- 4956 Views
- 11 replies
- 4 kudos
Resolved! How to create a widget in SQL with variables?
I want to create a widget in SQL and use it in R later. Below is my code%sqldeclare or replace date1 date = "2025-01-31";declare or replace date2 date ;set var date2=add_months(date1,5); What's the correct syntax of using date2 to create a widget? I ...
- 4956 Views
- 11 replies
- 4 kudos
- 4 kudos
Hi @zc ,Unfortunately, I think in case of sql widgets default value needs to be string literals. So above approach won't work.Regarding your second question about accessing variables decalared in SQL in R cell, you cannot do such a thing. Here's an e...
- 4 kudos
- 2376 Views
- 4 replies
- 12 kudos
Resolved! Want to See More Resolved Posts? Try This Simple Step
In community discussion, it’s common to see a question get a helpful reply, but then the conversation stalls. There is no follow-up, no marked solution, and no real closure. A small but effective way to keep things moving is@mention the person you’re...

- 2376 Views
- 4 replies
- 12 kudos
- 12 kudos
Thanks, @TheOC — appreciate you joining the effort!
- 12 kudos
- 2165 Views
- 5 replies
- 0 kudos
Is Model Registry possible in Databricks Free Edition?
Has anyone registered a Model in Databricks Free Edition? It seems not working or not available in Free Edition.
- 2165 Views
- 5 replies
- 0 kudos
- 0 kudos
Hi @xyz999 Have you tried to upgrade to models in Unity Catalog:import mlflowmlflow.set_registry_uri("databricks-uc")
- 0 kudos
- 2133 Views
- 2 replies
- 1 kudos
Resolved! old unwated accounts
I am having trouble removing several accounts that were used for trial purposes. Both AWS and AzureOne of my AWS logins still works; however, when I attempt to manage the account and cancel my "Enterprise Plan" via the Manage Account section, I enco...
- 2133 Views
- 2 replies
- 1 kudos
- 1 kudos
Hello @Thayal! You can refer to this post for detailed steps on deleting a Databricks account: https://community.databricks.com/t5/administration-architecture/delete-databricks-account/td-p/87187 Regarding the error about canceling via the account co...
- 1 kudos
- 2952 Views
- 3 replies
- 0 kudos
Resolved! databricks community edition is unable to sign
i was created a free edition of the databricks but I'm trying to login to the community edition wiht the same email of free edition throwing a error like this; User is not a member of this workspace.Please slove the issue
- 2952 Views
- 3 replies
- 0 kudos
- 0 kudos
Hello @diwakarnayudu! The Community Edition and the Free Edition are separate environments. Since you’ve created an account for the Free Edition, you can access that environment by logging in here: https://www.databricks.com/learn/free-edition.
- 0 kudos
- 954 Views
- 0 replies
- 0 kudos
ML-based profiling of data skew and bottlenecks on Databricks
Automatically detect skew and pipeline issues using ML profiling Data skew is a persistent performance issue in distributed data pipelines. On platforms like Databricks, skewed partitions can quietly degrade performance, inflate compute costs, and d...

- 954 Views
- 0 replies
- 0 kudos
- 2371 Views
- 1 replies
- 0 kudos
Terraform error deploying Databricks Asset Bundle
Hi all ,I am deploying a very simple DAB from an Azure DevOps Pipeline with an self hosted agent, there is no error messages but in the Databricks workspace there is nothing deployed and the files of the bundle are uploaded in the workspace. When I p...
- 2371 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @armandovl ,Try pointing your Databricks bundle to a system-installed Terraform binary. In your bundle config file, configure it to use the system’s Terraform instead of the bundled one.Also, ensure the Terraform binary is available in the agent’s...
- 0 kudos
- 7857 Views
- 2 replies
- 1 kudos
Delta table definition - Identity column
Hello,Would anyone know if it is possible to create a delta table using Python that includes a column that is generated by default as identity (identity column for which the value inserted can be manually overriden)?There seems to be a way to create ...
- 7857 Views
- 2 replies
- 1 kudos
- 1 kudos
There is a `generatedByDefaultAs` option now, see https://github.com/delta-io/delta/pull/3404.
- 1 kudos
- 2076 Views
- 2 replies
- 1 kudos
Resolved! Issue with the size of text in my notebook
I am hoping someone might be able to assist as earlier I thought I had an MS word window focused so did Ctrl +I to make something italics. But I had my browser window focused instead, and pressing the above combination seems to have made the text in ...
- 2076 Views
- 2 replies
- 1 kudos
- 1 kudos
Thanks for the quick response. I am think that I may have also had the browser zoomed to 110% for a while and just not realised I had zoomed it in. As looking at my other browser tabs only databricks is zoomed in. Other tabs seem to just be at the de...
- 1 kudos
- 15549 Views
- 3 replies
- 1 kudos
Databricks connect and spark session best practice
Hi all!I am using databricks-connect to develop and test pyspark code pure python (not notebook) files in my local IDE, running on a Databricks cluster. These files are part of a deployment setup with dbx so that they are run as tasks in a workflow.E...
- 15549 Views
- 3 replies
- 1 kudos
- 1 kudos
I personally do something similar by checking an environment variable, the example was for a notebook but should work for a python file as well: import os if not os.environ.get("DATABRICKS_RUNTIME_VERSION"): from databricks.connect import Databr...
- 1 kudos
- 691 Views
- 0 replies
- 0 kudos
Overview of Dario Schiraldi Deutsche Bank Executive
Hello Community, Dario Schiraldi, an executive at Deutsche Bank, is widely recognized for his strategic vision and in-depth expertise in global financial systems. He expert at optimizing financial services and guiding the bank’s international strateg...
- 691 Views
- 0 replies
- 0 kudos
- 2800 Views
- 1 replies
- 1 kudos
Resolved! Accessing views using unitycatalog module
Hi, I'm trying to access to views in my catalog in databricks using unitycatalog open source modulewhen I try to do so I get an error message that indicates this is not possible:cannot be accessed from outside of Databricks Compute Environment due to...
- 2800 Views
- 1 replies
- 1 kudos
- 1 kudos
Here are helpful tips/tricks: Based on the latest Databricks documentation and internal guides, it is currently not possible to grant external access (via open source Unity Catalog APIs or credential vending) to Unity Catalog views (i.e., objects w...
- 1 kudos
- 9397 Views
- 4 replies
- 0 kudos
Unable to create Iceberg tables pointing to data in S3 and run queries against the tables.
I need to to set up Iceberg tables in Databricks environment, but the data resides in an S3 bucket. Then read these tables by running SQL queries.Databricks environment has access to S3. This is done bysetting up the access by mapping the Instance Pr...
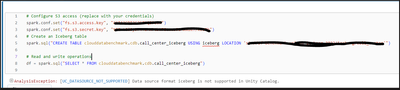
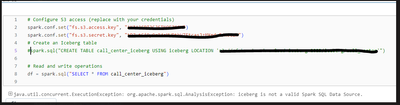
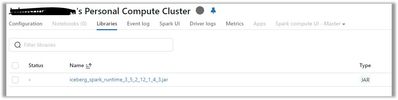
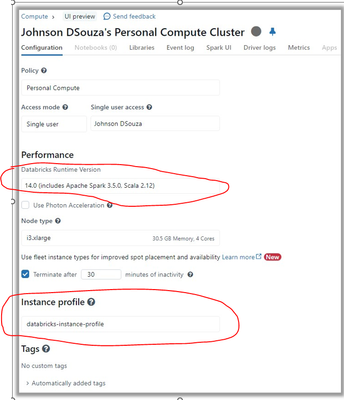
- 9397 Views
- 4 replies
- 0 kudos
- 0 kudos
@JohnsonBDSouza , @PujithaKarnati , @Venkat5 ,There are 3 concepts to use Iceberg format in databricks based on recent updates in DAIS 2025.1) Managed Iceberg tables 2) Foreign Iceberg tables 3) Enabling Iceberg reads on delta tables. Please refer be...
- 0 kudos
- 3735 Views
- 1 replies
- 0 kudos
How to search on empty string on text filter with Lakeview Dashboards
Hi,I have created a lakeview dashboard with a couple of filters and a table. Now I would like to search if a certain filter (column) has an empty string but if I search for ' ' then it goes 'no data'. I am wondering how can I search for an empty stri...


- 3735 Views
- 1 replies
- 0 kudos
- 21482 Views
- 6 replies
- 1 kudos
Installed Library / Module not found through Databricks connect LST 12.2
Hi all,We recently upgraded our databricks compute cluster from runtime version 10.4 LST, to 12.2 LST.After the upgrade one of our python scripts suddenly fails with a module not found error; indicating that our customly created module "xml_parser" i...
- 21482 Views
- 6 replies
- 1 kudos
- 1 kudos
Hi @maartenvr , hi @Debayan ,Are there any updates on this? Have you found a solution, or can the problem at least be narrowed down to specific DBR versions? I am on a cluster with 11.3 LTS and deploy my custom packaged code (named simply 'src') as P...
- 1 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |