Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- On-Premise SQL Server Ingestion to Databricks Bron...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-30-2023 12:18 PM
Hello everyone!
So I want to ingest tables with schemas from the on-premise SQL server to Databricks Bronze layer with Delta Live Table and I want to do it using Azure Data Factory and I want the load to be a Snapshot batch load, not an incremental load. What are the activities I will have to use in ADF?
Labels:
- Labels:
-
Azure databricks
-
Delta Live Tables
-
SQL


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-30-2023 09:35 PM
@Parsa Bahraminejad
You'll need to use ADF Copy Activity to fetch the data from SQL Server to ADLS (Storage) in parquet format. Then you can simply ingest the data from ADLS (Raw Layer) to bronze using autoloader or spark.read.format("parquet").
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-30-2023 09:35 PM
@Parsa Bahraminejad
You'll need to use ADF Copy Activity to fetch the data from SQL Server to ADLS (Storage) in parquet format. Then you can simply ingest the data from ADLS (Raw Layer) to bronze using autoloader or spark.read.format("parquet").
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-31-2023 08:30 PM
Thank you!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2023 01:06 AM
Hi, could you give me specific script to ingest the data from ADLS (.parquet) to delta table using autoloader? I am not able to do that. I tried everything I could, but I get error all the time in my notebook when I am trying to set up the script (autoloader).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2023 02:55 PM
can you please share the error you are facing?
Example scripts
https://learn.microsoft.com/en-us/azure/databricks/getting-started/etl-quick-start
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2023 08:25 AM
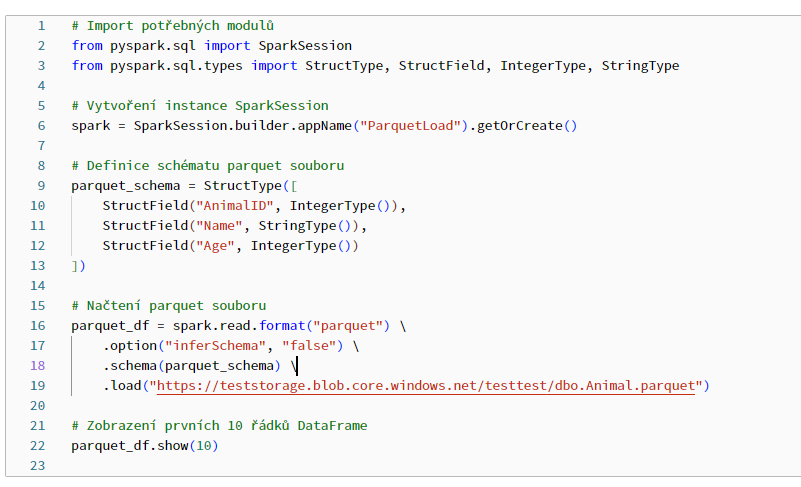
Sure, first error which popped up was (code from notebook below in screenshot):
AnalysisException: Incompatible format detected. A transaction log for Delta was found at `https://teststorage.blob.core.windows.net/testtest/dbo.Animal.parquet/_delta_log`, but you are trying to read from `https://teststorage.blob.core.windows.net/testtest/dbo.Animal.parquet` using format("parquet"). You must use 'format("delta")' when reading and writing to a delta table. To disable this check, SET spark.databricks.delta.formatCheck.enabled=false To learn more about Delta, see https://docs.microsoft.com/azure/databricks/delta/index
I tried to fix it like "delta_df = spark.read.format("parquet") --> delta_df = spark.read.format("delta")"
Its dropped:
File /databricks/spark/python/pyspark/instrumentation_utils.py:48, in _wrap_function.<locals>.wrapper(*args, **kwargs) 46 start = time.perf_counter() 47 try: ---> 48 res = func(*args, **kwargs) 49 logger.log_success( 50 module_name, class_name, function_name, time.perf_counter() - start, signature 51 )
But I am not sure I do it in right way. Trying to finish my project and I made it through copy data pipeline, but I want to change into autoloader and storage data in delta table.
Thanks in advance.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-31-2023 08:18 PM
Hi @Parsa Bahraminejad
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?
This will also help other community members who may have similar questions in the future. Thank you for your participation and let us know if you need any further assistance!
Announcements





{kind=link}
Related Content
- Zerobus ingestion fails in Databricks Free Edition using Service Principal OAuth in Administration & Architecture
- How to promote Lakeflow Connect and Spark Declarative Pipeline to a higher environment in Data Engineering
- Streaming Amazon DocumentDB to Databricks in near real time - what's the best approach? in Data Engineering
- Ingest data from snowflake to databricks in Data Engineering
- PostgreSQL ingestion source not supported in workspace when deploying Databricks Asset Bundle in Data Engineering