Hi @Bartosz Maciejewski
Generally we arrive at the number of shuffle partitions using the following method.
Input Size Data - 100 GB
Ideal partition target size - 128 MB
Cores - 8
Ideal number of partitions = (100*1028)/128 = 803.25 ~ 804
To utiltize the cores available properly especially in the last iteration, the number of shuffle partitions should be a factor of the core count else we would not be using the cores properly. Giving too few partition will lead to less concurrency and too many will lead to lots of shuffle.
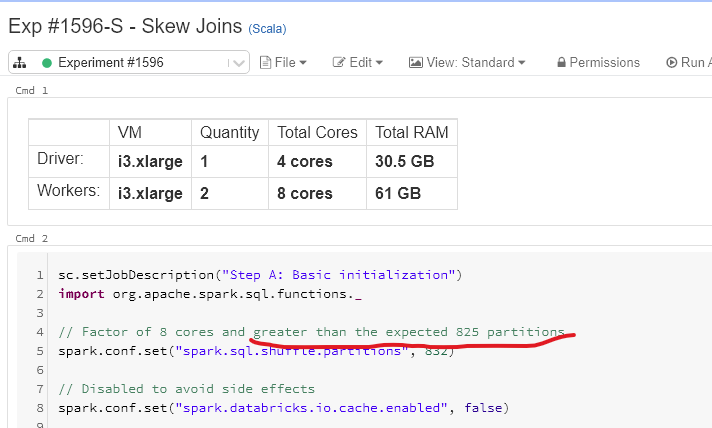
As for the above example you are referring to, if you calculate ideal number of partitions giving the proper input data size and desired target size (64 MB or 128 MB or whatever below 500 MB), it should come around 825.
Now factor of 8 cores near to 825 is either 824 or 832. If you gave 824, then last iteration would be allocated to the 825th partition alone where 7 out of 8 cores would be idle. So we are going with the next factor which is 832, which has a optimum utilization of all the cores available.
Hope this helps...Do comment if you have any query..
Cheers.
Uma Mahesh D








{kind=link}