- 15363 Views
- 6 replies
- 3 kudos
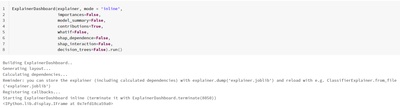
Databricks Notebook Rendering Issue: IPython.lib.display.IFrame
Similar issue here: https://stackoverflow.com/questions/71336374/randomforestclassifier-explainer-dashboard-output-in-databricks-notebook-is-notActual output – Databricks Notebook Expected Output – Jupyter Notebook Reproducible Code Example#pip insta...
- 15363 Views
- 6 replies
- 3 kudos
- 3 kudos
Hi Abhishek, I followed your steps, I am having in identifying the dashboard link. How do I figure out the first two words dbc-dp- for my cluster?
- 3 kudos
- 6443 Views
- 0 replies
- 1 kudos
Failure in Databricks Serving endpoint <build log says Pip failed due to conflicting dependency.>
Hello All,We are trying to deploy some models using Databricks Serving endpoint, But while deploying the artifact created during experiment run the serving endpoint build log says Pip failed due to conflicting dependency.The model is logged in experi...
- 6443 Views
- 0 replies
- 1 kudos
- 2473 Views
- 1 replies
- 7 kudos
Train machine learning models: How can I take my ML lifecycle from experimentation to production?
Note: the following guide is primarily for Python users. For other languages, please view the following links: • Table batch reads and writes • Create a table in SQL • Visualizing data with DBSQLThis step-by-step guide will get your data...




- 2473 Views
- 1 replies
- 7 kudos
- 7 kudos
I got good knowledge by your post . It is very clear . Thank you . Keep sharing like this posts .It will be helpful
- 7 kudos
- 2319 Views
- 1 replies
- 0 kudos
Weekly Release Notes Recap Here’s a quick recap of the latest release notes updates from the past one week. Databricks platform release notesJanuary 1...
Weekly Release Notes RecapHere’s a quick recap of the latest release notes updates from the past one week.Databricks platform release notesJanuary 13 - 19, 2023Cluster policies now support limiting the max number of clusters per userYou can now use c...
- 2319 Views
- 1 replies
- 0 kudos
- 4003 Views
- 2 replies
- 0 kudos
I need to access the json file in the github repo from the databricks notebookI have a repo integrated with Databricks workspace. When I run %sh pwd ...
I need to access the json file in the github repo from the databricks notebookI have a repo integrated with Databricks workspace. When I run %sh pwd it returns this path /Workspace/Repos/chris@myemail/Repo/folder/test.json. I'm not able to access the...
- 4003 Views
- 2 replies
- 0 kudos
- 19223 Views
- 7 replies
- 16 kudos
Resolved! Way of using pymc.model_to_graphviz into a Databricks notebook
Hi everybody,I created a simple bayesian model using the pymc library in Python. I would like to graphically represent my model using the pymc.model_to_graphviz(model=model) method.However, it seems it does not work within a databrcks notebook, even ...
- 19223 Views
- 7 replies
- 16 kudos
- 7504 Views
- 3 replies
- 3 kudos
Resolved! ML Practioner | ML 11 - XGBoost notebook | cannot import keras.applications.resnet50
the following code...from sparkdl.xgboost import XgboostRegressorfrom pyspark.ml import Pipelineparams = {"n_estimators": 100, "learning_rate": 0.1, "max_depth": 4, "random_state": 42, "missing": 0}xgboost = XgboostRegressor(**params)pipeline = Pipel...
- 7504 Views
- 3 replies
- 3 kudos
- 3 kudos
You need to choose the runtime for ML instead of the standard.
- 3 kudos
- 3013 Views
- 2 replies
- 4 kudos
Resolved! Azure Data Factory: allocate resources per Notebook
I'm using Azure Data Factory to create pipeline of Databricks notebooks, something like this:[Notebook 1 - data pre-processing ] -> [Notebook 2 - model training ] -> [Notebook 3 - performance evaluation].Can I write some config file, that would allow...
- 3013 Views
- 2 replies
- 4 kudos
- 4 kudos
I understand that, in your case, auto-scaling will take too much time.The simplest option is to use a different cluster for another notebook (and be sure that the previous cluster is terminated instantly).Another option is to use REST API 2.0/cluster...
- 4 kudos
- 4233 Views
- 2 replies
- 3 kudos
Resolved! ML Practioner | ML 10 - Feature Store notebook | feature_store import error
the following code...from pyspark.sql.functions import monotonically_increasing_id, lit, expr, randimport uuidfrom databricks import feature_storefrom pyspark.sql.types import StringType, DoubleTypefrom databricks.feature_store import feature_table, ...
- 4233 Views
- 2 replies
- 3 kudos
- 3 kudos
Hope that was an easy fix - @Tobias Cortese ! Thanks for marking the "best answer"!
- 3 kudos
- 5955 Views
- 1 replies
- 2 kudos
Resolved! How to deploy or create mlflow model as docker image with REST api endpoint within databricks?
Is it possible to create mlflow model as a docker image with REST api endpoint and use it for inferencing within databricks or hosting the image in azure container instances?
- 5955 Views
- 1 replies
- 2 kudos
- 2 kudos
@Vijeth Moudgalya , Hey there, we are definitely interested in making model serving easier and simpler on Databricks. There are some useful product features coming down the line - contact me at bilal dot aslam at databricks dot com if you are intere...
- 2 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
46 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
DevOps
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
63 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
30 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »