Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: pySpark Dataframe to DeepLearning model
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2022 10:11 AM
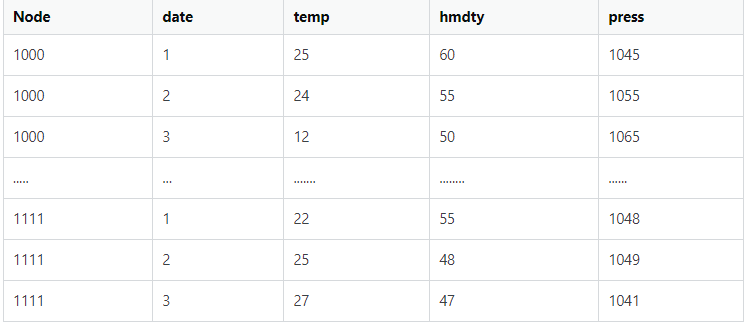
I have a large time series with many measuring stations recording the same 5 data (Temperature, Humidity, etc.) I want to predict a future moment with a time series model, for which I pass the data from all the measuring stations to the Deep Learning model. E.g. I have 100 days of recorded data, in which I have 1000 measuring stations, and each of them has 5 data. My spark table looks something like this:

How can I efficiently transpose my data using Spark and Pandas to something like this structure?

Sample code:
import pandas as pd
import random
import spark
data = []
for node in range(0,100):
for day in range(0,100):
data.append([str(node),
day,
random.randrange(15, 25, 1),
random.randrange(50, 100, 1),
random.randrange(1000, 1045, 1)])
df = spark.createDataFrame(data,['Node', 'day','Temp','hum','press'])
display(df)I don't process the data as a whole, but I use a period between two dates, say 10, 20, or 30 time instants.
A simple solution, like packing everything into memory... I can do it, but I don't know how to use it efficiently. My original dataset is a parquet of 8 columns and 6million rows (2000 NODE), so if I load it all into memory and transform it that way, I would get a 30,000 row (time) and 2000 * 8 columns table in memory.
So my question is how to load and transform such data effectively. I have parquet data on the disk and I load it to the machine with spark. I will pass the processed data to a Deep Learning model.
Labels:
- Labels:
-
Dataframe
-
Deep learning


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2022 11:02 AM
df.groupBy("date").pivot("Node").agg(first("Temp"))It is converting to classic crosstable so pivot will help. Example above.
My blog: https://databrickster.medium.com/
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2022 11:02 AM
df.groupBy("date").pivot("Node").agg(first("Temp"))It is converting to classic crosstable so pivot will help. Example above.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-08-2022 12:21 PM
I am not really sure how this solves my problem. Will this solve the memory overload problem and will the model get the right data? Besides, if you filter the data by timestamps on the
spark, it slows down the data processing very much..... Is there some kind of generator for spark like the Keras data generator?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-10-2022 12:39 AM
Thank you I have made a solution based on your idea.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-10-2022 05:26 AM
great. Can you select my answer as the best one?
My blog: https://databrickster.medium.com/
Announcements





{kind=link}
{kind=link}
Related Content