- 11602 Views
- 6 replies
- 3 kudos
`collect()`ing Large Datasets in R
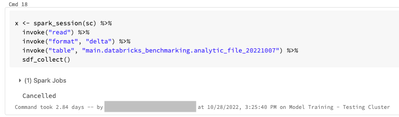
Background: I'm working on a pilot project to assess the pros and cons of using DataBricks to train models using R. I am using a dataset that occupies about 5.7GB of memory when loaded into a pandas dataframe. The data are stored in a delta table in ...

- 11602 Views
- 6 replies
- 3 kudos
- 3 kudos
@acsmaggart Please try using collect_larger() to collect the larger dataset. This should work. Please refer to the following document for more info on the library.https://medium.com/@NotZacDavies/collecting-large-results-with-sparklyr-8256a0370ec6
- 3 kudos
- 4747 Views
- 4 replies
- 4 kudos
- 4747 Views
- 4 replies
- 4 kudos
- 4 kudos
Data science is a multidisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from data. It encompasses the entire data lifecycle, from data acquisition to data exploration, modeling, and...
- 4 kudos
- 2303 Views
- 1 replies
- 9 kudos
***Understanding Databricks Machine Learning Workspace - 1***Databricks Machine Learning helps you simplify and standardize your ML development proce...
***Understanding Databricks Machine Learning Workspace - 1***Databricks Machine Learning helps you simplify and standardize your ML development processes. It is helpful to :Train models either manually or with AutoML.Track training parameters and mo...
- 2303 Views
- 1 replies
- 9 kudos
- 6852 Views
- 2 replies
- 1 kudos
Resolved! Study material ML associate certification
Hi, is there an officially recommended book for the machine learning associate/professional certification? Or any sort of study guide or even third party course? I really struggle to find some study material for this activity.
- 6852 Views
- 2 replies
- 1 kudos
- 1 kudos
hello, to get an overview you may find out ML certification course from data bricks academy and refer the related concepts
- 1 kudos
- 32182 Views
- 4 replies
- 7 kudos
The Python process exited with exit code 137 (SIGKILL: Killed). This may have been caused by an OOM error. Check your command's memory usage.
I am running a hugging face model on a GPU cluster (g4dn.xlarge, 16GB Memory, 4 cores). I run the same model in four different notebooks with different data sources. I created a workflow to run one model after the other. These notebooks run fine indi...
- 32182 Views
- 4 replies
- 7 kudos
- 7 kudos
You might accumulate gradients when running your Huggingface model, which typically leads to out-of-memory errors after some iterations. If you use it for inference only, dowith torch.no_grad(): # The code where you apply the model
- 7 kudos
- 1951 Views
- 1 replies
- 0 kudos
How far does model size and lag impact distributed inference ?
Hello !I was wondering how impactful a model's size of inference lag was in a distributed manner.With tools like Pandas Iterator UDFs or mlflow.pyfunc.spark_udf() we can make it so models are loaded only once per worker, so I would tend to say that m...
- 1951 Views
- 1 replies
- 0 kudos
- 0 kudos
Your assumption that minimizing inference lag is more important than minimizing the size of the model in a distributed setting is generally correct.In a distributed environment, models are typically loaded once per worker, as you mentioned, which mea...
- 0 kudos
- 4980 Views
- 3 replies
- 4 kudos
Are UDFs necessary for applying models from ML libraries at scale ?
Hello,I recently finished the "scalable machine learning with apache spark" course and saw that SKLearn models could be applied faster in a distributed manner when used in pandas UDFs or with mapInPandas() method. Spark MLlib models don't need this k...
- 4980 Views
- 3 replies
- 4 kudos
- 4 kudos
MlLib is in the maintenance model and udf is not used by creating model in most cases
- 4 kudos
- 5408 Views
- 1 replies
- 4 kudos
Databricks MLOps Best Practices
Where to find the best practices on MLOps on DatabricksWe recommend checking out the Big Book of MLOps for detailed guidance on MLOps best practices on Databricks including reference architectures.For a deep dive on the Databricks Feature store, we r...
- 5408 Views
- 1 replies
- 4 kudos
- 4 kudos
you can check here https://docs.databricks.com/machine-learning/mlops/mlops-workflow.html
- 4 kudos
- 7778 Views
- 7 replies
- 13 kudos
Resolved! Getting started with Databricks Machine Learning
hello all,I am fairly new to Databricks technologies and I have taken the Lakehouse Fundamentals course but I am interested in Machine Learning technologies. I will appreciate any help with materials and curated free study paths and packs that can he...
- 7778 Views
- 7 replies
- 13 kudos
- 13 kudos
https://pages.databricks.com/rs/094-YMS-629/images/LearningSpark2.0.pdf is a free book and has some machine learning examples. The way I learned was mostly from the docs, which are good and have good coding examples.
- 13 kudos
- 3497 Views
- 3 replies
- 10 kudos
I am Avi, a Solutions Architect at Databricks. We have built an application to demonstrate how AI-capabilities could be easily integrated to deliver n...
I am Avi, a Solutions Architect at Databricks. We have built an application to demonstrate how AI-capabilities could be easily integrated to deliver novel user experiences. The application allows users to submit images and text, and uses these inputs...
- 3497 Views
- 3 replies
- 10 kudos
- 10 kudos
Hi @Avinash Sooriyarachchi Thanks for sharing it.
- 10 kudos
- 1899 Views
- 0 replies
- 5 kudos
youtu.be
I'm Avi, a Solutions Architect at Databricks working at the intersection of Data Engineering and Machine Learning.Streaming data processing has moved from niche to mainstream, and deploying machine learning models in such data streams opens up a mult...
- 1899 Views
- 0 replies
- 5 kudos
- 4983 Views
- 7 replies
- 6 kudos
Why this Databricks ML code gets stuck?
I could not paste the code here because of the some word not allowed, so I have to paste it elsewhere.Below is OK:https://justpaste.it/8xcr9But below gets stuck:https://justpaste.it/8nydtand it keeps looping and running...
- 4983 Views
- 7 replies
- 6 kudos
- 6 kudos
Hey @THIAM HUAT TAN Hope all is well! Just wanted to check in if you were able to resolve your issue, and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you....
- 6 kudos
- 5454 Views
- 4 replies
- 1 kudos
Resolved! ML Practioner | ml 09 - automl notebook | error on importing databricks.automl
executing the following code...from databricks import automlsummary = automl.regress(train_df, target_col="price", primary_metric="rmse", timeout_minutes=5, max_trials=10)generates the error...ImportError: cannot import name 'automl' from 'databricks...
- 5454 Views
- 4 replies
- 1 kudos
- 1 kudos
I'm happy to see a particularly subject.
- 1 kudos
- 6601 Views
- 3 replies
- 1 kudos
How to track features used and filters in MLFlow?
Hello everyone,We are experimenting with several approaches in a Machine Learning project ( binary classification), and we would like to keep track of those using MLFlow. We are using the feature store to build, store, and retrieve the features, and ...
- 6601 Views
- 3 replies
- 1 kudos
- 1 kudos
Thanks for the information, I will try to figure it out for more. Keep sharing such informative post keep suggesting such post.
- 1 kudos
- 6074 Views
- 4 replies
- 2 kudos
Resolved! Cluster setup for ML work for Pandas in Spark, and vanilla Python.
My setup:Worker type: Standard_D32d_v4, 128 GB Memory, 32 Cores, Min Workers: 2, Max Workers: 8Driver type: Standard_D32ds_v4, 128 GB Memory, 32 CoresDatabricks Runtime Version: 10.2 ML (includes Apache Spark 3.2.0, Scala 2.12)I ran a snowflake quer...
- 6074 Views
- 4 replies
- 2 kudos
- 2 kudos
Hey there @Vivek Ranjan Checking in. If Joseph's answer helped, would you let us know and mark the answer as best? It would be really helpful for the other members to find the solution more quickly.Thanks!
- 2 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
46 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
DevOps
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
63 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
30 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »