- 4476 Views
- 2 replies
- 0 kudos
Can AWS workspaces share subnets?
The docs state:"You can choose to share one subnet across multiple workspaces or both subnets across workspaces."as well as:"You can reuse existing security groups rather than create new ones."and on this page:"If you plan to share a VPC and subnets ...
- 4476 Views
- 2 replies
- 0 kudos
- 0 kudos
AWS WorkSpaces can be configured with subnets that can be shared within an AWS account or across AWS accounts using resource sharing mechanisms, but this depends on the specific AWS service and context. For Databricks workspaces on AWS, documentation...
- 0 kudos
- 4104 Views
- 1 replies
- 0 kudos
Joblib with optuna and SB3
Hi everyone,I am training some reinforcement learning models and I am trying to automate the hyperparameter search using optuna. I saw in the documentation that you can use joblib with spark as a backend to train in paralel. I got that working with t...
- 4104 Views
- 1 replies
- 0 kudos
- 0 kudos
Stable Baselines 3 (SB3) models can be optimized with Optuna for hyperparameter search, but parallelizing these searches using Joblib with Spark as the backend—like the classic scikit-learn example—commonly encounters issues. The root problem is that...
- 0 kudos
- 3796 Views
- 1 replies
- 0 kudos
NiFi on EKS Fails to Connect to Databricks via JDBC – "Connection reset" Error
I'm using Apache Nifi (running on AWS EKS) to connect to Databricks (with compute on EC2) via JDBC. My JDBC URL is as follows: jdbc:databricks://server_hostname:443/default;transportMode=http;ssl=1;httpPath=my_httppath;AuthMech=3;UID=token;PWD=my_tok...
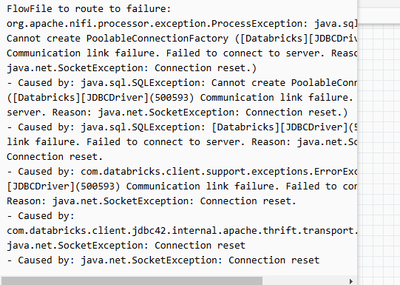
- 3796 Views
- 1 replies
- 0 kudos
- 0 kudos
A "Connection reset" error in NiFi when connecting to Databricks via JDBC, despite successful telnet and working connectivity from DBeaver, usually points to subtle protocol or compatibility issues rather than network-level blocks. Common Causes JD...
- 0 kudos
- 4553 Views
- 1 replies
- 0 kudos
.py script execution failed but succeeded when run in Python notebook
Background:My code executing without problem if run in a python notebook. However, the same code fails when execute from a .py script in the workspace. Seems like the 2 execution methods don't have identical version of the packagesError message: Attr...
- 4553 Views
- 1 replies
- 0 kudos
- 0 kudos
The error "AttributeError: 'DeltaMergeBuilder' object has no attribute 'withSchemaEvolution'" when running the same code from a .py script but not in a Python notebook is likely caused by a mismatch in the Delta Lake or Databricks Runtime versions or...
- 0 kudos
- 5127 Views
- 2 replies
- 0 kudos
Getting error while installing applicationinsights
Library installation attempted on the driver node of cluster 0210-115502-3lo6gkwd and failed. Pip could not find a version that satisfies the requirement for the library. Please check your library version and dependencies. Error code: ERROR_NO_MATCHI...
- 5127 Views
- 2 replies
- 0 kudos
- 0 kudos
The error indicates that Databricks could not install the applicationinsights or azure-identity libraries because pip could not find a matching distribution, and network connection attempts to the PyPI repository were repeatedly reset. This is common...
- 0 kudos
- 1821 Views
- 1 replies
- 0 kudos
Databricks Roadmap 13/11/2025
Can you provide me with a link to the recording that happened today:Databricks Product Roadmap Webinar, Thursday, November 13, 2025, 9:00 AM–10:00 AM GMT
- 1821 Views
- 1 replies
- 0 kudos
- 0 kudos
@Superstar_Singh , Is this the one you are asking about? https://www.databricks.com/resources/webinar/productroadmapwebinar
- 0 kudos
- 4158 Views
- 1 replies
- 0 kudos
Is there a way to prevent databricks-connect from installing a global IPython Spark startup script?
I'm currently using databricks-connect through VS Code on MacOS. However, this seems to install (and re-install upon deletion) an IPython startup script which initializes a SparkSession. This is fine as far as it goes, except that this script is *glo...
- 4158 Views
- 1 replies
- 0 kudos
- 0 kudos
Databricks Connect on MacOS (and some other platforms) adds a file to the global IPython startup folder, which causes every new IPython session—including those outside the Databricks environment—to attempt loading this SparkSession initialization. Th...
- 0 kudos
- 10662 Views
- 1 replies
- 0 kudos
PYTEST: Module not found error
Hi,Apologies, as I am trying to use Pytest first time. I know this question has been raised but I went through previous answers but the issue still exists.I am following DAtabricks and other articles using pytest. My structure is simple as -tests--co...
- 10662 Views
- 1 replies
- 0 kudos
- 0 kudos
Your issue with ModuleNotFoundError: No module named 'test_tran' when running pytest from a notebook is likely caused by how Python sets the module import paths and the current working directory inside Databricks notebooks (or similar environments). ...
- 0 kudos
- 4447 Views
- 1 replies
- 0 kudos
CloudFormation Stack Failure: Custom::CreateWorkspace in CREATE_FAILED State
I am trying to create a workspace using AWS CloudFormation, but the stack fails with the following error:"The resource CreateWorkspace is in a CREATE_FAILED state. This Custom::CreateWorkspace resource is in a CREATE_FAILED state. Received response s...
- 4447 Views
- 1 replies
- 0 kudos
- 0 kudos
When a CloudFormation stack fails with “The resource CreateWorkspace is in a CREATE_FAILED state” for a Custom::CreateWorkspace resource, it typically means the Lambda or service backing the custom resource returned a FAILED signal to CloudFormation ...
- 0 kudos
- 4368 Views
- 1 replies
- 0 kudos
How to Define Constants at Bundle Level in Databricks Asset Bundles for Use in Notebooks?
I'm working with Databricks Asset Bundles and need to define constants at the bundle level based on the target environment. These constants will be used inside Databricks notebooks.For example, I want a constant gold_catalog to take different values ...
- 4368 Views
- 1 replies
- 0 kudos
- 0 kudos
There is currently no explicit, built-in mechanism in Databricks Asset Bundles (as of 2024) for directly defining global, environment-targeted constants at the bundle level that can be seamlessly accessed inside notebooks without using job or task pa...
- 0 kudos
- 1063 Views
- 2 replies
- 0 kudos
Resolved! Compilation Failing with Scala SBT build to be used in Databricks
Hi,We have scala jar build with sbt which is used in Databricks jobs to readstream data from kafka...We are enhancing the from_avro function like below... def deserializeAvro( topic: String, client: CachedSchemaRegistryClient, sc: SparkConte...
- 1063 Views
- 2 replies
- 0 kudos
- 0 kudos
Thanks For the Update Louis... As we are planning to Sync All our notebook from Scala to Pyspark , we are in process of converting the code. I think Adding the additional dependency of ABRiS or Adobe’s spark-avro with Schema Registry support will tak...
- 0 kudos
- 877 Views
- 2 replies
- 1 kudos
How to tag/ cost track Databricks Data Profiling?
We recently started using the Data Profiling/ Lakehouse monitoring feature from Databricks https://learn.microsoft.com/en-us/azure/databricks/data-quality-monitoring/data-profiling/. Data Profiling is using serverless compute for running the profilin...
- 877 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @szymon_dybczak Thanks for th quick replay.But it seems serverless budget policies cannot be applied to data profiling/ monitoring jobs. https://learn.microsoft.com/en-us/azure/databricks/data-quality-monitoring/data-profiling/Serverless budget po...
- 1 kudos
- 509 Views
- 1 replies
- 1 kudos
Wheel File name is changed after using Databricks Asset Bundle Deployment on Github Actions
Hi Team,I am deploying to the Databricks workspace using GitHub and DAB. I have noticed that during deployment, the wheel file name is being converted to all lowercase letters (e.g., pyTestReportv2.whl becomes pytestreportv2.whl). This issue does not...
- 509 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @Nisha_Tech It seems like a Git issue rather than Databricks or DAB. There is a git configuration parameter decides the upper case/ lower case of the file names deploved. Please refer here: https://github.com/desktop/desktop/issues/2672#issuecomme...
- 1 kudos
- 1887 Views
- 2 replies
- 0 kudos
I can't create a compute resource beyond "SQL Warehouse", "Vector Search" and "Apps"?
None of the LLMs even understand why I can't create a compute resource. I was using community (now free edition) until yesterday, when I became apparent that I needed the paid version, so I upgraded. I've even got my AWS account connected, which was ...
- 1887 Views
- 2 replies
- 0 kudos
- 0 kudos
I have a similar issue and how can I upgrade?
- 0 kudos
- 7794 Views
- 2 replies
- 0 kudos
Cluster Auto Termination Best Practices
Are there any recommended practices to set cluster auto termination for cost optimization?
- 7794 Views
- 2 replies
- 0 kudos
- 0 kudos
Hello!We use a Databricks Job to adjust the cluster’s auto-termination setting based on the day and time. During weekdays from 6 AM to 6 PM, we set auto_termination_minutes to None, which keeps the cluster running. Outside those hours, and on weekend...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Course
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
ISVPartnership
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
link for labs
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |