Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Machine Learning
Dive into the world of machine learning on the Databricks platform. Explore discussions on algorithms, model training, deployment, and more. Connect with ML enthusiasts and experts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Machine Learning
- Re: `collect()`ing Large Datasets in R
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
`collect()`ing Large Datasets in R
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-31-2022 11:37 AM
Background: I'm working on a pilot project to assess the pros and cons of using DataBricks to train models using R. I am using a dataset that occupies about 5.7GB of memory when loaded into a pandas dataframe. The data are stored in a delta table in Unity Catalog.
Problem: I can `collect()` the data using python (pyspark) in about 2 minutes. However, when I tried to use sparklyr to collect the same dataset in R the command was still running after ~2.5 days. I can't load the dataset into DBFS first because we need stricter data-access controls than DBFS will allow. Below are screenshots of the cells that I ran to `collect()` the data in Python and R.
I'm hoping that I'm just missing something about how sparklyr loads data.
Here is the cell that loads the data using pyspark, you can see that it took 2.04 minutes to complete:
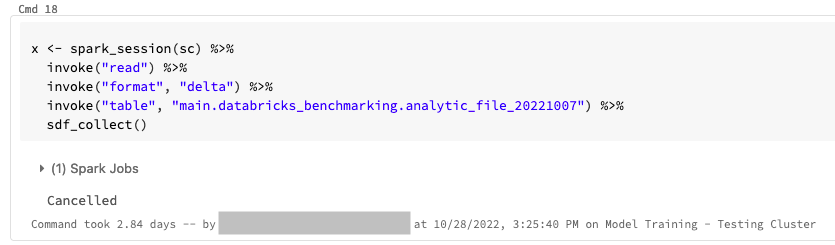
Here is the cell that loads the data using sparklyr, you can see that I cancelled it after 2.84 days:

I also tried using the `sparklyr::spark_read_table` function but I got an error that `Table or view not found: main.databricks_...` which I think must be because the table is in a metastore managed by Unity Catalog.
Environment Info:
Databricks Runtime: 10.4 LTS
Driver Node Size: 140GB memory and 20 cores
Worker Nodes: 1 worker node with 56GB of memory and 8 cores.
R libraries installed: arrow, sparklyr, SparkR, dplyr
Labels:


6 REPLIES 6
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-31-2022 01:52 PM
If you have 5GB of data, you don't need spark. Just use your laptop. Spark is for scale and won't out perform well on small data sets because of all the overhead distributed requires.
Also, don't name a pandas dataframe df_spark_. Just name it something_pdf.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-01-2022 09:06 AM
Yes, the name of the dataframe was a little sloppy since it's a Pandas dataframe. Although about the scale, all of the machine learning documentation and sample ML notebooks for DataBricks that I have seen load the dataset into memory on the driver node. And if I remember right the guidance I read from DataBricks was to avoid using a spark-compatible training algorithm as long as your data could fit into memory on the driver node. So while a 5GB dataset could fit on my laptop I'm a little worried that if I can't load 5GB from a Delta Table onto the driver node I almost certainly won't be able to load a larger dataset that wouldn't fit on my laptop, say 50 GB. Plus the dataset contains protected health information which I'm not permitted to download onto my laptop anyway.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-31-2022 11:18 PM
Have you tried performing `collect()` with SparkR? That would require loading the data as a SparkR DataFrame.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-01-2022 09:00 AM
That is a good suggestion, and something I probably should have tried already. Although when I use
SparkR::collectI get a JVM error:
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2023 11:18 PM
Hi @Max Taggart
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-13-2024 03:17 AM
@acsmaggart Please try using collect_larger() to collect the larger dataset. This should work. Please refer to the following document for more info on the library.
https://medium.com/@NotZacDavies/collecting-large-results-with-sparklyr-8256a0370ec6
On Medium, anyone can share insightful perspectives, useful knowledge, and life wisdom with the world.
Announcements





{kind=link}
{kind=link}
Related Content
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering
- Is Databricks AI/BI Genie worth it if we already have Power BI or Tableau? in Data Engineering
- Config-Driven Data Harmonization Framework in Databricks (Silver → Harmonized_Silver) in Data Engineering
- How to use multi-threading and batch inserts for large UPSERT to PostgreSQL from Databricks? in Data Engineering
- Unity Catalog design in single workspace: dev/prod catalogs and schemas for projects — should we add in Administration & Architecture