- 1631 Views
- 2 replies
- 0 kudos
Delta Live Table Pipeline
I have a pipeline that has given me no problems up until today with the following error message:com.databricks.pipelines.common.errors.deployment.DeploymentException: Failed to launch pipeline cluster 0307-134831-tgq587us: Attempt to launch cluster w...
- 1631 Views
- 2 replies
- 0 kudos
- 0 kudos
@SB93 The error message you are seeing indicates that the cluster failed to launch because the Spark driver was unresponsive, with possible causes being library conflicts, incorrect metastore configuration, or other configuration issues. Given that t...
- 0 kudos
- 11345 Views
- 5 replies
- 1 kudos
Azure Synapse vs Databricks
Hi team,Could you kindly provide your perspective on the cost and performance comparison between Azure Synapse and Databricks SQL Warehouse/serverless, as well as their respective use cases? Thank you.
- 11345 Views
- 5 replies
- 1 kudos
- 1 kudos
@Suncat There hasn't been any major changes for than a year: https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-version-support E.g. I don't believe we will see support for Spark 3.5 at all. At least, apparently it's support...
- 1 kudos
- 1663 Views
- 3 replies
- 0 kudos
Databricks lineage
Hello,I am trying to get the table lineage i.e upstreams and downstreams of all tables in unity catalog into my local database using API calls. I need my db to be up to date, if the lineage is updated in one of the in databricks, i have to update sam...
- 1663 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi @Rachana2,As @Alberto_Umana has mentioned I'd check table_lineage / column_lineage tables, as maintaining a lineage through a bespoke pipeline/tooling may not be a right approach.Can you please explain your use case which explains why you don't wa...
- 0 kudos
- 3792 Views
- 6 replies
- 0 kudos
Resolved! File found with %fs ls but not with spark.read
Code: wikipediaDF = (spark.read .option("HEADER", True) .option("inferSchema", True) .csv("/databricks-datasets/wikipedia-datasets/data-001/pageviews/raw/pageviews_by_second.tsv"))display(bostonDF) Error: Failed to store the result. Try rerunning ...
- 3792 Views
- 6 replies
- 0 kudos
- 0 kudos
I have the exact same issue. Seems like limiting the the display() method works as a temporary solution, but I wonder if there's any long term one. The idea would be to have the possibility of displaying larger datasets within a notebook. How to achi...
- 0 kudos
- 1723 Views
- 1 replies
- 1 kudos
Resolved! Spreadsheet-Like UI for Databricks
We are currently entering data into Excel and then uploading it into Databricks. Is there a built-in spreadsheet-like UI within Databricks that can update data directly in Databricks?
- 1723 Views
- 1 replies
- 1 kudos
- 1 kudos
Hello, @j_h_robinson! Databricks doesn’t have a built-in spreadsheet-like UI for direct data entry or editing. Are you manually uploading the Excel files or using an ODBC driver setup? If you’re doing it manually, you might find this helpful: Connect...
- 1 kudos
- 6708 Views
- 4 replies
- 5 kudos
Resolved! Why is the ipynb format recommended?
In this document, https://docs.databricks.com/aws/en/notebooks/notebook-format,Jupyter (.ipynb) format is recommended.> Select File from the workspace menu, select Notebook format, and choose the format you want. You can choose either Jupyter (.ipynb...
- 6708 Views
- 4 replies
- 5 kudos
- 5 kudos
Hi @Yuki,One other risk that we foresee / encountered recently is how the notebooks will look in your pull requests of external repos (Azure Devops or GitHub). It will be very hard for a pull request reviewer to understand on the code / notebook read...
- 5 kudos
- 2520 Views
- 2 replies
- 0 kudos
Solace to Azure Data Lake Storage
Hi Team,What is the most effective method for performing data ingestion from Solace to Azure Data Lake Storage (ADLS) utilizing an Azure Databricks notebook? Any recommendations would be greatly appreciated.Regards,Phani
- 2520 Views
- 2 replies
- 0 kudos
- 0 kudos
Here is the sample script to invoke the connectorval struct_stream = spark.readStream.format("solace").option("host", "").option("vpn", "").option("username", "").option("password", "").option("queue", "").option("connectRetries", 3).option("reconnec...
- 0 kudos
- 12858 Views
- 20 replies
- 4 kudos
Mounting Data IOException
Hello,I am currently taking a course from Coursera for data science using SQL. For one of our assignments we need to mount some data by running a script that has been provided to us by the class. When I run the script I receive the following error. I...


- 12858 Views
- 20 replies
- 4 kudos
- 4 kudos
Hello all, we came up with a solution: to download the data directly instead of mounting it. The community version is limited, and we don't have access to S3 unless we create our own aws account, load the data there, and then mount our account on dat...
- 4 kudos
- 5885 Views
- 6 replies
- 3 kudos
Unable to install a wheel file which is in my volume to a serverless cluster
I am trying to install a wheel file which is in my volume to a serverless cluster, getting the below error@ken@Retired_mod Note: you may need to restart the kernel using %restart_python or dbutils.library.restartPython() to use updated packages. WARN...
- 5885 Views
- 6 replies
- 3 kudos
- 2829 Views
- 4 replies
- 1 kudos
Resolved! Agents and Inference table errors
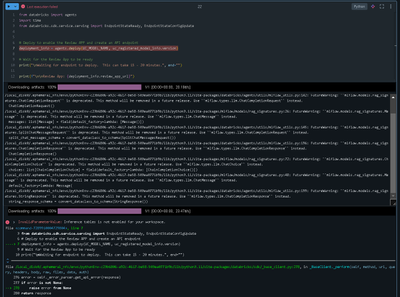
Hi, I'm trying to deploy a rag model from GCP databricks. I've added an external gpt4o endpoint and enabled inference table in settings. But when Im trying to deploy agents I'm still getting the inference table not enabled error. (I've registered the...

- 2829 Views
- 4 replies
- 1 kudos
- 1 kudos
The Model Serving is supported in your region so it can be another problem or limitation.
- 1 kudos
- 1994 Views
- 2 replies
- 0 kudos
Resolved! DatabricksWorkflowTaskGroup
Hello,I recently learned about the DatabricksWorkflowTaskGroup operator for Airflow that allows one to run multiple Notebook tasks on a shared job compute cluster from Airflow.Is a similar feature possible to run multiple non-Notebook tasks from Airf...
- 1994 Views
- 2 replies
- 0 kudos
- 1965 Views
- 2 replies
- 0 kudos
Databricks tasks are not skipping if running tasks using Airflow DatabricksworkflowTaskgroup
Currently we are facing a challenge with below use case:The Airflow DAG has 4 tasks (Task1, Task2, Task3 and Task4) and The dependency is like thisTask 1>> Task2 >> Task3 >> Task4 (All tasks are spark-jar task typesIn Airflow DAG for Task2, there is ...
- 1965 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @anil_reddaboina, Databricks allows you to add control flow logic to tasks based on the success, failure, or completion of their dependencies. This can be achieved using the "Run if" dependencies fiel: https://docs.databricks.com/aws/en/jobs/run-i...
- 0 kudos
- 3490 Views
- 3 replies
- 1 kudos
Databricks JDBC driver multi query in one request.
Can I run multi query in one command using databricks JDBC driver and would databricks execute one query faster then running multi queries in one script?
- 3490 Views
- 3 replies
- 1 kudos
- 1 kudos
Yes, you can run multiple queries in one command using the Databricks JDBC driver.The results will be displayed in separate tables. When you run the multiple queries, they are all still individual queries. Running multiple queries in a script will no...
- 1 kudos
- 2528 Views
- 3 replies
- 0 kudos
Are row filters and column masks supported on foreign catalogs in Azure Databricks Unity Catalog?
In my solution I am planning to bring in an Azure SQL Database to Azure Databricks Unity Catalog as Foreign Catalog. Are table row filters and column masks supported in my scenario ?
- 2528 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi @Arindam19, Yes. Certain operations, including filtering, can be pushed down from Databricks to SQL Server. This is managed by querying the SQL Server directly via a federated connection, allowing SQL Server to handle the filter criteria and retur...
- 0 kudos
- 1107 Views
- 1 replies
- 0 kudos
GCP Databricks Spark Connector for Cassandra - Error: com.typesafe.config.impl.ConfigImpl.newSimple
Hello,I am using Databricks runtime 12.2 with the spark connector - com.datastax.spark:spark-cassandra-connector_2.12:3.3.0as runtime 12.2 comes with spark 3.3.2 and scala 2.12. I encounter an issue with conneciting to cassandra DB using the below co...
- 1107 Views
- 1 replies
- 0 kudos
- 0 kudos
Try using the assembly version of the jar with 12.2. https://mvnrepository.com/artifact/com.datastax.spark/spark-cassandra-connector-assembly If this doesn't work, please paste the full, original stacktrace
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |