Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Scope creation in Databricks or Confluent?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:51 AM
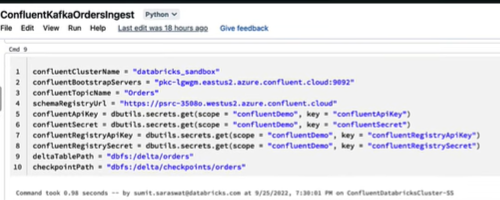
Hello I am a newbie in this field and trying to access confluent kafka stream in Databricks Azure based on a beginner's video by Databricks. I have a free trial of Databricks cluster right now. When I run the below notebook, it errors out on line 5 on scope.
My question is, should I create the scope in confluent or in Databricks. Has anybody seen this before?

Thanks so much!!
Julie
Labels:
- Labels:
-
Azure
-
Datadog
-
Kafka Stream
-
Scope


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:53 AM
For testing, create without secret scope. It will be unsafe, but you can post secrets as strings in the notebook for testing. Here is the code which I used for loading data from confluent:
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", host)
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(userid, password))
.option("subscribe", topic)
.option("kafka.client.id", "Databricks")
.option("kafka.group.id", "new_group2")
.option("spark.streaming.kafka.maxRatePerPartition", "5")
.option("startingOffsets", "earliest")
.option("kafka.session.timeout.ms", "10000")
.option("minPartitions", sc.DefaultParallelism)
.load() )My blog: https://databrickster.medium.com/
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:53 AM
For testing, create without secret scope. It will be unsafe, but you can post secrets as strings in the notebook for testing. Here is the code which I used for loading data from confluent:
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", host)
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(userid, password))
.option("subscribe", topic)
.option("kafka.client.id", "Databricks")
.option("kafka.group.id", "new_group2")
.option("spark.streaming.kafka.maxRatePerPartition", "5")
.option("startingOffsets", "earliest")
.option("kafka.session.timeout.ms", "10000")
.option("minPartitions", sc.DefaultParallelism)
.load() )My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 07:49 AM
Hey Hubert,
Firstly thanks for your response. Sure, I'll try this instead.
For line 11, kafka.group.id , that'll have to be from confluent cloud right?
Thanks,
Julie
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 07:53 AM
It is the name defined by you to control offset. I think that once you put in databricks code it will create it in kafka/confluent automatically.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 09:19 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 09:24 AM
or does this even mean its able to access my topic?
Thanks for your time Hubert. I really appreciate it.
Julie
Announcements





{kind=link}
{kind=link}
Related Content
- Unity Catalog External Location with Amazon S3 Access Points,session policy behavior and workarounds in Data Engineering
- STTM as a Metadata Contract in Databricks in Data Engineering
- PostgreSQL ingestion source not supported in workspace when deploying Databricks Asset Bundle in Data Engineering
- Workspaces stuck in a provisioning state in Administration & Architecture
- Provisioned throughput is not enabled for this workspace in Generative AI