Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: reading multiple csv files using pathos.multip...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 11:51 PM
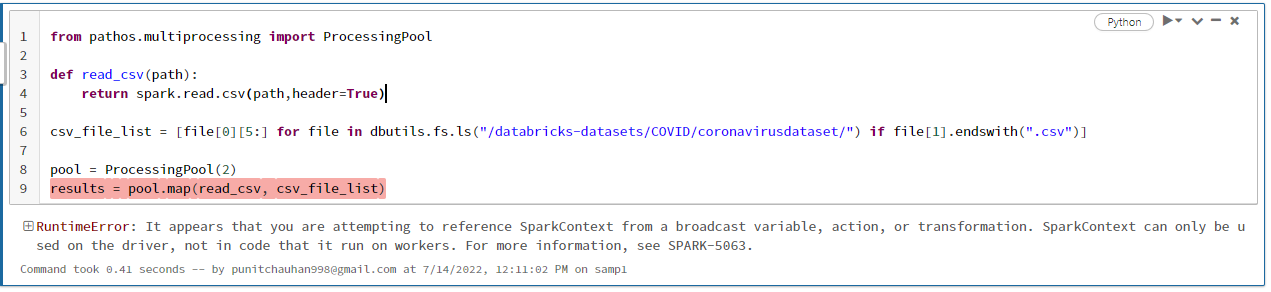
I'm using PySpark and Pathos to read numerous CSV files and create many DF, but I keep getting this problem.

from pathos.multiprocessing import ProcessingPool
def readCsv(path):
return spark.read.csv(path,header=True)
csv_file_list = [file[0][5:] for file in dbutils.fs.ls("/databricks-datasets/COVID/coronavirusdataset/") if file[1].endswith(".csv")]
pool = ProcessingPool(2)
results = pool.map(readCsv, csv_file_list)
Labels:
- Labels:
-
Multiple


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2022 01:34 AM
hey @Punit Chauhan refer this code
from multiprocessing.pool import ThreadPool
pool = ThreadPool(5)
notebooks = ['dim_1', 'dim_2']
pool.map(lambda path: dbutils.notebook.run("/Test/Threading/"+path, timeout_seconds= 60, arguments={"input-data": path}),notebooks)
Rishabh Pandey
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-14-2022 02:41 AM
You actually don't need to filter `.csv` files like that.
You can use `pathGlobFilter` to do a regex match for selecting files that matches provided regular expression.
df = spark.read.option("pathGlobFilter","*.csv").csv(upload_path)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-04-2022 12:00 AM
Hi @Punit Chauhan
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2022 01:30 AM
@Ajay Pandey @Rishabh Pandey
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2022 01:34 AM
hey @Punit Chauhan refer this code
from multiprocessing.pool import ThreadPool
pool = ThreadPool(5)
notebooks = ['dim_1', 'dim_2']
pool.map(lambda path: dbutils.notebook.run("/Test/Threading/"+path, timeout_seconds= 60, arguments={"input-data": path}),notebooks)
Rishabh Pandey
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2022 01:35 AM
thanks @Rishabh Pandey
Announcements





{kind=link}
Related Content
- The Open-Weight Revolution: A Game Changer for Our LLM Cost Optimization Odyssey in Generative AI
- Ingesting data from a SharePoint Excel file with two worksheets in one pipeline in Data Engineering
- Community Connectors confusion with `connector_spec.yaml` usage (or lack of usage) in Data Engineering
- sdp-meta (dlt-meta) vs lakeflow_framework: when should we use which? in Data Engineering
- Multi-select dashboard parameter now resolves to NULL instead of empty array? in Data Engineering