Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Random error: At least one column must be specifie...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Random error: At least one column must be specified for the table?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-02-2022 09:25 AM
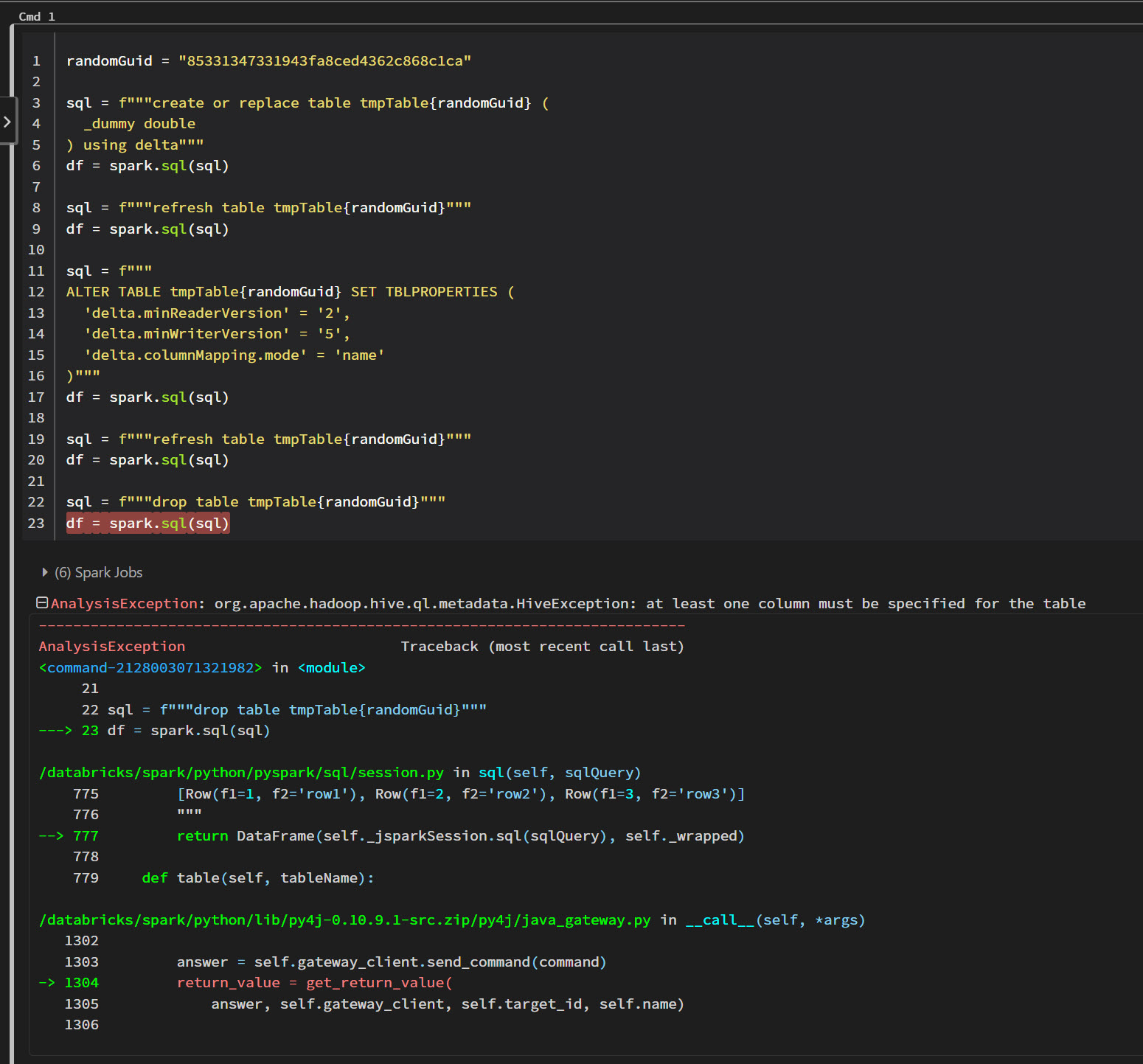
I have the following code in a notebook. It is randomly giving me the error, "At least one column must be specified for the table." The error occurs (if at all it occurs) only on the first run after attaching to a cluster.
Cluster details:
Summary
5-10 Workers
320-640 GB Memory40-80 Cores1 Driver
64 GB Memory, 8 Cores Runtime
10.4.x-scala2.12 Apache Spark 3.2.1

Any ideas?
Labels:
- Labels:
-
Apache spark
-
Random Error


11 REPLIES 11
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2022 01:03 AM
Create a support request databricks might help you in this issue.
Ajay Kumar Pandey
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-07-2022 08:39 AM
The issue occurs randomly. The challenge is to recreate the issue for the support team to look. I am hoping that the folks who have experienced similar error, would comment, and then maybe the DBR folks would have something to investigate.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-28-2022 04:20 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-28-2022 06:09 AM
Sorry, no solution yet.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 09:53 AM
I tried reproducing the issue in Databricks notebook, using 10.4 cluster and ran a few times. Unfortunately couldn't reproduce the issue. It runs successfully during each run. What is the frequency of this intermittent issue? If you re-run the command 10 times would it throw error once? Still would recommend to file a support ticket , so that we can take a deeper look at this.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:28 AM
So, basically, I have addressed the issue (for now) by putting the culprit statement in a try/catch block with a few retries. The error still occurs but clears in the second retry.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:11 AM
Are you having multiple threads that runs this statements concurrently ? If so the race condition could cause this issue, when trying to update the metastore.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:29 AM
I am not using any threading at all.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:19 AM
If you simply want to get rid of the table, you can drop the table using hive client, as well
https://learn.microsoft.com/en-us/azure/databricks/kb/metastore/drop-table-corruptedmetadata
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:31 AM
I just wanted to simplify the code for illustration purposes. In my case the error occurs at the insert statement after the ALTER TABLE statement.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-05-2023 06:21 PM
Please check if this could help or not:
spark.databricks.delta.catalog.update.enabled false
Announcements





{kind=link}
{kind=link}
Related Content
- How a Random Chat on Omegle Chat Turned Into a Real-Life Friendship in Administration & Architecture
- Incomplete downstream dependencies in system.access.column_lineage in Data Governance
- NOT NULL constraint violated for column during OPTIMIZE in Data Engineering
- [Recap] Data + AI Summit 2026 - Data Governance | Simplify governance across AI, data, and tools in Data Governance
- Five Unity Catalog ABAC Updates Worth Paying Attention To in Data Governance