I'm calling the stored proc then store into pandas dataframe then creating list while creating list getting below error
Databricks execution failed with error state Terminated. For more details please check the run page url: path
An error occurred w...
@chaitanya , could you please try disabling arrow optimization and see if this resolves the issue?spark.sql.execution.arrow.enabled falsespark.sql.execution.arrow.pyspark.enabled false
I have forgotten my Databricks Community Edition Password and is trying to Reset the same using the Forgot Password link. It is saying that an Email will be sent with the link to reset the password but the Email is not coming. However Databricks mail...
Hi @Sanjoy Das , We could not find an account associated to your email. Did you pass the correct email or did you delete your account? Can you please create a CE account or pass the correct email address over mail with which you used to browse the C...
Hi all,We are constructing our CI/CD pipelines with the Repos feature following this guide:https://databricks.com/blog/2021/09/20/part-1-implementing-ci-cd-on-databricks-using-databricks-notebooks-and-azure-devops.htmlI'm trying to implement my pipes...
So you are managing your models with MLflow, and want to include them in a git repository?You can do that in a CI/CD process; it would run the mlflow CLI to copy the model you want (e.g. model:/my_model/production) to a git checkout and then commit i...
Hi, there!I'm trying to read a data (simple SELECT * FROM schema.tabl_a) from the "Queries" Tab inside the Databricks SQL platform, but always getting "org.apache.spark.sql.AnalysisException: dbfs:/.../.. doesn't exist" DescribeRelation true, [col_na...
Hi,I have many "small" jobs than needs to be executed quickly and at a predictable low cost from several Azure Data Factory pipelines. For this reason, I configured a small single node cluster to execute those processes. For the moment, everything se...
@Bilal Aslam In my case, it usually depends on the customers and their SLA. Most of them usually do not have a "true" high SLA requirement thus prefer the jobs to be throttled when the actual cost is within a certain range of the budget instead of ...
I'm trying to connect to Databricks using pyodbc and I'm running into an issue with struct columns. As far as I understand, struct columns and array columns are not supported by pyodbc, but they are converted to JSON. However, when there are nested c...
@Derk Crezee - I learned something today. Apparently ODBC does not convert to JSON. There is no defined spec on how to return complex types, in fact that was added only in SQL 2016. That's exactly what you are running into!End of history lesson Her...
Hi,Is it possible to configure job throttling in order to queue jobs across a workspace after a given number of concurrent execution when using the ephemeral cluster pattern? The reason is mainly for cost control. We prefer reducing performance rathe...
Thanks for the help josephk. I will continue to use an interactive cluster for the time being until the release of that new feature. Hopefully, it will allow my use case. Is there visibility on the roadmap for an ETA or more information on it?
Different than all-purpose clusters, the databricks job new cluster configuration window does not have a "Libraries" tab, in which specific python modules could be installed. What's the best practice for installing python modules on such clusters?
It turns out that the option exists outside of the cluster configuration scope, in the task configuration window itself - under "Advanced options" -> "Add dependent libraries".
Hello,I am not seeing a lot of information regarding the Databricks Certified Professional Data Scientistexam. I took the Associate Developer in Apache Spark Exam last year and the materials for the exam seemed much more focused than what I found for...
Hello @Sundar R , Yes I took the exam. Unfortunately I fail to reach the pass mark even though I got close. Things I could have did different:I focused so much in mastering each topics i.e. linear, logistic & regularized regression, ALS and etc. But...
HI,I have a daily scheduled job which processes the data and write as parquet file in a specific folder structure like root_folder/{CountryCode}/parquetfiles. Where each day job will write new data for countrycode under the folder for countrycodeI am...
Most external consumers will read partition as column when are properly configured (for example Azure Data Factory or Power BI).Only way around is that you will duplicate column with other name (you can not have the same name as it will generate conf...
Hi, I need to unzip some files that are ingested but when I unzip twice the same zipped file, the unzip command does not execute :As suggesgted in the documentation I did :import urllib
urllib.request.urlretrieve("https://resources.lendingclub.com/L...
Hi @Bertrand BURCKER , Create a script.sh and copy the script in the directory where is data.zip archive. This script is working with any name of archives and any name of csv.#!/bin/bash
currLoc="$PWD"
path="${currLoc}"
cd ${currLoc}
#EXTRACT ...
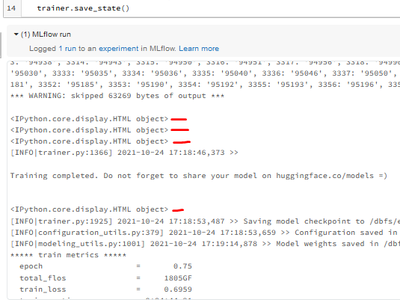
Some libraries have intermediate IPython HTML-objects returned to the notebook cell output.Since this happens during training a machine learning model the statements are typically buried within in the library so I cannot easily interfere. (e.g. in or...
Hi @Kaniz Fatma ,thanks for showing me the link. This helps if you are in control of the generated html-object. If the html-content comes from a library, that is where the problems start, because I cannot wrap displayHTML().(I can of course look for...
Hi All,I hope you're doing wellI am facing issue while installing an python library on ADB Cluster.lib - PyCaret ( latest version)its not getting install and showing me 'Failed' Status.It would be great if you can help here !!Thanks
I have followed the documentation and using the same metastore config that is working in the Data Engineering context. When attempting to view the Databases, I get the error:Encountered an internal errorThe following information failed to load:The li...
@Bilal Aslam I didn't think to look there before since I hadn't tried to run any queries. I see the failed SHOW DATABASES queries in history and they identify the error: Builtin jars can only be used when hive execution version == hive metastore v...