Hi,
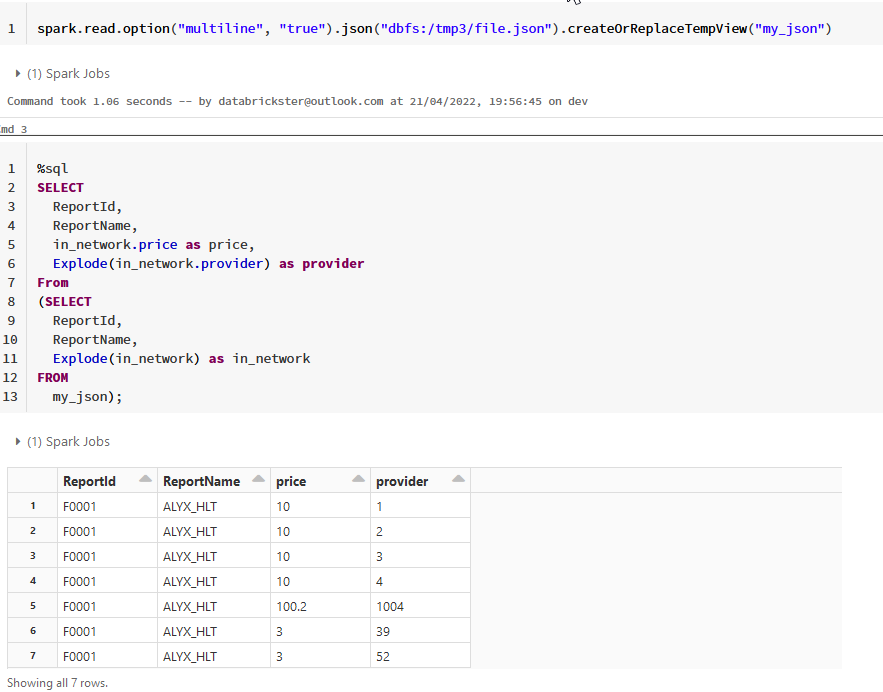
Using the below cosmos DB query it is possible to achieve the expected output, but how can I do the same with spark SQL in Databricks.
COSMOSDB QUERY : select c.ReportId,c.ReportName,i.price,p as provider from c join i in in_network join p in i.provider
Source JSON
{
"ReportId":"F0001",
"ReportName":"ALYX_HLT",
"in_network":[
{"provider":[1,2,3,4],"price":10},
{"provider":[1004],"price":100.2},
{"provider":[39,52],"price":3}
]
}
Expected Output
[
{ "ReportId":"F0001","ReportName":"ALYX_HLT","provider":100,"price":10},
{ "ReportId":"F0001","ReportName":"ALYX_HLT","provider":200,"price":10},
{ "ReportId":"F0001","ReportName":"ALYX_HLT","provider":300,"price":1.3},
{ "ReportId":"F0001","ReportName":"ALYX_HLT","provider":400,"price":23.1},
{ "ReportId":"F0001","ReportName":"ALYX_HLT","provider":500,"price":23.1}
]
https://docs.microsoft.com/en-us/answers/questions/821351/trying-to-flattren-my-json-using-cosmosdb-...








{kind=link}