Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Permanently add python file path to sys.path in Da...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2022 02:56 PM
If your notebook is in different directory or subdirectory than python module, you cannot import it until you add it to the Python path.
That means that even though all users are using the same module, but since they are all working from different repos, they cannot import it until they add the path.
I wonder maybe it is possible to add module file path to Databricks sys.path permanently or until the file is deleted.
Labels:
- Labels:
-
Python


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-22-2022 10:53 AM
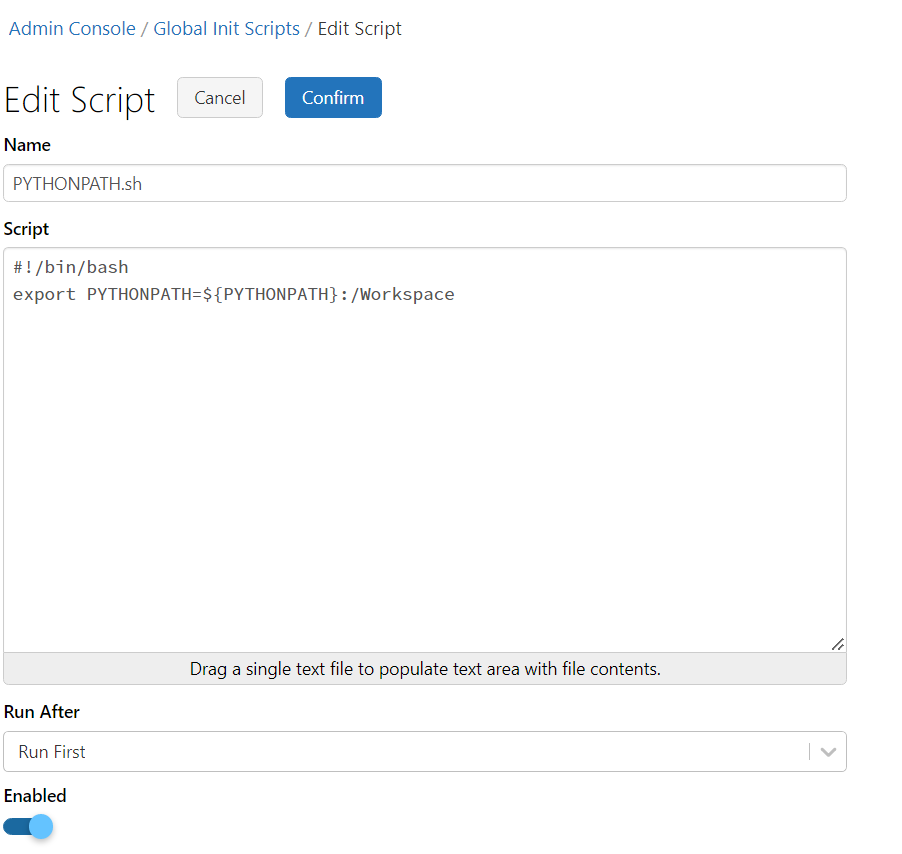
You can use it inside the same repo. Provide a whole path from the highest repo level in any notebook inside the repo. As you mentioned, if the file is in another repo, you need to use sys.path.append. To make it permanent, you can try to edit global init scripts.

from directory.sub_directory.my_file import MyClass
"""
Repo
-------\directory
------------------\sub_directory
-------------------------------------\my_file
"""My blog: https://databrickster.medium.com/
10 REPLIES 10
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-22-2022 10:53 AM
You can use it inside the same repo. Provide a whole path from the highest repo level in any notebook inside the repo. As you mentioned, if the file is in another repo, you need to use sys.path.append. To make it permanent, you can try to edit global init scripts.
from directory.sub_directory.my_file import MyClass
"""
Repo
-------\directory
------------------\sub_directory
-------------------------------------\my_file
"""My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-15-2022 05:15 PM
@Direo Direo you can refer to this. The feature is now public preview.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-13-2022 04:20 AM
Hi, the init_script doesn't work for me (worker's pythonpath doesn't get affected).
and the suggested options in the above link don't help either.
is there a way to add another folder to the PYTHONPATH of the workers?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-25-2022 02:21 PM
For worker node, you can set spark config in cluster setting: spark.executorEnv.PYTHONPATH
However you need to make sure you append your Workspace path at the end as worker node needs other system python path.
This seems to be a hack to me. I hope databricks can respond with a more solid solution.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-25-2022 11:12 PM
setting the `spark.executorEnv.PYTHONPATH` did not work for me. it looked like Spark/Databricks overwrite this somewhere. I used a simple python UDF to print some properties like `sys.path` and `os.environ` and didn't see the path I added.
Finally, I found a hacky way of using `spark._sc._python_includes`.
you can see my answer to my self here
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-26-2022 05:55 AM
Thanks @Ohad Raviv . I will try your approach.
spark.executorEnv.PYTHONPATH works only for worker node not driver node. And it needs to set at the cluster initialization stage (under Spark tab). After cluster initialized, databricks overwrite it even if you manually do spark.conf.set.
I prefer setting environment not thru code as codying it breaks the code integrity. It is hard to enforce it when multiple people working on the same cluster. I wish there is a better way in databricks cluster screen, it allows users to append sys.path after the default; or allow people to do editable install (pip install -e) during development.
I checked the worker node PYTHONPATH using the following to make sure it gets appended.
def getworkerenv():
import os
return(os.getenv('PYTHONPATH'))
sc = spark.sparkContext
sc.parallelize([1]).map(lambda x: getworkerenv()).collect()
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-26-2022 09:21 AM
the hacky solution above is meant to be used only while developing my own python module - this way I can avoid packaging a whl, deploying to the cluster, restarting the cluster and even restarting the notebook interpreter.
I agree that it is not suited for production. For that I would use either a whl ref in the workflow file or just prepare a docker image.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-28-2022 11:25 PM
To be honest I'm just inspecting which repo folder I'm running from (dev/test/prod) and sys.path.appending an appropriate path before importing my packages. Seems to work and its covered by the Terraform provider.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-29-2022 08:29 AM
The issue with that is that the driver's sys.path is not added to the executors' sys.path, and you could get "module not found" error if your code tries to import one of your modules.
but it will work fine for simple code that is self-contained.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-29-2022 01:14 PM
I've been successfully using this in Delta Live Table pipelines with many nodes. Seems to work for my use case.
Announcements





{kind=link}
Related Content
- GDPR/CCPA Compliance Delete for PII data in Data Governance
- scroll bar disappears on widgets in dashboards in Administration & Architecture
- Accessing permanent file system from Databricks App in Data Governance
- Is it possible to retain original deltatable data with Unity Catalog? in Data Engineering
- Deletion of Resource Group on Azure and Impact on Databricks Workspace in Data Engineering