- 1015 Views
- 3 replies
- 7 kudos
Resolved! Set a theshold Notification on Job run time.
Hello all, I am brand new to Databricks, so forgive me if this question has been answered before, but what i want to do is set a run time threshold to my Databricks Jobs such that if the job which say normally runs for 30 minutes, runs for over an h...
- 1015 Views
- 3 replies
- 7 kudos
- 7 kudos
Hi @rwalrondNHS, You can set these thresholds and notifications programmatically. They’re part of the normal Jobs definition, not a UI‑only feature. I've just tested this for a sample job and it works perfectly. Under the hood, the run longer than X ...
- 7 kudos
- 17377 Views
- 3 replies
- 0 kudos
Resolved! Access Foreign Catalog using Python in Notebook
Hello - I have a foreign catalog which I can access fine in SQL. However, I can't access it from from python notebook.i.e. this works just fine if I have notebook using a Pro SQL Warehouse%sqlUSE CATALOG <my_foreign_catalog_name>;USE SCHEMA public;S...
- 17377 Views
- 3 replies
- 0 kudos
- 0 kudos
@Debayan , could you please help us how to resolve this issue with steps.
- 0 kudos
- 439 Views
- 1 replies
- 1 kudos
Resolved! doubt
Hey everyone, I am new here and interested to explore this field.I have never worked before on this can you guys guide me on this it will really help me.
- 439 Views
- 1 replies
- 1 kudos
- 1 kudos
Hey, welcome aboard.You can get started with the Beginner Guides on how to start - https://community.databricks.com/t5/get-started-guides/tkb-p/Get-Started-Guides.Post this you may choose a Learning Path based on your preference or profession and get...
- 1 kudos
- 7322 Views
- 11 replies
- 0 kudos
Databricks apps - Volumes and Workspace - FileNotFound issues
I have a Databricks App I need to integrate with volumes using local python os functions. I've setup a simple test: def __init__(self, config: ObjectStoreConfig): self.config = config # Ensure our required paths are created ...
- 7322 Views
- 11 replies
- 0 kudos
- 0 kudos
These are the permissions needed for the app service principal:Catalog: Use CatalogSchema: Use Schema Volume: Read / WriteTo actually be able to read/write in the volume I had to use the Python databricks-sdk. Performing "normal" file system operatio...
- 0 kudos
- 2118 Views
- 3 replies
- 3 kudos
Databricks community group in Kerala
Calling All Data Enthusiasts in Kerala! Hey everyone,I'm excited about the idea of launching a Databricks Community Group here in Kerala! This group would be a hub for learning, sharing knowledge, and networking among data enthusiasts, analysts, a...
- 2118 Views
- 3 replies
- 3 kudos
- 3 kudos
Hi @AswinGovindan77 , Do you have an estimate of how many enthusiasts will be joining you? If you provide a rough number, we can create a group for you on Community!
- 3 kudos
- 565 Views
- 1 replies
- 0 kudos
Resolved! DQX Compatibility
Hi all,Does anyone know if DQX (Databricks Labs) is compatible with Microsoft Fabric Spark notebooks? It would be useful to know this, so that we can use it on Fabric-based projects as well.Thanks!
- 565 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @d_a_n, No, DQX isn’t supported on Microsoft Fabric Spark notebooks. DQX is a Databricks Labs framework that’s designed and documented to run on Databricks workspaces and Databricks clusters only (see the official installation prerequisites). In a...
- 0 kudos
- 4285 Views
- 11 replies
- 4 kudos
Resolved! Azure Databricks session expiry Issue
I frequently encounter a session-expired issue while using Databricks within 2 minutes, and this has been happening for two days. Are there any fixes or suggestions?
- 4285 Views
- 11 replies
- 4 kudos
- 4 kudos
Hi @Prathy @prasadv @joonkim4078 @Krissy_ , Thank you for your patience while we investigated this issue. We flagged this to our teams internally, and the team has deployed a fix, and based on our checks, the behaviour should now be back to normal. T...
- 4 kudos
- 848 Views
- 1 replies
- 2 kudos
Resolved! Learn scala using Databricks free edition
Hi, I want to run and learn spark scala using databricks free edition. It looks there was access in community edition but now in databricks free edition serverless does not scala . Please confirm if understanding is correct and possible alternative i...
- 848 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi @kpavan2004, You are right. The free edition doesn't support R or Scala. You can see a list of limitations here. If this answer resolves your question, could you mark it as “Accept as Solution”? That helps other users quickly find the correct fix...
- 2 kudos
- 1098 Views
- 2 replies
- 1 kudos
Serverless Compute Idle Timeout Time
I want to know what is the idle timeout for Databricks Serverless Compute. Can anyone Databricks document where it specifies the idle timeout time details.
- 1098 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @AJ270990 , I did some digging and I have some helpful tips to guide you. This is one of those areas where the answer is “it depends,” based on which flavor of serverless compute you’re using. Let’s break it down so it’s easy to reason about. Firs...
- 1 kudos
- 1557 Views
- 3 replies
- 1 kudos
Resolved! Guidance on Databricks Specializations and Migration Accelerators for Partner Tier Progression
Hi everyone,We are currently working toward progressing our tier in the Databricks Partner Network and had a quick question regarding the tier requirements.Could someone clarify:• What is the process for partners to achieve Databricks Specializations...
- 1557 Views
- 3 replies
- 1 kudos
- 1 kudos
Hi @vamsi_simbus, Thanks for the questions and for growing your Databricks practice as you move beyond Bronze in the Databricks Partner Network. At a high level, each Brickbuilder Specialisation (industry or product) has a clear checklist that typica...
- 1 kudos
- 4057 Views
- 4 replies
- 12 kudos
Resolved! Blueprint: Entity Resolution(Dedup & Golden Records)on Databricks — blocking, fuzzy scoring, MLflow
Hi Databricks Community I’m working on designing a practical Entity Resolution / Deduplication framework on Databricks, and I wanted to share a high‑level blueprint and learn from others who’ve tackled similar problems at scale.The use case is fairly...
- 4057 Views
- 4 replies
- 12 kudos
- 12 kudos
Hi @Mridu, Rather than building everything greenfield, you can lean heavily on Databricks’ existing Entity Resolution Solution Accelerators (Customer ER, Product Matching, Public Sector ER) as a starting point and then adapt their patterns to your bl...
- 12 kudos
- 3188 Views
- 2 replies
- 0 kudos
Databricks workspace in failed state
Hi Community,I had my Databricks workspace up and running and it was managed through terraform, and encryption was enabled through cmk, there were some updation in the code, so I put terraform plan, one of the key changes(replace) it showed me was"az...
- 3188 Views
- 2 replies
- 0 kudos
- 1272 Views
- 5 replies
- 12 kudos
Resolved! LLM based Replies to community posts
Hello Everyone,I’ve been in the community for a few weeks and really enjoy reading the problems and production-focused solutions shared here.Recently, I’ve noticed some replies(solutions) that look quite verbose and seem like they might be generated ...
- 1272 Views
- 5 replies
- 12 kudos
- 12 kudos
Hey guys, I appreciate you bringing this up. We do have an AI usage policy in our Code of Conduct that I recently asked Legal to update:Use of AI Tools: AI tools may be used to assist with formatting, clarity, and organization, or to draft ideas that...
- 12 kudos
- 634 Views
- 4 replies
- 0 kudos
Attempting to load a JSON file fails due to schema issue (Free Edition)
Hello,I created a Volume named 'test_volume' under catalog:workspace and schema:default.Then I uploaded a file named user_0.json into test_volume (fake data, of course):Now I want to load that file into a data frame.With Python in a notebook:With SQL...

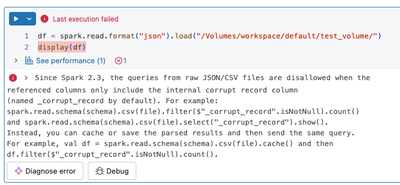
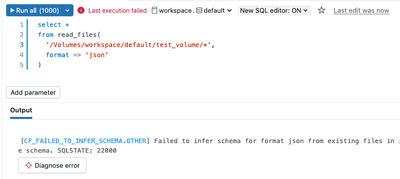
- 634 Views
- 4 replies
- 0 kudos
- 0 kudos
The AnalysisException you're seeing in the Databricks Community Edition is almost always caused by a mismatch between the JSON file format and Spark’s default reader.By default, Spark expects JSON Lines (one JSON object per line). If your file is a s...
- 0 kudos
- 1746 Views
- 5 replies
- 3 kudos
Resolved! “Provisioned throughput is not enabled for this workspace”
Hello,when I try setting up a model with provisioned throughput, the deployment fails with the message “Provisioned throughput is not enabled for this workspace.”. It doesn’t work for databricks-hosted models nor for 3rd party models from the marketp...

- 1746 Views
- 5 replies
- 3 kudos
- 3 kudos
Hello Steve,thank you for the broad reply. Just FYI I had to reach to to Azure support and DB support to fix it.FYI 2: Serverless compute was enabled, `Enforce data processing within workspace Geography for Designated Services was disabled`, pay-per-...
- 3 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |