Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Unable to retrieve all rows of delta table using S...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 02:48 AM
Hi,
I am trying to query a table using JDBC endpoint of Interactive Cluster. I am connected to JDBC endpoint using DBeaver. When I export a small subset of data 2000-8000 rows, it works fine and export the data. However, when I try to export all rows of table, it fails by saying request timed out. My table has almost 1 million rows.
I tried same using Python application by trying to export data in CSV and got the same result i.e. it succeeds for small number of rows but fails for entire table.
Can someone try this and tell if they are experiencing same issue and help me understand why I'm experiencing this issue? Note - I'm using non-UC ADB (Hive_metastore)
import csv
from databricks import sql
with sql.connect(server_hostname="databricks_hostname",
http_path="sql/protocolv1/o/databricks_details",
auth_type="databricks-oauth") as connection:
# Open a cursor
with connection.cursor() as cursor:
# Execute query to fetch 20,000 rows
cursor.execute("SELECT * FROM schema.table_name LIMIT 2000000")
result = cursor.fetchall()
# Save results to a CSV file
with open("output.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write header (column names)
column_names = [desc[0] for desc in cursor.description]
writer.writerow(column_names)
# Write data rows
writer.writerows(result)
print("Data saved to output.csv")


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 04:28 AM - edited 09-05-2025 04:44 AM
If this is related to following topic: Exposing Data for Consumers in non-UC ADB - Databricks Community - 130954
Then:
"Looking at the error I noticed the weird name of the storage account. So now I'm thinking that your jdbc connection is using CloudFetch.
"Cloud Fetch, a capability that fetches query results through the cloud storage that is set up in your Azure Databricks deployment.
Query results are uploaded to an internal DBFS storage location as Arrow-serialized files of up to 20 MB. When the driver sends fetch requests after query completion, Azure Databricks generates and returns shared access signatures to the uploaded files. The JDBC driver then uses the URLs to download the results directly from DBFS."

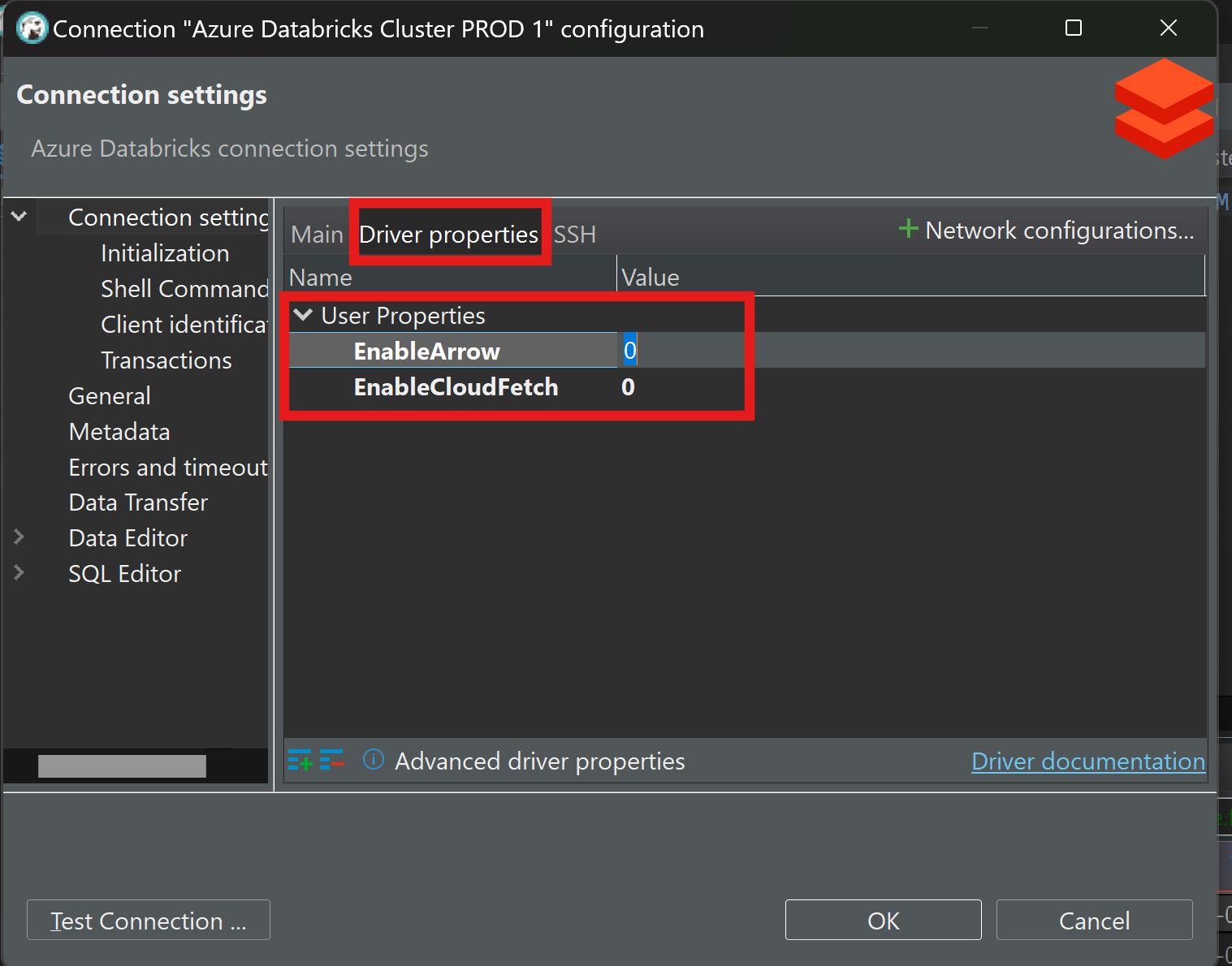
Can you add following option to your JDBC url? It will disable cloudFetch. Once you set this option try again.
EnableQueryResultDownload=0
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 04:12 AM
Hi
I am using latest JDBC driver 2.7.3 https://www.databricks.com/spark/jdbc-drivers-archive
And my JDBC url comes from JDBC endpoint of Interactive Cluster.
jdbc:databricks://adb-{workspace_id}.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/{workspace_id}/{cluster_id};AuthMech=11;Auth_Flow=2;TokenCachePassPhrase=U2MToken;EnableTokenCache=0
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 04:28 AM - edited 09-05-2025 04:44 AM
If this is related to following topic: Exposing Data for Consumers in non-UC ADB - Databricks Community - 130954
Then:
"Looking at the error I noticed the weird name of the storage account. So now I'm thinking that your jdbc connection is using CloudFetch.
"Cloud Fetch, a capability that fetches query results through the cloud storage that is set up in your Azure Databricks deployment.
Query results are uploaded to an internal DBFS storage location as Arrow-serialized files of up to 20 MB. When the driver sends fetch requests after query completion, Azure Databricks generates and returns shared access signatures to the uploaded files. The JDBC driver then uses the URLs to download the results directly from DBFS."
Can you add following option to your JDBC url? It will disable cloudFetch. Once you set this option try again.
EnableQueryResultDownload=0
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 07:25 AM
Hi @szymon_dybczak ,
Your recommendation worked. I modified JDBC url to
jdbc:databricks://adb-{workspace_id}.azuredatabricks.net:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/{workspace_id}/{cluster_id};AuthMech=11;Auth_Flow=2;TokenCachePassPhrase=U2MToken;EnableTokenCache=0;EnableQueryResultDownload=0.
I tried another solution which looks essentially same what @szymon_dybczak you recommended. Solution is attached.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 07:31 AM
Great that it worked @fly_high_five . I'm happy that I could help.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2025 04:23 AM - edited 09-05-2025 04:25 AM
Hi @fly_high_five,
I found these references about this situation, see if they help you: increase the SocketTimeout in JDBC (Databricks KB “Best practices when using JDBC with Databricks SQL” – https://kb.databricks.com/dbsql/job-timeout-when-connecting-to-a-sql-endpoint-over-jdbc
) and replace fetchall() with fetchmany() while adjusting cursor.arraysize (Databricks SQL Connector for Python docs – https://docs.databricks.com/en/dev-tools/python-sql-connector.html
).
Wiliam Rosa
Data Engineer | Machine Learning Engineer
LinkedIn: linkedin.com/in/wiliamrosa
Data Engineer | Machine Learning Engineer
LinkedIn: linkedin.com/in/wiliamrosa
Announcements





{kind=link}
Related Content
- Got error when access delta sharing table with iceberg endpoint in Warehousing & Analytics
- Cross-region S3 reads suddenly fail with 400 Bad Request — eu-west-1 metastore to af-south-1 bucket in Data Engineering
- API does not return Genie space create and last modified dates in Administration & Architecture
- Which types of model serving endpoints have health metrics available? in Machine Learning
- Newly added workspace users do not appear immediately in WorkspaceClient().users.list() or SCIM API in Administration & Architecture