Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Selenium chrome driver on databricks driver On the...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Selenium chrome driver on databricks driver On the databricks community, I see repeated problems regarding the selenium installation on the databricks...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2022 06:12 AM
Selenium chrome driver on databricks driver
On the databricks community, I see repeated problems regarding the selenium installation on the databricks driver. Installing selenium on databricks can be surprising, but for example, sometimes we need to grab some datasets behind fancy authentication, and selenium is the most accessible tool to do that. Of course, always remember to check the most uncomplicated alternatives first. For example, if we need to download an HTML file, we can use SparkContext.addFile() or just use the requests library. If we need to parse HTML without simulating user actions or downloading complicated pages, we can use BeautifulSoap. Please remember that selenium is running on the driver only (workers are not utilized), so just for the selenium part single node cluster is the preferred setting.
Installation
The easiest solution is to use apt-get to install ubuntu packages, but often version in the ubuntu repo is outdated. Recently that solution stopped working for me, and I decided to take a different approach and to get the driver and binaries from chromium-browser-snapshots https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html Below script download the newest version of browser binaries and driver. Everything is saved to /tmp/chrome directory. We must also set the chrome home directory to /tmp/chrome/chrome-user-data-dir. Sometimes, chromium complains about missing libraries. That's why we also install libgbm-dev. The below script will create a bash file implementing mentioned steps.
dbutils.fs.mkdirs("dbfs:/databricks/scripts/")
dbutils.fs.put("/databricks/scripts/selenium-install.sh","""
#!/bin/bash
%sh
LAST_VERSION="https://www.googleapis.com/download/storage/v1/b/chromium-browser-snapshots/o/Linux_x64%2FLAST_CHANGE?alt=media"
VERSION=$(curl -s -S $LAST_VERSION)
if [ -d $VERSION ] ; then
echo "version already installed"
exit
fi
rm -rf /tmp/chrome/$VERSION
mkdir -p /tmp/chrome/$VERSION
URL="https://www.googleapis.com/download/storage/v1/b/chromium-browser-snapshots/o/Linux_x64%2F$VERSION%2Fchrome-linux.zip?alt=media"
ZIP="${VERSION}-chrome-linux.zip"
curl -# $URL > /tmp/chrome/$ZIP
unzip /tmp/chrome/$ZIP -d /tmp/chrome/$VERSION
URL="https://www.googleapis.com/download/storage/v1/b/chromium-browser-snapshots/o/Linux_x64%2F$VERSION%2Fchromedriver_linux64.zip?alt=media"
ZIP="${VERSION}-chromedriver_linux64.zip"
curl -# $URL > /tmp/chrome/$ZIP
unzip /tmp/chrome/$ZIP -d /tmp/chrome/$VERSION
mkdir -p /tmp/chrome/chrome-user-data-dir
rm -f /tmp/chrome/latest
ln -s /tmp/chrome/$VERSION /tmp/chrome/latest
# to avoid errors about missing libraries
sudo apt-get update
sudo apt-get install -y libgbm-dev
""", True)
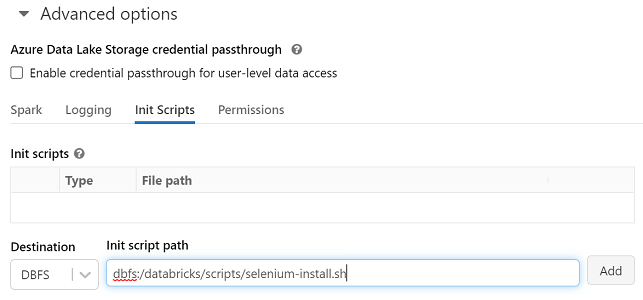
display(dbutils.fs.ls("dbfs:/databricks/scripts/"))The script was saved to DBFS storage as /dbfs/databricks/scripts/selenium-install.sh We can set it as an init script for the server. Click your cluster in "compute" -> click "Edit" -> "configuration" tab -> scroll down to "Advanced options" -> click "Init Scripts" -> select "DBFS" and set "Init script path" as "/dbfs/databricks/scripts/selenium-install.sh" -> click "add".

%sh
/dbfs/databricks/scripts/selenium-install.shNow we can install selenium. Click your cluster in "compute" -> click "Libraries" -> click "Install new" -> click "PyPI" -> set "Package" as "selenium" -> click "install".

%pip install seleniumSo let's start webdriver. We can see that Service and binary_location point to driver and binaries, which were downloaded and unpacked by our script.
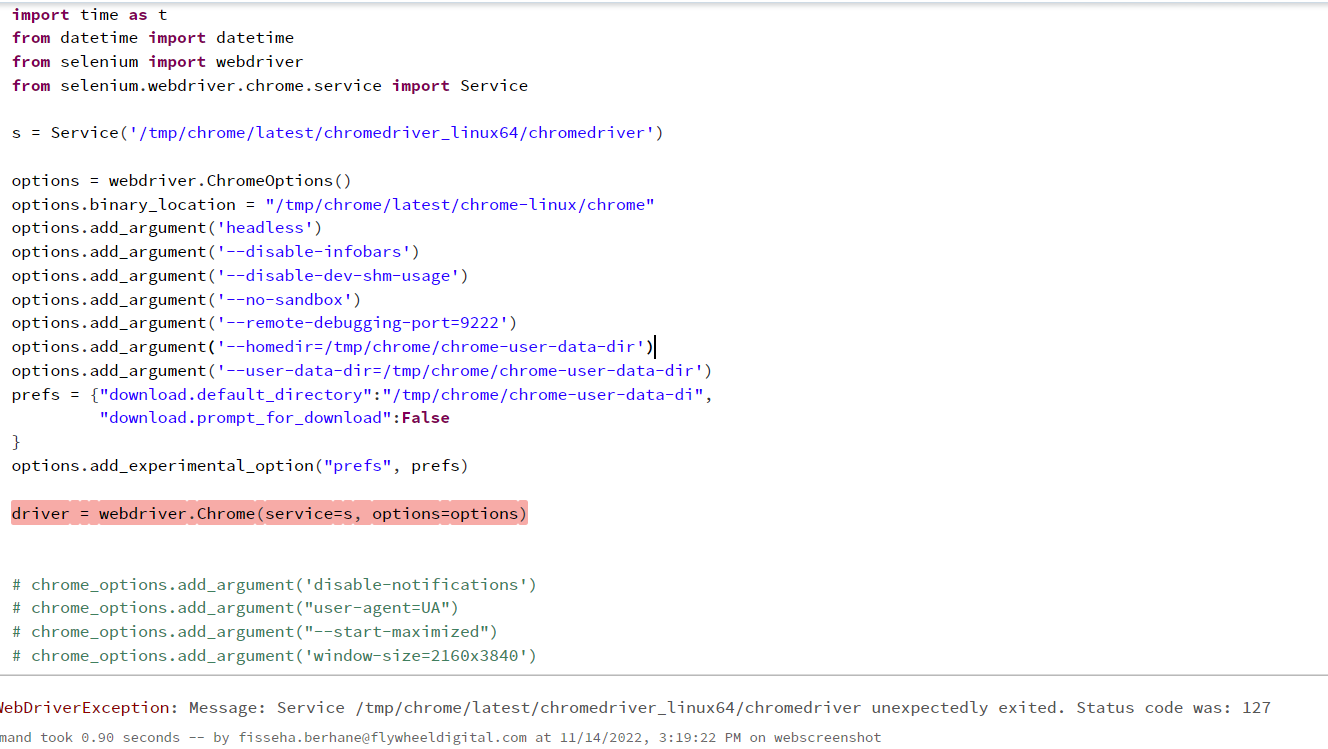
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service('/tmp/chrome/latest/chromedriver_linux64/chromedriver')
options = webdriver.ChromeOptions()
options.binary_location = "/tmp/chrome/latest/chrome-linux/chrome"
options.add_argument('headless')
options.add_argument('--disable-infobars')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox')
options.add_argument('--remote-debugging-port=9222')
options.add_argument('--homedir=/tmp/chrome/chrome-user-data-dir')
options.add_argument('--user-data-dir=/tmp/chrome/chrome-user-data-dir')
prefs = {"download.default_directory":"/tmp/chrome/chrome-user-data-di",
"download.prompt_for_download":False
}
options.add_experimental_option("prefs",prefs)
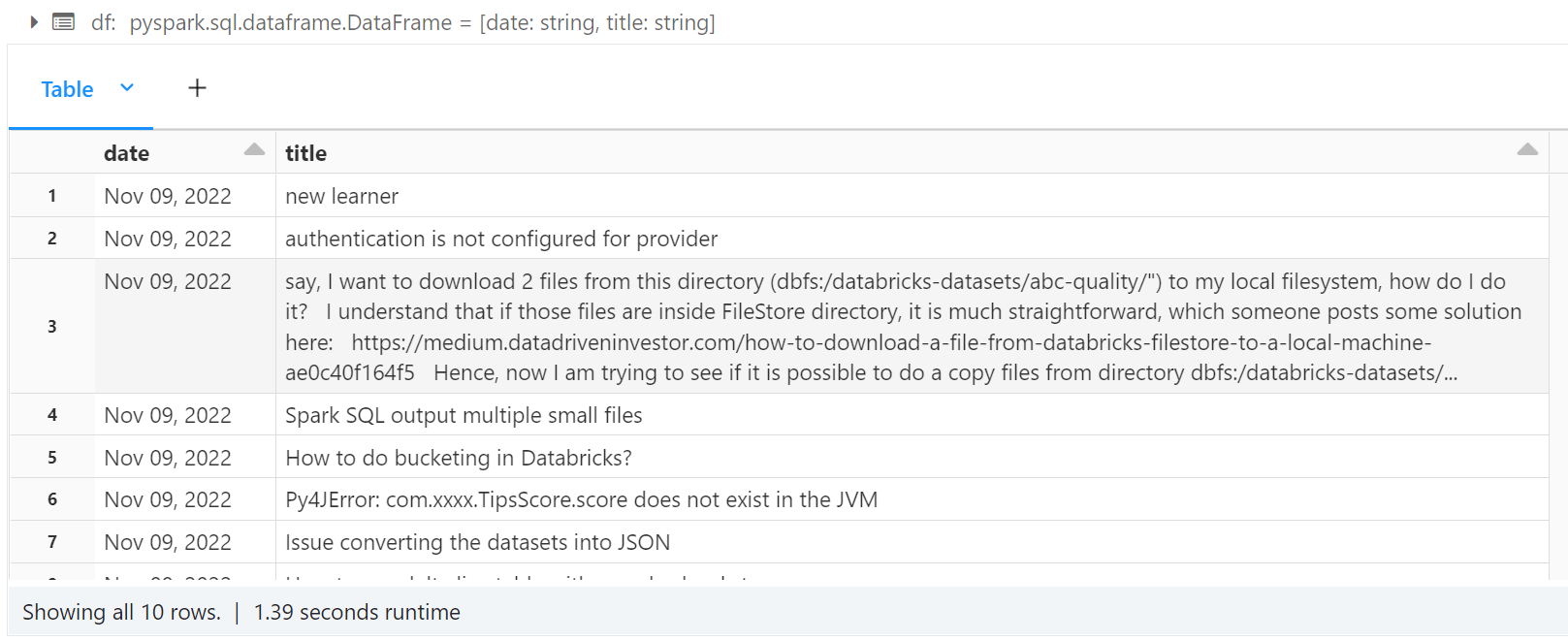
driver = webdriver.Chrome(service=s, options=options)Let's test webdriver. We will take the last posts from the databricks community and convert them to a dataframe.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver.execute("get", {'url': 'https://community.databricks.com/s/discussions?page=1&filter=All'})
date = [elem.text for elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, "lightning-formatted-date-time")))]
title = [elem.text for elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, "p[class='Sub-heaading1']")))]from pyspark.sql.types import StringType, StructType, StructField
schema = StructType([
StructField("date", StringType()),
StructField("title", StringType())
])
df = spark.createDataFrame(list(zip(date, title)), schema=schema)
display(df)
driver.quit()The version of that article as ready to-run notebook is available at: https://github.com/hubert-dudek/databricks-hubert/blob/main/projects/selenium/chromedriver.py
To import that notebook into databricks, go to the folder in your "workplace" -> from the arrow menu, select "URL" -> click "import" -> put https://raw.githubusercontent.com/hubert-dudek/databricks-hubert/main/projects/selenium/chromedriver... as URL.

My blog: https://databrickster.medium.com/
Labels:
- Labels:
-
Selenium


9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2022 06:29 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2022 12:20 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2022 06:06 PM
Gray's script from the link below worked for me.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2022 04:51 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2022 05:14 AM
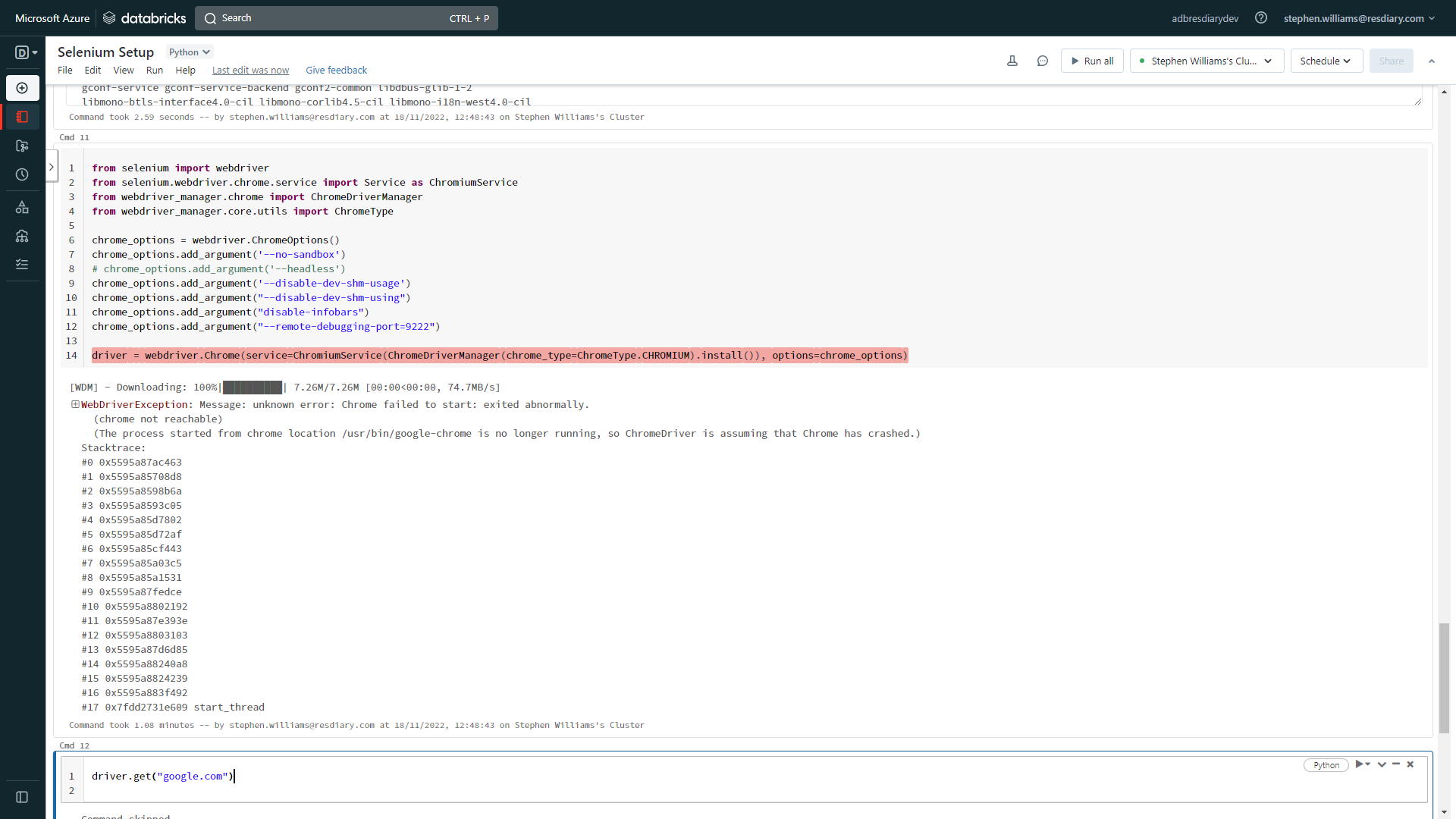
@Fisseha Berhane I managed to get pass the error message by using the web-driver module - the next challenge is opening the browser using the "driver.get()" method...
Databricks executes the command "successfully" without opening the requested URL -

Does anyone know how to get that to work?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2022 03:56 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2022 12:56 PM
Hi, I will test it again on runtime 12 and also using @Henry Gray discoveries in a few weeks.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-04-2023 06:39 AM
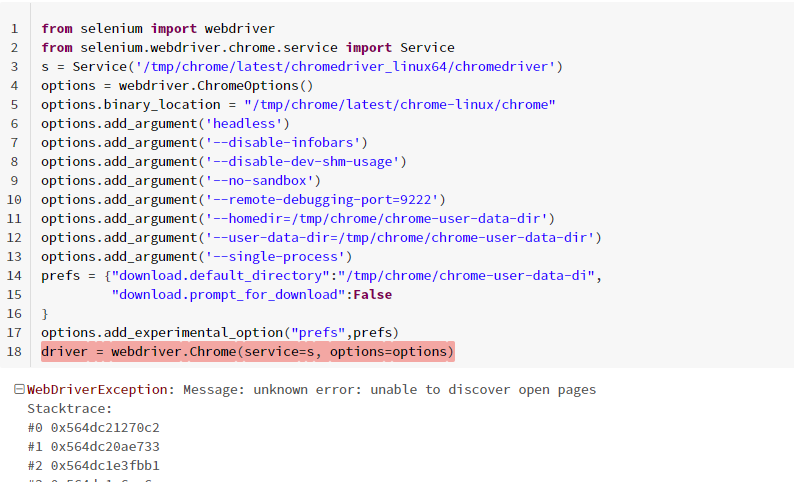
@Hubert-Dudek Hi, thanks for the detailed tutorial. With slight tweaks to the init script I was able to make Selenium work on single-node cluster. However, I haven't had much luck with shared clusters in DB Runtime 14.0. Btw, I'm using Volumes to store both chrome 114 debian package & chromebinary executable.

See attached for the previous steps.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-24-2024 04:19 AM
Hi Hubert-Dudek,
Are there any updates to your article? I have struggling to get databricks to recognise a Seleniumbase driver. I think the error might actually be a permissions problem as the error is:
WebDriverException: Message: Can not connect to the Service /local_disk0/.ephemeral_nfs/envs/pythonEnv-0000-xxx.../lib/python3.11/site-packages/seleniumbase/drivers/uc_driver
Thanks
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Manage budgets and cost controls for Genie in Data Governance
- STTM as a Metadata Contract in Databricks in Data Engineering
- DBSQL MCP output limit in Generative AI
- Querying Metric Views via Classic/Pro SQL Warehouses in Generative AI
- Managing IPYNB cell timestamps in source control in Data Engineering