Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Why Spark Streaming from S3 is returning thous...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-29-2022 04:46 PM
I am attempting to stream JSON endpoint responses from an s3 bucket into a spark DLT. I have been very successful in this practice previously, but the difference this time is that I am storing the responses from multiple endpoints in the same s3 bucket, whereas before it has been a single endpoint response in a single bucket.
Setting The Scene
I am making GET requests to 9 different Season Endpoints, each for a different Sports League. The endpoints return a list of Seasons for the given Sports League. I decided to store them all in the same s3 bucket because the endpoint responses are structured almost identically.
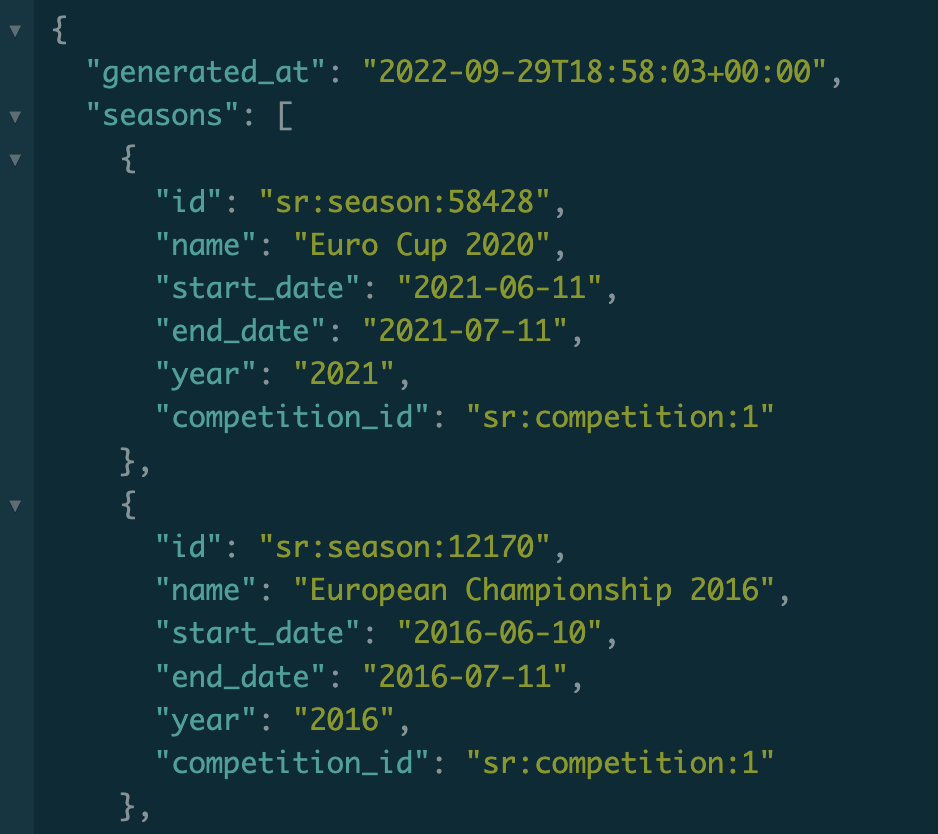
8/9 of the endpoints return a response structured like so:
Giving a League and list of Seasons

The 9th endpoint is for Soccer Seasons, which is structured slightly differently but it also returns a list of Seasons.

Key endpoint differences:
- 8/9 endpoints give a League object, Season.Type, and Season.Status
- The 9th (Soccer) endpoint does NOT have a League object, Season.Type, nor Season.Status
- It additionally provides a Season.Competitor_Id
- It is also important to note, not all 8/9 endpoint responses are exactly the same and there is some variation in the provided Season fields.
The Issue:
When Spark Streaming from the s3 bucket, it says there are thousands of JSON files when there are only 9.
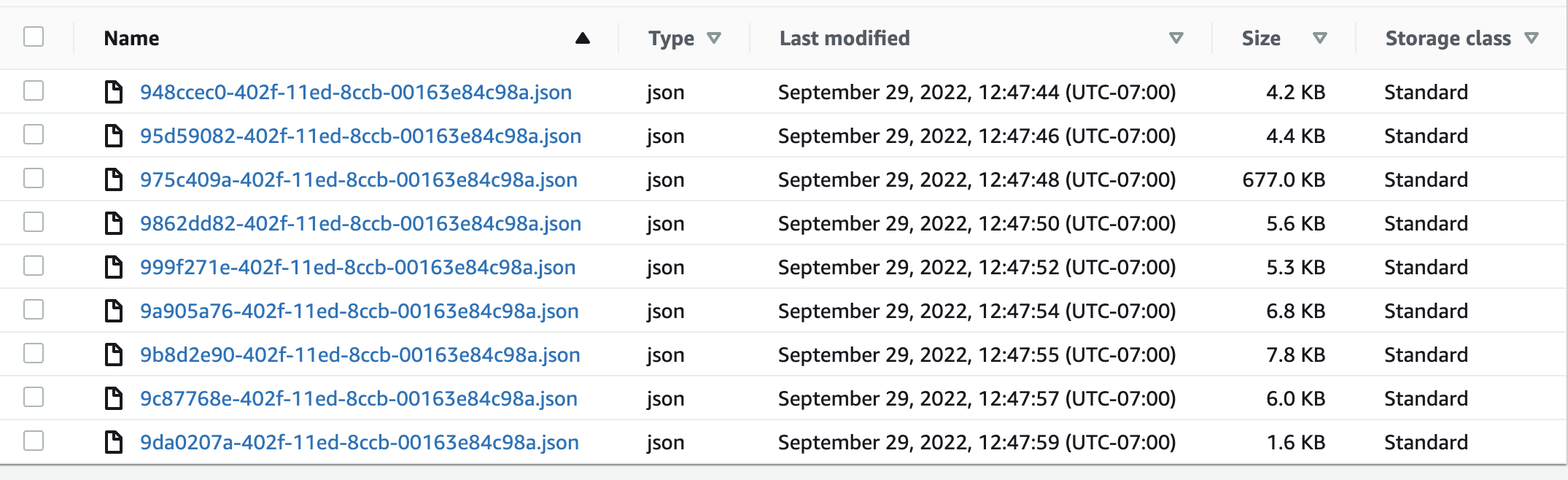
Here you can see all 9 in the bucket. Notice Soccer is the largest file as well.

However, when displaying the streaming spark data frame of the s3 bucket it shows there are thousands of null soccer JSON files while also correctly displaying the other 8 sports as having only 1 JSON file.
I suspect that the soccer endpoint response file is being auto-exploded into thousands of files. This would explain why the Seasons column for soccer is null because it has already exploded and now contains other fields.
Any guidance would be appreciated and if I can be any more clear please let me know.
Thanks in advance!


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-30-2022 05:23 PM
The Soccer Seasons Endpoint Response was the only one with backslashes `\` which signify a new line character. When using AutoLoader you need to specify the `multiLine` Option to indicate the JSON spans multiple....
.option("multiline", "true")This caused the s3 stream to interpret each section between backslashes as a separate JSON file, resulting in Thousands of null Soccer Files and no Seasons column.

3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-30-2022 05:23 PM
The Soccer Seasons Endpoint Response was the only one with backslashes `\` which signify a new line character. When using AutoLoader you need to specify the `multiLine` Option to indicate the JSON spans multiple....
.option("multiline", "true")This caused the s3 stream to interpret each section between backslashes as a separate JSON file, resulting in Thousands of null Soccer Files and no Seasons column.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-03-2022 03:04 PM
@Carter Mooring Thank you SO MUCH for coming back to provide a solution to your thread! Happy you were able to figure this out so quickly. And I am sure that this will help someone in the future with the same issue. 😊
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-24-2024 04:54 AM
Hi @williamyoung ,
I must admit, that's creative way to sneak in spam 😄 Anyway, I marked it as an inappropriate content.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- How to Increase HTTP Request Timeout for Databricks App Beyond 120 Seconds? in Generative AI
- Scaling Declarative Streaming Pipelines for CDC from On-Prem Database to Lakehouse in Data Engineering
- What is the Power of DLT Pipeline to read streaming data in Data Engineering
- Autoloader cleansource option does not take any effect in Data Engineering
- Maintaining Custom State in Structured Streaming in Data Engineering