- 16457 Views
- 7 replies
- 3 kudos
Resolved! How to PREVENT mlflow's autologging from logging ALL runs?
I am logging runs from jupyter notebook. the cells which has `mlflow.sklearn.autlog()` behaves as expected. but, the cells which has .fit() method being called on sklearn's estimators are also being logged as runs without explicitly mentioning `mlflo...
- 16457 Views
- 7 replies
- 3 kudos
- 3 kudos
Good question—mlflow autologging can easily capture more runs than expected if not configured properly. Managing it carefully improves experiment tracking. Similar control and optimization are important in bussid mod workflows, where users fine-tune ...
- 3 kudos
- 4665 Views
- 3 replies
- 5 kudos
Deploy a ML model, trained and registered in Databricks to AKS
Hi,I can train, registered a ML Model in my Datbricks Workspace.Then, to deploy it on AKS, I need to register the model in Azure ML, and then, deploy to AKS.Is it possible to skip the Azure ML step?I would like to deploy directly into my AKS instance...
- 4665 Views
- 3 replies
- 5 kudos
- 5 kudos
Is it still the case, can't we serve the model in Databricks. I am new to this, so I am just wondering the capabilities.
- 5 kudos
- 7210 Views
- 3 replies
- 2 kudos
How to proper use Databricks MLFlow Managed tracker/register with Databricks Workflow
Hey.I'm building a DevOps/MLOps pipeline to train/register simple scikit learn model.I created a simple Databricks Workflow to execute training and register task on specific .git branch. (Workflow is setup with Databricks Repo on specifc branch, with...
- 7210 Views
- 3 replies
- 2 kudos
- 2 kudos
I had same issue while trying to call notebook from workflow. I was able to do what you did. But it needs new experiment name for each run, so I had to do this:# Set the experimentexperiment_name = f"/Workspace/MLOps/{env}/experiment/{experiment}_{ti...
- 2 kudos
- 4068 Views
- 1 replies
- 2 kudos
Run mlflow project from a Job.
Hey Guys, I'm trying to make automated process to run ML training sessions using mlflow and databricks jobs.While developing the model on my local machine using IDE, When finished I have a template notebook that get as parameters the mlflow project p...

- 4068 Views
- 1 replies
- 2 kudos
- 2 kudos
Hi,Were you able to figure out this one? I have same issue trying to call training notebook from workflow. Each run needs a new experiment name which I can do but then it creates a new experiment ID/name for each workflow run. Where as when you run f...
- 2 kudos
- 5192 Views
- 2 replies
- 1 kudos
What is the best practice for applying MLFlow to clustering algorithms?
What is the best practice for applying MLFlow to clustering algorithms? What are the kinds of metrics customers track?
- 5192 Views
- 2 replies
- 1 kudos
- 1 kudos
Good question! I'll divide my suggestions into 2 parts:(1) In terms of MLflow Tracking, clustering is pretty similar to other ML workflows, so not much changes.(2) In terms of specific parameters, metrics, etc. to track, clustering is very different...
- 1 kudos
- 8859 Views
- 6 replies
- 7 kudos
How to save model produce by distributed training?
I am trying to save model after distributed training via the following codeimport sys from spark_tensorflow_distributor import MirroredStrategyRunner import mlflow.keras mlflow.keras.autolog() mlflow.log_param("learning_rate", 0.001) import...
- 8859 Views
- 6 replies
- 7 kudos
- 7 kudos
I think I finally worked this out.Here is the extra code to save out the model only once and from the 1st node:context = pyspark.BarrierTaskContext.get() if context.partitionId() == 0: mlflow.keras.log_model(model, "mymodel")
- 7 kudos
- 3735 Views
- 2 replies
- 5 kudos
How can I view the storage space taken by a registered model using MLFlow?
The information viewed about the registered models on the Models tab is very minimal. Just showing the tags we pass in and version information. How can I get more details about the model such as the size on disk?
- 3735 Views
- 2 replies
- 5 kudos
- 5 kudos
Hi,I have used the MLFlow client, but I am not sure where to find the size of the model image.The response to client.search_registered_models() I am getting is the following:<RegisteredModel: aliases={}, creation_timestamp=17061..., description='', l...
- 5 kudos
- 14964 Views
- 3 replies
- 5 kudos
Why are my MLflow results not showing up in the Experiment UI view?
The issue:None of my MLflow experiment results show up in the Experiment UI. Context:I encountered this issue recently, despite having successfully used the MLFlow UI for the past few weeks.Note: I can still access the experiment runs in a notebook, ...
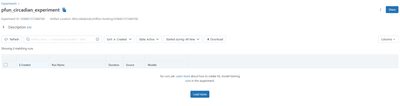
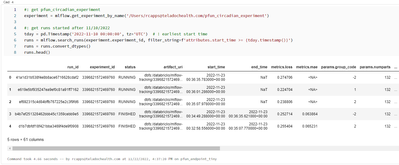
- 14964 Views
- 3 replies
- 5 kudos
- 5 kudos
Hi @Robbie, Thank you for posting your question in the Databricks community. Ensure that you are logging runs correctly using mlflow.start_run(), and that all relevant metrics and artifacts are being logged with the correct parameters. Please check.
- 5 kudos
- 7119 Views
- 3 replies
- 5 kudos
Resolved! Difference between MLFlow recipes and projects?
MLFlow projects are described asAn MLflow Project is a format for packaging data science code in a reusable and reproducible way, based primarily on conventions. In addition, the Projects component includes an API and command-line tools for running p...
- 7119 Views
- 3 replies
- 5 kudos
- 5 kudos
Thanks for the answer @Priyadarshini G . Although a project has a pre-defined folder structure and standard files, it also "... includes an API and command-line tools for running projects, making it possible to chain together projects into workflows...
- 5 kudos
- 4603 Views
- 2 replies
- 4 kudos
Runtime error using MLFlow and Spark on databricks
Here is some model I created:class SomeModel(mlflow.pyfunc.PythonModel): def predict(self, context, input): # do fancy ML stuff # log results pandas_df = pd.DataFrame(...insert predictions here...) spark_df = spark...
- 4603 Views
- 2 replies
- 4 kudos
- 4 kudos
Any updates on this? I am running into the same issue@Patrick Tawil were you able to solve this problem? If so, do you mind sharing?
- 4 kudos
- 13340 Views
- 5 replies
- 2 kudos
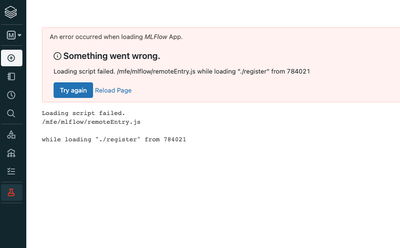
Resolved! mlflow down in workspace?
Mlflow started failing all of a sudden for no reason when logged in databricks community edition:Any idea why this is happening or is there a way to restart the mlflow server?
- 13340 Views
- 5 replies
- 2 kudos
- 2 kudos
Hi @Zheng Han Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers you...
- 2 kudos
- 3576 Views
- 2 replies
- 1 kudos
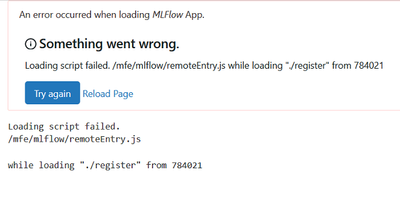
Mlflow :loading script failed !!
I am using mlflow to track experimentation with databricks but todaty i tried to access my experimetations in dtabricks and i face the error .
- 3576 Views
- 2 replies
- 1 kudos
- 1 kudos
I didn't manage to solve the error . I guess it is related to databricks community cloud because I tested with another account and it all the same.
- 1 kudos
- 5981 Views
- 2 replies
- 0 kudos
Logging spark pipeline model using mlflow spark , leads to PythonSecurityException
Hello,I am currently using a simple pyspark pipeline to transform my training data, fit model and log the model using mlflow.spark. But I get this following error (with mlflow.sklearn it works perfectly fine but due to size of my data I need to use p...
- 5981 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi @Saeid Hedayati Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answer...
- 0 kudos
- 12564 Views
- 2 replies
- 0 kudos
MLFlow Remote model registry connection is not working in Databricks
Dear community,I am having multiple Databricks workspaces in my azure subscription, and I have one central workspace. I want to use the central workspace for model registry and experiments tracking from the multiple other workspaces.So, If I am train...
- 12564 Views
- 2 replies
- 0 kudos
- 0 kudos
@Kumar Shanu :The error you are seeing (API request to endpoint /api/2.0/mlflow/runs/create failed with error code 404 != 200) suggests that the API endpoint you are trying to access is not found. This could be due to several reasons, such as incorr...
- 0 kudos
- 2998 Views
- 1 replies
- 1 kudos
Unable to call logged ML model from a different notebook when using Spark ML
Hi, I am a R user and I am experimenting to build an ml model with R and with spark flavoured algorithms in Databricks. However, I am struggling to call a model that is logged as part of the experiment from a different notebook when I use spark flavo...
- 2998 Views
- 1 replies
- 1 kudos
- 1 kudos
@Dip Kundu :It seems like the error you are facing is related to sparklyr, which is used to interact with Apache Spark from R, and not directly related to mlflow. The error message suggests that an object could not be found, but it's not clear which...
- 1 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
44 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
DevOps
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
61 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
28 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »