data Engineering
- create a one off job run using databricks SDK. in Data Engineering
- Getting error while using Live.target_table in dlt pipeline in Data Engineering
- Old files also getting added in dlt autoloader in Data Engineering
- OutputMode “complete” unable to replace the entire table in Data Engineering