Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Why is My MIN MAX Query Still Slow on a 29TB Delta...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-14-2024 04:17 AM
Hello,
I have a large Delta table with a size of 29TB. I implemented Liquid Clustering on this table, but running a simple MIN MAX query on the set cluster column is still extremely slow. I have already optimized the table. Am I missing something in my implementation?


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-14-2024 07:15 AM
Hi
this operation should take seconds because it use the precomputed statistics for the table. Then few elements to verify:
- if the data type is datetime or integer should work, if it is string data type then it needs to read all data.
- verify the column position, normally delta lake only create statistics for the some columns (i think first 15), if the column is not at the list of column to precompute stats then it needs to read all data.
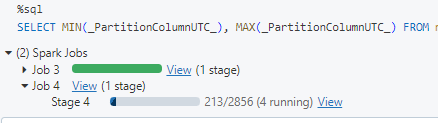
if you need to read all data, then i saw in the image that only 4 task are running means 4 cores, then i would recommend to use a bigger cluster in memory and cores (scale up) with fewer nodes to reduce the shuffle.
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-14-2024 04:58 AM - edited 06-14-2024 04:59 AM
What is the data type of the field you're querying?
All I can see is the name "_PartitionColumnUTC_". Judging by the name it is a date/timestamp but this is me making assumptions.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-14-2024 11:22 PM
Hello, this is a type integer in the format YYYYMMDD
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-15-2024 11:45 AM
That is strange, min/max of integers should be able to be retrieved very quickly, especially if they are partitioned columns. You are 100% sure it is an integer column and not a string? You didn't specify any filter clauses in your queries that would potentially trigger a full table scan?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-19-2024 11:20 PM
Hi Jaco,
Using the ANALYZE TABLE command fixed the issue; however, I am still experiencing very slow queries on the STRING type of a different cluster key. Does liquid clustering not support the STRING type very well?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-19-2024 11:31 PM
Ah then your table had to have its statistics refilled, glad it works now.
As for string types, it should work just as well.
"slow" is a bit subjective maybe. You have not yet mentioned the warehouse tier/cluster config, are you using sufficient processing power?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-14-2024 07:15 AM
Hi
this operation should take seconds because it use the precomputed statistics for the table. Then few elements to verify:
- if the data type is datetime or integer should work, if it is string data type then it needs to read all data.
- verify the column position, normally delta lake only create statistics for the some columns (i think first 15), if the column is not at the list of column to precompute stats then it needs to read all data.
if you need to read all data, then i saw in the image that only 4 task are running means 4 cores, then i would recommend to use a bigger cluster in memory and cores (scale up) with fewer nodes to reduce the shuffle.
Announcements





{kind=link}
{kind=link}
Related Content
- Liquid Clustering file pruning breaks when filtering on a high NULL numeric column in dataSkipping in Data Engineering
- check statistics of clustering columns per file to see how liquid clustering works in Data Engineering
- Optimizing Large Materialized View to expedite query execution in Data Engineering
- Unable to apply liquid clustering to a materialized view in Data Engineering
- Liquid Clustering and S3 Performance in Data Engineering